Githubs Copilot, also die neue Software, die KI-betrieben vollständigere Codeschnipsel vorschlägt, wird teilweise sehr kritisiert. Keineswegs der einzige Einlass in diese Richtung, schreibt ein OSBN-Blognachbar auf kaiserbarbarossa beispielsweise:
Ich schreibe also Programme, stelle sie unter die GPL und weiß nicht, ob diese “Intelligenz” nicht meinen Code irgendwo anders vorschlägt. Da könnte ich mir dann auch die GPL sparen. … Ich gehe also davon aus, dass meine Projekte und dieser Blog in Kürze auf eine andere Plattform umziehen.
Ignorieren wir mal, dass das Umziehen auf eine andere Plattform nicht zwingend Copilot den Zugriff auf nun halt anderswo öffentlich lesbaren Code entzieht. Ich finde, gerade als FOSS-Entwickler sollte man der Sache entspannter entgegentreten. Denn wir Entwickler müssen aufpassen, hier in dieser Frage nicht eine Urheberrechts-Maximierungsposition zu vertreten, die in anderen Fällen viele von uns ablehnen würden.
Lernen muss erlaubt sein, auch für KIs
Wenn wir als Entwickler einen Code lesen und Konzepte lernen, interessiert es erstmal nicht unter welcher Lizenz dieser Code steht. Das Urheberrecht gibt dem Urheber Rechte zur Kontrolle der Weiterverbreitung und der direkten Nutzung des konkreten Werks, also der Software und dem Quellcode als Text. Es gibt dem Nutzer kein Anrecht auf im Werk enthaltene Konzepte. Wenn ich also in einer Software eine neue Art von LinkedLists beschreibe, gehören die nicht per Urheberrecht mir. Dafür gäbe es Patente, wobei Softwarepatente von jedem vernünftigen Menschen auf diesem Planeten abgelehnt werden, weil sie zur völligen Unmöglichkeit des Schreibens neuer Software führen.
Ich kann also einen Code lesen, völlig egal welcher Lizenz, und davon lernen. Es muss ja nichtmal etwas abgehobenes wie eine neue Datenstruktur sein. Vielleicht lerne ich einfach, wie if-Abfragen funktionieren. Wenn ich als Mensch mit dem gewonnenen Wissen eine neue Software schreibe, gehört diese mir – nicht dem, von dem ich Konzepte gelernt habe.
Genau das gleiche sollte auch für KIs gelten. Auch wenn das, was wir als Künstliche Intelligenz bezeichnen, derzeit nicht besonders intelligent ist und keinesfalls eine starke künstliche Intelligenz ist: Selbst diese schwachen künstlichen Intelligenzen – pure Algorithmen ohne Bewusstsein – sind von der Funktionsweise her mittlerweile so abstrakt, dass ihr gespeichertes Wissen keine reine Reproduktion ist. Sie lernen daher auf durchaus abstraktem Level. Bei einem neuronalen Netz als Funktionsweise hinter der KI beispielsweise kann man die entstandenen Konfigurationen nicht mehr originär dem eingelernten Code zuordnen.
Täte man das, dann gälte das gleiche auch für den Lernprozess von Menschen. Denn je nach Sichtweise auf den menschlichen Organismus passiert bei uns ja nichts anderes, ordnet Lernen unsere Neuronen in anderen Konfigurationen an.
Ich weiß: Manchmal machen Unternehmen das. Programmierer Anton darf nicht an Projekt Y arbeiten, weil dort X der Softwareschmiede abc nachprogrammiert wird, Anton dessen originalen Quellcode mal gelesen hat, und die Firma nicht von abc verklagt werden will. Aber das sind Risikominimierungen. Es sind nicht echte, direkte Ansprüche, die abc aus dem Urheberrecht ziehen kann.
Das ist nur ein Argument, nennen wir es das ethische. Das andere ist rein verfahrenstechnisch: Copilot ist Software. Der Code, den es ausspuckt, kann es nicht per Urheberrecht schützen, weil es keine Person – kein Urheber – ist. Entsprechend dürfte es unmöglich sein, der Nichtperson Copilot Urheberrechtsverletzungen vorzuwerfen. Und was sonst sollte man dem System vorwerfen können? Patentverletzungen?
Wie spielt die GPL hier mit rein
Es ist kein Wunder, dass die Kritik an Copilot oft von GPL-Entwicklern kommt. Auch ich greife gerne zu dieser Lizenz und kenne daher ihre Bedingungen. Die GPL schützt die Freiheit von Software, indem es freiheitswahrende Bedingungen an ihre Weiterverbreitung knüpft. Anders als bei permissiven Lizenzen wie BSD/MIT müssen abgeleitete Werke den Nutzern Freiheitsrechte zugestehen: Den Code zu lesen, ihn ändern und unter gleicher Lizenz weiterverbreiten zu können. Bei der AGPL gilt das sogar für Software, auf die über ein Netzwerk (=dem Internet) zugegriffen wird. Der Zugriff übers Netz gilt dann schon als Weiterverbreitung und schließt so das Schlupfloch, das von GPL-Software abgeleitete proprietäre Serversoftware ausnutzte.
Um diese Rechte durchzusetzen benutzt die GPL das Urheberrecht. Mit ihr sagt der Entwickler: Ich, als Urheber, gebe dir diese und jene Rechte, dafür musst du das und das machen. Weil ich der Urheber bin und über das Urheberrecht dazu befähigt musst du auf mich hören, willst du meine Software nutzen. Wenn nun Copilot hingeht, GPL-Code vorne einliest und hinten ohne GPL-Lizenz wieder ausspuckt, dann verfehlt die GPL ihre Wirkung.
Aber hier muss man eben wieder berücksichtigen, was oben gilt: Nur weil ich in einem GPL-Quellcode gelernt habe wie if-Abfragen funktionieren, muss ich nicht alle zukünftigen if-Abfragen unter die GPL stellen. Bei diesen Lizenzen geht es ums stumpfe Kopieren von (etwaig sogar kompletten) Werken mit einer ausreichend hohen Schöpfungshöhe, nicht um das Lernen kleinteiliger Konzepte. So weit zu gehen käme im Effekt wieder der Patentierung von Software gleich, dem Unmöglichmachen der Softwareentwicklung. Es überhöhte das Urheberrecht weit über die Grenze, bei der es derzeit liegt. Der RIAA würde das gefallen, Leistungsschutzrechtvertreter hätten Dollarzeichen in den Augen, das manifestierte Böse namens Oracle hat mit dieser Auffassung Milliarden von Google gefordert, Abmahnanwälte würden jubeln. Entsprechend muss jeder Softwareentwickler diese Position ablehnen.
Ein lernendes System darf unabhängig der Lizenz von Code lernen. Auch von GPL-Software.
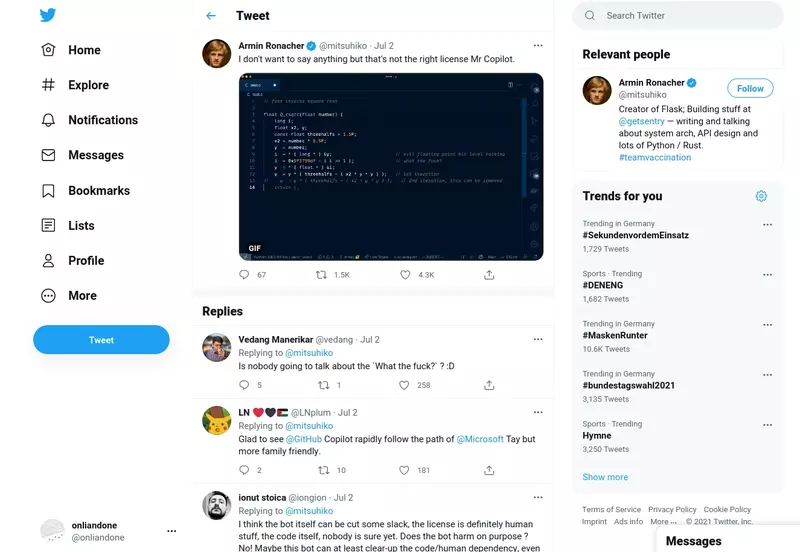
Allerdings: Reines Lizenzwegwaschen geht auch nicht
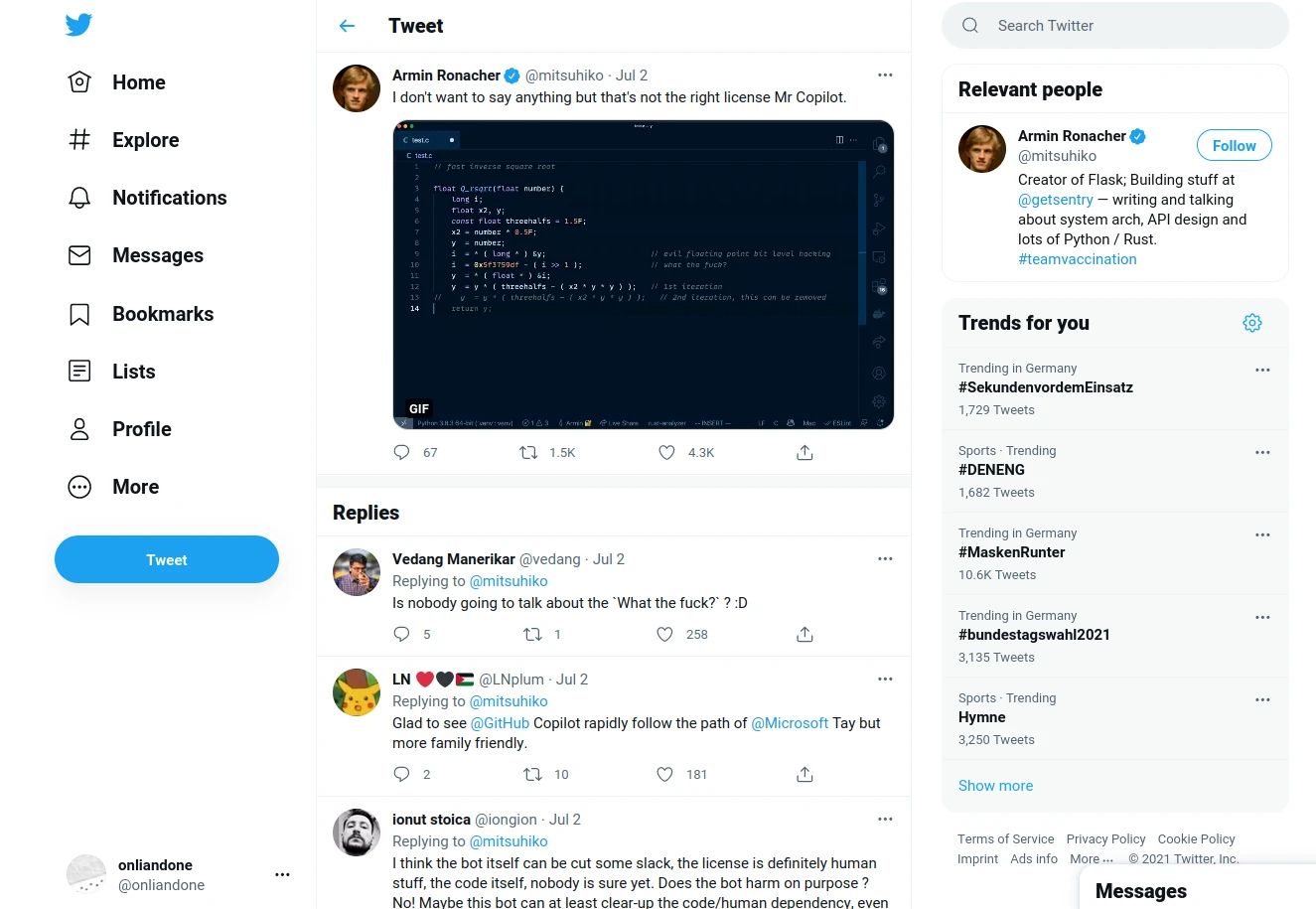
Es gilt eine Einschränkung zu machen: Wenn Copilot zeilenweise komplette Funktionen aus GPL-Codequellen kopiert, dann fällt es irgendwann schwer diese Position aufrechtzuhalten. Es geht dann noch über die nicht erreichte Schöpfungshöhe, sodass das Urheberrecht vll nicht greift, aber je länger und wie mehr 1:1 die Codeübernahme ist desto kritischer wird das. Armin Ronacher (mitsuhiko) hat auf Twitter ein entsprechendes Beispiel gezeigt, bei dem sogar die Kommentare noch aus der Originalquelle sind.
Aber letzten Endes ist das eine Frage der Feinabstimmung, wie abstrakt Codepilot lernt, und dass die gezeigten paar Zeilen vom Urheberrecht geschützt wären darf getrost bezweifelt werden. Wenn das also das Extrembeispiel der Verfehlungen Copilots sind, dann gibt es kaum einen validen Grund zur Kritik. Wenn Copilot beispielsweise lizenzignorierend ganze Dateien kopieren würde, dann wäre es vorbei, aber so verhält sich die Software nicht. Trotzdem müssen Copilots Schöpfer hier aufpassen, dass mein "Es ist ein lernendes System, keine Kopiermaschine" gültig bleibt.
Githubs Copilot schlägt zurecht Wellen. Im ersten Moment ist die ablehnende Position im FOSS-Umfeld völlig verständlich, mein Blognachbar möge sich bitte nicht vorgeführt fühlen. Wir kommen hier ins hochkomplizierte Medien- und Urheberrecht, das dann auch noch in jedem Land unterschiedlich ausfällt. Aber ich hoffe, dass viele Entwickler meiner entspannten Argumentation folgen werden, da die negativen Implikationen einer juristischen Ablehnung eines solchen Systems viel zu groß sind und allen Entwicklern massiv schaden würden. Und langfristig sind es unsere Überzeugungen, die im Konflikt mit der Lobbyarbeit der Großkonzerne und der Anwaltsfraktion diese uns betreffenden Gesetze formen. Unsere Überzeugungen als Entwickler, unsere Reaktionen auf solche Systeme sind daher unheimlich wichtig.



linuxnews.de am : PingBack
Vorschau anzeigen