Zeitreihen in SQLite speichern
Friday, 17. January 2020
Es ist eigentlich Unsinn, Daten wie Zeitreihen in SQLite zu speichern, da Timeseries-Datenbanken noch vor kurzem ein kleines Hype-Thema waren. Es gibt also einige Alternativen. Jedoch fand ich keine zu meinem Projekt passende. Sie alle sind entweder gedacht zur Analyse von Serverevents, benutzen Java, werden nicht mehr gepflegt oder sind zu komplex aufzusetzen. rrdtool kommt einer simplen Lösung noch am nächsten, aber die nötige Vorgabe der Taktung macht es für mich unpassend. Mein Ziel, jahrelange Preishistorien mit jeweils unterschiedlicher Taktung und auch mal einigen Lücken effizient zu speichern ohne einen Kubernetes-Cluster laufen lassen zu müssen scheint außerhalb der Javawelt zu selten zu sein.
Also blieb mein Provisorium bestehen. Eine SQLite-Datenbank mit dieser Tabelle:
CREATE TABLE IF NOT EXISTS priceHistory(
id TEXT,
date INTEGER,
vendor TEXT,
price REAL
);"
Später kam noch ein Index dazu, weil die Performance ohne zu schlecht war:
CREATE INDEX priceHistory_ean_vendor ON priceHistory(id, vendor);
Das funktioniert! Es ist sogar trotz steigender Datenmenge auch einige Monate später noch schnell genug.
Diese steigende Datenmenge ist aber doch ein Problem: Mittlerweile ist diese Datenbank schon über 4GB groß, die Hälfte davon ist der Index. Das müsste kein Problem sein, Speicherplatz ist ja billig. Nur stimmt das nicht; nicht relativ zu den Serverkosten eines kleinen Projekts und angesichts möglicher zukünftiger Einschränkungen bei der Serverwahl, wenn die Datenbank weiter wächst. Und unbeschränktes Wachstum mit einer dann immer schwieriger handhabbaren Datenbankdatei bereitet mir Kopfschmerzen. Gut für die Performance kann die Lösung auf Dauer auch nicht sein.
Also durchforstete ich nochmal das Angebot an Zeitreihendatenbank und fand wieder nichts genau passendes. Zeit, einen Schritt zurückzugehen und zu überlegen, ob das nicht in SQLite bleiben und trotzdem etwas optimiert werden kann.
Strategie: Nur speichern was nötig ist
Die Daten dienen nur einem Zweck: Den Preisverlauf von Produkten anzuzeigen. Das sieht zum Beispiel so aus:

Wir zeichnen also im Grunde Strecken, wirklich dynamisch ändern sich die Preise nicht. Für eine Strecke brauche ich aber nicht mehr als zwei Punkte. Im gezeigten Diagramm sind es dagegen viele Punkte für jeden Abschnitt, da sich über eine längeren Zeitraum am Preis genau gar nichts getan hat. Das ist das erste Einsparpotential: Speichere nur, wenn sich der Wert geändert hat.
An der Datenbank muss man dafür nichts ändern. Die Optimierung kann rein im Code beim Abspeichern eines neuen Preises passieren. Trotzdem änderte ich den Index, passend zu den Daten:
CREATE TABLE IF NOT EXISTS priceHistory(
id TEXT,
date INTEGER,
vendor TEXT,
price REAL,
UNIQUE(id, date, vendor)
);"
Unnötige Doppelungen zu verhindern kann nur helfen.
Dann muss die Logik beim Datenzufügen angepasst werden. Vorher war das ein einfaches INSERT. Jetzt sieht der Code in etwa so aus:
def storePrice(id:, price:, vendor:)
# first we see whether the new entry differs from the last two, because if not we replace the last one. We need only two points to paint a trend line segment
lastEntries = @db.execute("SELECT rowid, price FROM pmdb.priceHistory WHERE id = ? AND vendor = ? ORDER BY date DESC LIMIT 2", id, vendor)
if price == lastEntries[0]['price'] && price == lastEntries[1]['price']
@db.execute("DELETE FROM pmdb.priceHistory WHERE rowid = ?", lastEntries[0]['rowid'])
end
# regardless what happened before, now we can just insert
@db.execute("INSERT INTO pmdb.priceHistory(id, price, vendor, date) VALUES(?, ?, ?, strftime('%s','now'))", id, price, vendor)
end
Ich fand, ein paar Visualisierungen machen das schneller klar.
Die naive Lösung hat einfach alles eingefügt.
Jetzt aber schaut der Code, ob die vorherigen Datenpunkte den gleichen Preis anzeigten. Wenn ja, verlängert er die Strecke, indem der letzte Datenpunkt gelöscht und stattdessen der neue (mit gleichem Preis, aber späterem Zeitpunkt) abgespeichert wird.
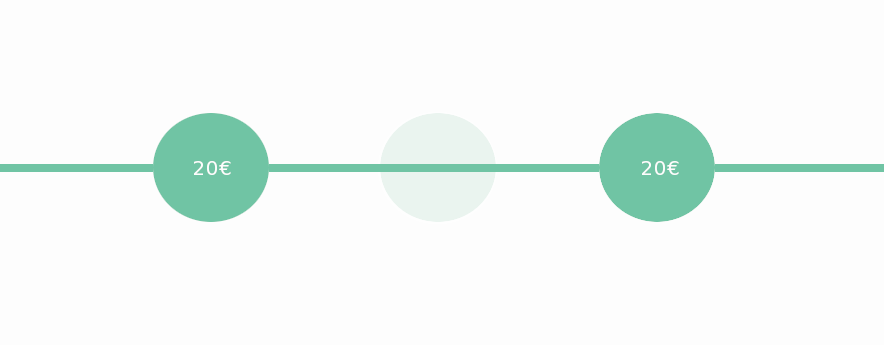
Wenn aber der Preis sich geändert hat bleiben die alten Datenpunkte bestehen und der neue kommt hinzu.

Sogar die bestehende Datenbank kann so verkleinert werden. Ich muss nur alle gespeicherten Datenpunkte entnehmen und mit dieser Strategie einzeln in eine neue Datenbanktabelle einfügen. Das Ergebnis behält tatsächlich seine Form, von der nun störenden Linienglättung mal abgesehen:
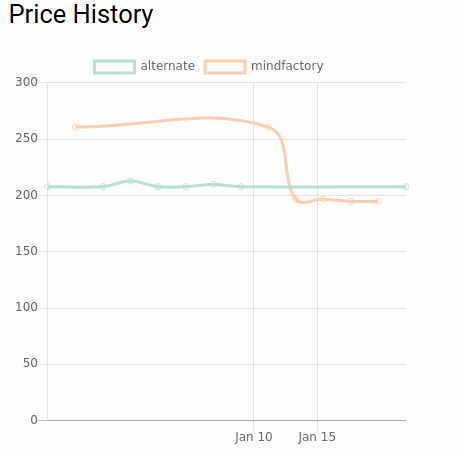
Und die Datenbank schrumpfte von 4.8GB auf 384MB, sehr ordentlich!

Weitere Kompressionsstrategien
Der nächste Schritt wäre das Bilden von Durchschnittswerten über definierte Zeiträume, Downsampling. Vielleicht kriege ich derzeit, je nach Händler, jede Stunde oder jeden halben Tag einen neuen Preis. Sind zwei Monate vergangen interessiert nur noch, wie teuer das Produkt durchschnittlich an einem Tag war. Nach 6 Monaten reichen die durchschnittlichen Preise in einer Woche. Nach einem Jahr der Durchschnittspreis in einem Monat.
Je nach Art der Zeitreihendaten ist diese Strategie deutlich besser, oder nur unnötig kompliziert. Hängt ganz davon ab wie oft sich die Preise bzw die Zeitreihendatenwerte ändern.
Sie lässt sich mit Code umsetzen, der in regelmäßigen Abständen durch die Datenbank geht und die Daten zusammenfasst. Es wäre toll, wenn es eine kleine Datenbank gäbe, der man solche Daten geben kann und die solche Konsolidierungen automatisch durchführt. Influxdb kann das zum Beispiel (wenn es entsprechend konfiguriert wird), aber ich würde eine Lösung bevorzugen, die nicht als zu wartende Infrastruktur auf einem Port läuft, sondern wie SQLite oder rrdtool einbindbar ist.
Vielleicht gibt es eine passende Datenbank und ich kenne sie nur nicht?
Update 20.09.2020: Ich stolpere gerade via HN über DuckDB, was eine interessante Alternative zu SQLite für diesen Anwendungsfall sein könnte. In diesem Blogartikel finden sich Beispiele.


onli blogging am : PC-Kombo bekam ein neues Design
Vorschau anzeigen
Netz - Rettung - Recht am : Wellenreiten 01/2020
Vorschau anzeigen
onli blogging am : Linksammlung 5/2024
Vorschau anzeigen