Angestoßen von dieser
Diskussion über die Performance des Bayes-Plugins schreibe ich hier mal die theoretische Grundlage des Plugins und damit auch eines generischen Bayes-Spamfilters auf, damit man sich bei einer eventuellen Überarbeitung hierdran orientieren kann.
Bayes-Formel
Das
Bayes-Theorem wurde entdeckt, verworfen und schließlich wiederentdeckt. Ich glaube, die mathematischen Einwände gegen die Formel finden sich manchmal noch in der Kritik an solchen Filtern wieder, deshalb sei ihr Vorhandensein erwähnt.
Die allgemeine Formel lautet:

P(A) ist die Wahrscheinlichkeit für A, P(A|B) ist die Wahrscheinlichkeit für A unter der Bedingung B, also wenn B eingetreten ist.
Wie sieht das nun für Spam aus? So:
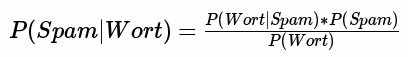
Zu beachten ist, dass wir diese Spamwahrscheinlichkeit für jedes Wort im Kommentar wissen wollen, daher am Ende mehrere Wahrscheinlichkeiten aufaddieren und normalisieren müssen.
Aufdröselung
Es gibt also genau drei Variabeln zu berechnen: Die Inverse Wahrscheinlichkeit, die Wahrscheinlichkeit von Spam und die Wahrscheinlichkeit für das Auftreten solcher Wörter. Das für jedes Wort. Was genau bedeuten die Formeln jeweils?
- P(Wort|Spam)
- Dies ist die Wahrscheinlichkeit, dass in einem Spamkommentar dieses Wort vorkommt:
Spamkommentare mit diesem Wort / Spamkommentare
- P(Spam)
- Die Gesamtwahrscheinlichkeit, dass ein Kommentar Spam ist:
Spamkommentare / Kommentare.
- P(Wort)
-
- Die Wahrscheinlichkeit, dass dieses Wort überhaupt in einem Kommentar vorkommt:
Kommentare mit diesem Wort / Kommentare
Programmiertechnische Konsequenzen
Es ist völlig klar, dass eine Datenbank gebraucht wird und die Bewertung größtenteils aus dem Heraussuchen der richtigen Daten zu den Worten besteht. Zuerst muss ein sogenannter Tokenizer den Kommentar in seine Einzelwörter zerlegen. Im Wesentlichen ist das ein:
tokenize(text) {
tokens = split("\W", text )
return unique(tokens)
}
Das Lernen eines Kommentars als Ham oder Spam ist nun nichts anderes, als diese Tokens in diese Datenbank namens "tokens" zu schreiben:
token (text) | ham (number) | spam (number)
Ist das Token schon vorhanden, wird der zugehörige Ham- bzw Spamwert um eins erhöht. Gleichzeitig wird der Gesamtzähler
Hamkommentare bzw
Spamkommentare um eins erhöht.
Diese Datenbank zusammen mit den Gesamtzählern gibt uns nun alle nötigen Werte:
- P(Wort|Spam)
spam = sql_query("Select spam from tokens where token = Wort")
spam / (Spamkommentare)- P(Spam)
Spamkommentare / (Spamkommentare + Hamkommentare)
- P(Wort)
-
ham, spam = sql_query("Select ham, spam from tokens where token = Wort)"
(ham + spam) / (Spamkommentare + Hamkommentare)
Formelveränderungen
Schaut man sich nun die Bewertungsfunktion im Bayes-Plugin an wird man feststellen, dass der PHP-Code nicht nur wesentlich unschöner als mein Pseudocode aussieht, sondern auch anders funktioniert. Das liegt daran, dass das Plugin auf
b8 aufbaute, und b8 nicht simpel das Bayes-Theorem benutzt, die Wahrscheinlichkeiten addiert und dann durch ihre Anzahl teilt. Diese Änderungen basieren
auf Tests und anderen theoretischen Annahmen als den hier gezeigten. Insbesondere die folgenden Änderungen sind enthalten oder denkbar:
Law of total probability
Wer Vorkenntnisse hat oder nachrecherchierte, dem könnte aufgefallen sein, dass Wikipedias
Bayes-Spamfilterformel anders aussieht:
 P(Wort)
P(Wort) wird hier gemäß dem
Law of total probability umgeformt. Ohne das gerade nachgerechnet zu haben vermute ich, dass die Werte gleich sein sollten und diese Formel nur
P(Wort) anders betrachtet.
Häufigkeit von Tokens im Kommentar
Wie oft ein Wort im Kommentar auftaucht sollte die Wahrscheinlichkeit beeinflussen. Dieser Artikel hier ist kein Spam, obwohl nun Viagra auftaucht, aber wäre jedes Wort Viagra, wäre er durchaus Spam. Deshalb beachtet b8 die Häufigkeit eines Tokens.
Wichtigkeit
Eine beliebte Spammertaktik ist, Kommentare mit ewig langem Fülltext auszustaffieren und den Spammerinhalt so zu verstecken. Der Gedanke dabei ist, dass die vielen harmlosen Worte den ganzen Kommentar harmlos erscheinen lassen. Die auch von b8 genutzte Taktik dagegen ist die Einführung eines Wichtigkeitsfaktors: Beziehe nur die Tokens in die Schlussrechnung ein, die eine Tendenz zu Spam oder Ham haben, also um einen bestimmten Faktor von der Mitte 0,5 abweichen. Der Gedanke dahinter ist, dass die vielen Füllwörter die Bewertung sonst gegen 0,5 tendieren lassen würden.
Optimierungsmöglichkeiten
Ich schrieb oben, dass dieser Artikel die theoretischen Grundlagen zwecks einer späteren Optimierung des Filters deutlich machen soll.
Diese Optimierungsmöglichkeiten sehe ich bis jetzt:
Ham-Spam-Faktor
Der Anstoßgeber dieses Eintrags ist diese
Diskussion. Grischa schlug vor, über irgendeinen Faktor auszugleichen, dass ein typischer Blog sehr viel mehr Spam als Ham bekommt und daher der Filter zu streng werden würde. Meiner Meinung nach ist das nicht wirklich ein Problem, da diese Verteilung elementar für den Filter ist, und nicht automatisch neuer Spam eingelernt wird, wenn man das nicht will.
Wikipedia
erwähnt, dass
P(Spam) generell 0,8 sei. Vielleicht würde es helfen, diesen Wert festzusetzen statt ihn empirisch zu bestimmen?
Häufigkeit von Tokens
Wie oben beschrieben ist die Häufigkeit von Wörtern innerhalb eines Kommentars ein wichtiger Faktor. Zur Zeit fließt das aber nur indirekt in die Bewertung ein, indem es bei der Bewertung selbst ignoriert wird, beim Einlernen aber beachtet wird. Statt in der Tabelle den Ham- bzw Spamwert um eins zu erhöhen, wird er um die Anzahl der Tokens erhöht. Bei der Bewertung aber wird jedes Token nur einmal beachtet, selbst wenn es mehrmals vorkommt. Das könnte man ändern.
Es ist auch ein kritischer Punkt, weil man sich hier leicht mit Anzahl der Tokens und Anzahl der Kommentare verheddern kann. Die Formel müsste genau geprüft werden.
Konstanten
Bei der Übernahme von b8 wurde die Klassifizierungsberechnung blind übernommen. In ihr enthalten sind einige Konstanten, die auf den
Testergebnissen beruhen. Es geht um diese Zeile:
$ratings[$word] = (0.15 + (($stored_tokens[$word]['ham'] + $stored_tokens[$word]['spam']) * $rating)) / (0.3 + $stored_tokens[$word]['ham'] + $stored_tokens[$word]['spam']);
0,15 und 0,3 sind die Konstanten, die hier direkt die Bewertung beeinflussen und entfernt bzw verändert werden könnten.
Schlusswort
Es ist nunmal Mathematik. Ich hoffe, die Erklärung macht die Funktionsweise des Filters trotzdem klarer. Die Optimierung des Filters könnte ein sehr interessantes Projekt sein, aber auch sehr zeitaufwändig.
Hinweise zu Fehler in den Formeln nehme ich dankend entgegen


Hampas Blog am : Eine Biene gegen Spam
Vorschau anzeigen