Arrival
Saturday, 30. November 2019
Jack Reacher
Friday, 29. November 2019
Begley: Memories of a Marriage
Wednesday, 27. November 2019
Zukunftspläne für pc-kombo: 4 Aufgaben, 3 Seiten, mehr FOSS
Thursday, 7. November 2019
Damit der Hardwareempfehler seine PC-Builds zusammenstellen kann muss pc-kombo vier Aufgaben auf einmal erledigen:
- Er muss sich eine Liste aller möglichen Komponenten zusammenstellen.
- Dann muss er herausfinden, was wieviel kostet.
- Um dann aus diesen Komponenten zu wählen zu können muss er wissen, welche Hardware wie schnell ist.
- Schließlich kann er zusammenpassende Builds zusammenstellen, also per Algorithmus optimieren und dabei bedenken, welche Hardware zusammenpasst (welche Prozessor in welches Motherboard, welche Grafikkarte in welches Gehäuse, welches Netzteil stark genug ist etc).
Ich sitze derzeit daran, das weiter aufzusplitten. Natürlich ist es jetzt schon in einer gewissen Weise aufeteilt: Die Webanwendung holt ja nicht bei jeder Anfrage alle Komponenten aus Crawlern und die Preise von den APIs, sondern erledigt vieles vorher im Hintergrund (die Preiserfassung gar per Micoservice). Aber letzten Endes ist es doch eine Seite, eine Interface, ineinander greifende Arbeitsschritte. Stattdessen möchte ich am Ende drei spezialisierte Seiten haben – eine namensgemäße Kombination von Anwendungen erschaffen.
Eine PC-Hardwaredatenbank
Sie soll alle Prozessoren, alle Grafikkarten, alle Motherboards usw umfassen, samt ihren Spezifikationen, Reviews und was sonst noch anfällt. Der Clou: Das soll offen werden. AGPL-lizenzierter Code, API-Zugriff auf die Datensammlung. Denn als ich pc-kombo startete war das Sammeln der Hardware eine unvermutete Mammutaufgabe, wofür es keinen guten Grund gibt. Das sind keine Geschäftsgeheimnisse, keine geheimhaltungswürdige Informationen. Und doch gibt es da eine kleine Industrie drumrum, die solche Daten sammelt und zu Mondpreisen verkauft.
Mit dieser Datensammlung und der API wäre nicht nur pc-kombo gedient, sondern viele andere Projekte könnten davon profitieren. Für pc-kombo und mich wäre es aber besonders praktisch: Ein zentraler Ort für die Hardwaredatensammlung. Wo ich nochmal Zeit und Arbeit darein investieren kann, die Datensammlung besser und einfacher zu gestalten. Gleichzeitig immer im Blick halten kann, auf jeden Fall auch das zu sammeln war das Empfehlungssystem mindestens braucht.
Für die Einzelansicht einer Grafikkarte habe ich bereits einen Entwurf:
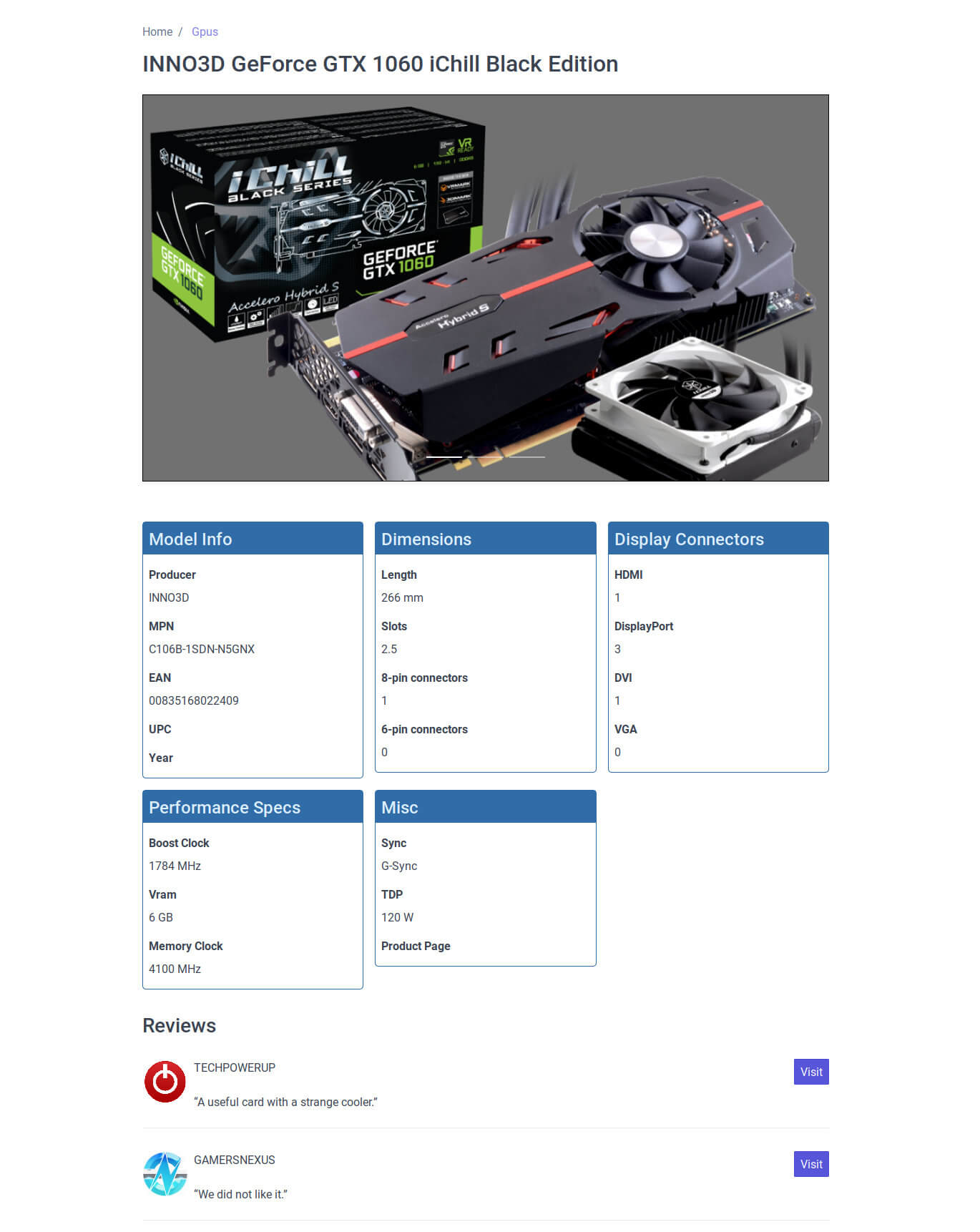
Nebenbei: Statische Seiten zu generieren entstammt als Ansatzpunkt natürlich dieser Projektidee.
Falls jemand als Mitentwickler einsteigen will, gerne! Einfach in Kontakt treten. Softwaretechnisch wird das ein statischer Seitengenerator in Ruby; Das, sowie HTML, CSS und vielleicht Javascript muss geschrieben werden, und mit dem angedachten Backend und der Datensammlung gibt es nochmal eine ganz andere Aufgabe zu bewältigen.
Eine Metabenchmarkseite
Der Metabenchmark verdient mehr Aufmerksamkeit. So oft wollen Leute wissen, wie gut Prozessoren und Grafikkarten im Vergleich mit anderen sind, welche Spiele und Anwendungen sie wie gut bewältigen. Und viel zu oft schauen sie dabei auf die falschen Daten: Künstliche Vergleiche von Spezifikationen oder Ergebnisse artifizieller Benchmarks, die über die Praxis fast nichts aussagen. Echte Benchmarks der Zielanwendungen sind der viel bessere Weg, Prozessen und Grafikkarten zu vergleichen.
Gleichzeitig ist das nicht einfach. Verschiedene Benchmarks mit teils disjunkten Teilnehmerlisten vergleichbar zu machen ist komplizierter, als ich anfangs dachte. Doch mittlerweile meine ich, das Problem algorithmisch so gut gelöst zu haben wie möglich. Wenn es mal offensichtlich falsche Ergebnisse gibt, dann liegt das mittlerweile immer an fehlenden Daten. Was sehr selten geworden ist.
Und doch beobachte ich für den Benchmark wenig Popularität, außer ich stoße Leute drauf. Deswegen soll der Metabenchmark seine eigene Seite bekommen, mit einer besseren Oberfläche, und so besser sichtbar werden. Und ebenfalls eine API bekommen, sodass andere Projekte ihn benutzen können. Wobei er selbst seine Prozessoren und Grafikkarten aus der API der Hardwaredatenbank ziehen würde.
Und wie gehabt: Ein PC-Builder
An pc-kombo würde sich laut diesem Plan erstmal gar nicht viel ändern. Die Daten der anderen Seiten benutzt er ja jetzt schon und bräuchte sie auch weiterhin. Aber mit einem kleineren Kern, besserer Automatisierung und reduzierten Ansprüchen an die Datenbank kann ich vielleicht ein paar der Verbesserungen umsetzen, zu denen ich bisher nicht kam.
Im Grunde will ich nehmen, was pc-kombo sowieso schon macht, es besser kapseln, automatisieren und zugänglich machen. Dabei mir und anderen helfen, daher sind die APIs geplant und eine freie Lizenz für die Datenbank. Es muss sich natürlich erst noch zeigen, ob ich das wirklich gebaut kriege und dann auch so wird, wie ich mir das derzeit vorstelle.

