Nach der Vorstellung habe ich natürlich weiter an Pipes gearbeitet. Es gab einige Bugs zu fixen (z.B. konnte man sich nicht mit Chrome einloggen) und Kleinigkeiten zu verbessern (z.B. direkt nach dem Login im Editor zu speichern, ohne auf den zweiten Klick zu warten). Es gibt jetzt aber auch ein paar neue Blocks.
Mit dem Sort-Block können Feeds sortiert werden - z.B. nach dem Datum der Einträge, aber das Sortierfeld lässt sich aussuchen. Der Truncate-Block begrenzt die Länge des Feeds.
Drei andere neue Block ermöglichen Webscraping: Der Download-Block lädt eine Webseite herunter (ohne wie der Feed-Block nach einem RSS-Feed zu suchen), der Extract-Block kann dann mittels CSS-Selektoren oder XPath Elemente aus der Seite herausnehmen, und diese gibt man dann am besten dem Feedbuilder-Block und füllt so einen richtigen RSS-Feed mit Titel, Inhalt und Links. Feeds so zu erstellen und eventuell zu bearbeiten passt in meinen Augen sehr gut in das Modell von Pipes.
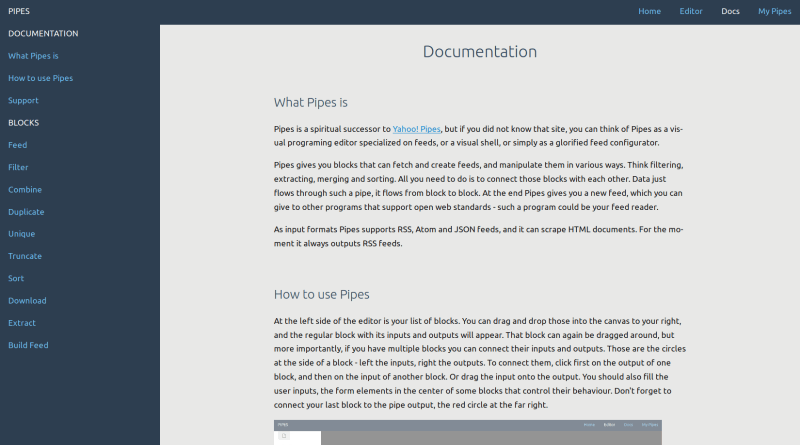
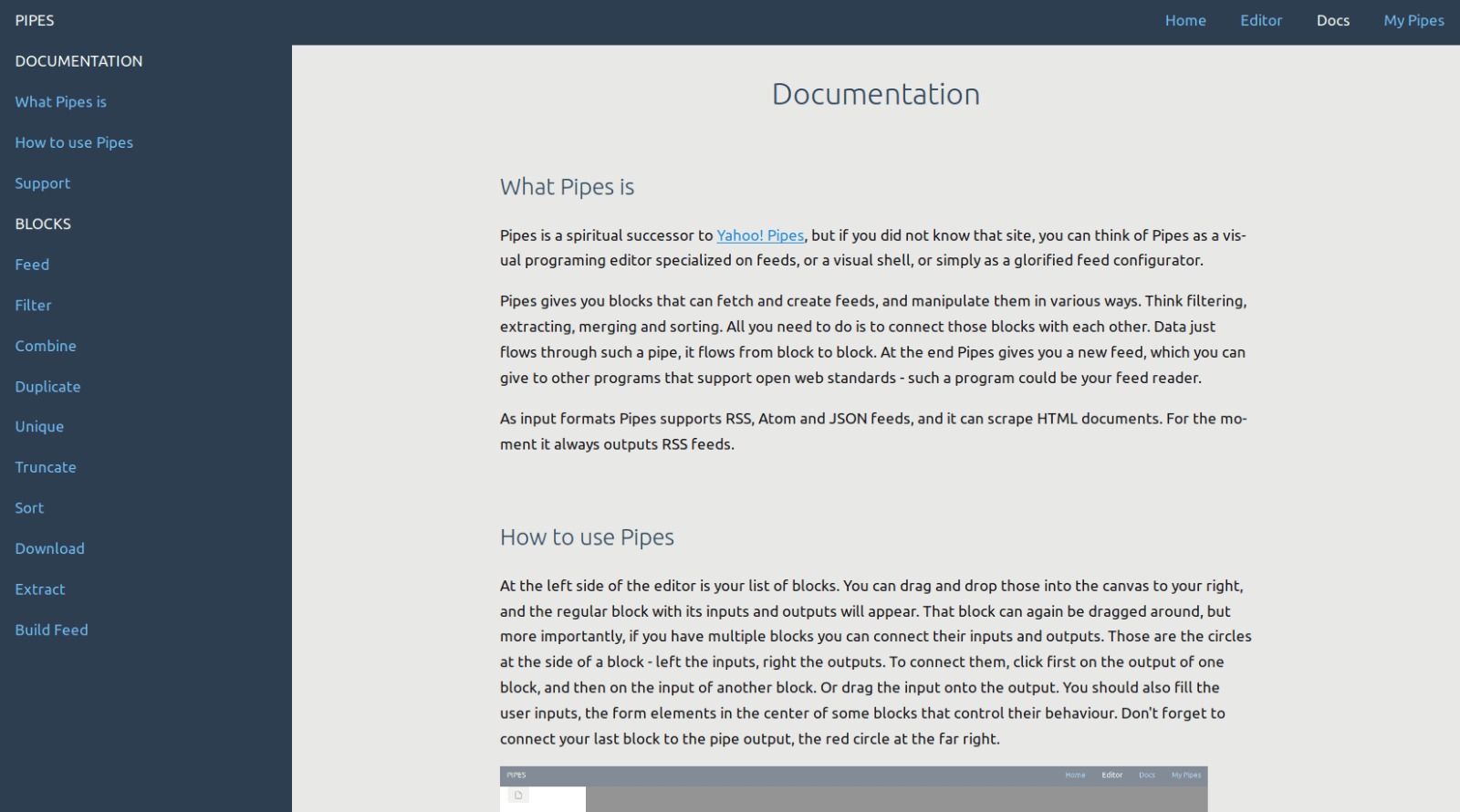
Fast noch wichtiger war mir aber, die Dokumentation online zu haben. Es gab dann doch einige Nachfragen und Unklarheiten. Die Docs erklären nun erstmal, was Pipes ist - und zeigen auch in einem sehr kurzen Video, wie der Editor funktioniert. Außerdem wird jeder Block erklärt, und in einem Beispiel gezeigt was man mit ihm machen kann.
Dank Matthias Antwort auf Twitter weiß ich nun auch, dass ich das mit Sphinx hätte bauen können. Das kam diesmal zu spät, aber er hatte vollkommen recht: Genau solche Sphinx-Dokumentation hatte ich als Vorbild.


onli blogging am : Mehr Erklärungen für Pipes per Blog!
Vorschau anzeigen