Serendipity 2.1.4 und 2.2.1-alpha1 veröffentlicht
Thursday, 20. September 2018
La Défense, Paris
Thursday, 20. September 2018

Marc Ribot - "Bella Ciao" (feat. Tom Waits)
Tuesday, 18. September 2018
Wie man mit AMQP Progammbestandteile unter Ruby/Sinatra auslagern kann
Thursday, 13. September 2018
Bevor ich wie beschrieben die problematische Datenbankabfrage beim PC-Hardwareempfehler pc-kombo entdeckte hatte ich ja schon einige andere Verbesserungen probiert. Die anspruchsvollste war das Auslagern der Preisaktualisierung auf einen zweiten Server.
Ausgangssituation
Der Hardwareempfehler ist eine Ruby/Rails-Anwendung. Der reguläre Teil davon kümmert sich um das Berechnen der Empfehlungen, und natürlich um das Bauen des HTMLs der Webseite. Eine normale Web-App. Etwas ungewöhnlich ist der Threadpool. Er wird beim Start der Webanwendung erstellt.
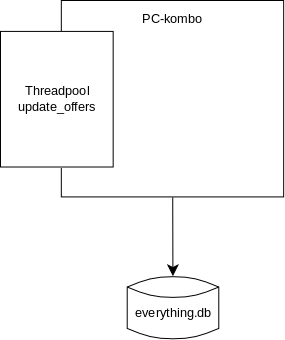
In diesem Threadpool lief der Code, der regelmäßig die APIs der eingebundenen Shops abfragt um die Preise zu aktualisieren. Das ist superwichtig für die Software, denn nur mit aktuellen Preisen können die besten PC-Builds für das Wunschbudget zusammengestellt werden.
Aber hier lag auch ein Problem: Dieses Preisaktualisieren ist keine leichtgewichtige Operation. Denn sie beinhaltet das Herunterladen, Entpacken und Durchsuchen richtig großer XML- und CSV-Dateien. Das ist besonders problematisch in einer Sprache wie Ruby, in der trotz der Threads wegen des GIL kein echter Parallelismus möglich ist. Und der Threadpool läuft ja im gleichen Prozess wie der Servercode. Das war also eine durchaus wahrscheinliche Ursache für das gelegentliche Langsamsein der Anwendung.
Diese Aufgabe sollte also ausgelagert werden.
Die Lösung: Microservices und AMQP
Anstatt die Preisaktualisierung nur in einen anderen Prozess zu verfrachten wollte ich sie auf einen eigenen Server packen. Dort sollte ein Daemon laufen, der die Preise aktualisiert und die neuen Preise zum Hauptserver sendet. So ist sichergestellt, dass der Hauptserver nur die minimale Last hat, die fertig aktualisierten Preise anzuwenden. Doch das war vor allem aufgrund von SQLite einfacher gesagt als getan. Denn das ist die genutzte und inzwischen auch schwer auswechselbare Datenbank. Der zweite Server kann also keine Verbindung zum Datenbankserver aufbauen und direkt die neuen Preise eintragen, denn es gibt beim dateibasierenden SQLite keinen Datenbankserver.
Meine erste Idee war das Replizieren der Datenbank. Es gibt da mit rqlite eine interessant aussehende Lösung, mit der man eine oder auch mehrere SQLite-Datenbanken auf mehrere Server replizieren kann. Und Änderungen werden synchronisiert. Dann hätte der zweite Server die Datenbank aktualisiert und die Änderungen wären automatisch aktualisiert worden. Doch fehlt rqlite ausgerechnet ein Ruby-Client.
So landete ich als zweites bei Bedrock. Auch diese Software repliziert SQLite-Datenbanken. Und es umgeht ziemlich genial das Client-Problem, indem es den MySQL-Client für seine Zwecke umfunktioniert, und den hat wohl jede Sprache. Doch leider war Bedrock nicht zum Laufen zu kriegen. Es hängt von gcc-6 ab, was schon alleine ein schlechtes Zeichen ist. Und dann lief es einmal kompiliert trotzdem nicht. Zudem ist unklar, ob Bedrock mit bestehenden SQLite-Datenbanken initialisiert werden kann, oder ob die Daten nachträglich eingepflegt werden müssten. Dann hilft es auch nicht, dass es wie ein ziemlich sympathisches Projekt wirkt.
Also zurück zum Kernproblem: Im Grunde sollen nur Informationen von einem Server zum anderen transportiert werden. Dafür gibt es auch andere Lösungen. So ist Sinatra wunderbar geeignet eine REST-API zu betreiben, sodass dann der zweite Server die neuen Preise POSTen könnte. Doch läuft man dann in das typische Problem beim Umbau eines Monolith in eine Microservice-Architekturen: Was tun, wenn die Ziel-API mal down ist? Wie kann auf Fehler und Netzwerkprobleme reagiert werden?
Nun sind Microservices schon fast wieder aus der Mode und es gibt für so etwas natürlich fertige Lösung. Die meines Wissens beste: Setze eine Queue zwischen die Server, welche Daten Zwischenspeichern kann. Und genau das ist AMQP mit einem Broker wie RabbitMQ.
Neue Architektur
Wir landen also hier:
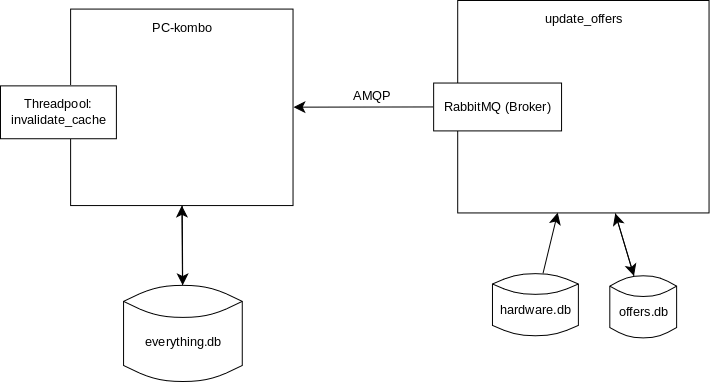
Au dem zweiten Server werden die Preise aktualisiert. Um nicht unnötig Daten zu senden werden diese auch lokal gespeichert, nur Änderungen werden an den Hauptserver gemeldet. Diese Änderungen werden an den auf dem gleichen Server laufenden RabbitMQ-Broker gepusht, über AMQP. Der Hauptserver macht ebenfalls eine AMQP-Verbindung zu diesem Broker auf. Und erhält dann über diese Verbindung über eine Queue die Preisaktualisierungen zugespielt.
Wir haben immer noch den Threadpool, aber der wird nur noch zum regelmäßigen Löschen des Datenbank-Cache genutzt und aktiviert so die Nutzung der neuen Preise.
Das tolle daran ist das Zwischenspeichern auf dem Broker. Ist pc-kombo oder die Verbindung zum Hauptserver down gehen keine Preisaktualisierungen verloren. Sie werden gesichert und dann später und geordnet gesendet, sobald die Verbindung wieder da ist. Das hat sich nun schon mehrfach als sehr praktisch erwiesen.
Der Code dafür ist relativ simpel. Genutzt wird der eine bekannte AMQP-Client für Ruby, bunny. Auf dem zweiten Server senden wir die Aktualisierung:
conn = Bunny.new("amqp://user:password@localhost:5672")
conn.start
ch = conn.create_channel
@q = ch.queue('offers', :exclusive => false)
@x = ch.default_exchange
# Notify master of new offer or offer to be deleted, but only if it is necessary
# For this to work offers.db has to be in sync on the two servers
def notifyMaster(offer)
changes = updateDB(offer)
if changes
@x.publish(offer.to_msgpack, routing_key: @q.name)
end
end
Zusätzlich und nicht zu sehen ist der Threadpool, der wieder genutzt wird um regelmäßig die Preise des Hardwaresortiments zu aktualisieren, woraufhin jedes mal notifyMaster aufgerufen wird. Sinatra läuft hier aber nicht.
Auf dem Hauptserver bauen wir in Sinatras configure ebenfalls eine Verbindung zum Broker auf, nur dass wir nichts senden, sondern empfangen:
configure do
if settings.production?
conn = Bunny.new("amqp://user:password@server2-ip:5672")
conn.logger.level = Logger::INFO
conn.start
ch = conn.create_channel
q = ch.queue("offers")
q.subscribe do |delivery_info, metadata, payload|
offer = MessagePack.unpack(payload)
Database.instance.updateOffer(offer)
end
end
end
MessagePack hat übrigens die Eigenheit, Hashes mit Symbolen in Hashes mit Strings zu verwandeln. Aus einem gesendeten offer[:abc] wird auf dem Hauptserver offer["abc"]. Darauf musste ich erstmal kommen. Ansonsten erschien es mit aber absolut logisch, für diesen Datentransport ein platzsparenderes binäres Format statt JSON zu nutzen, was wohl sonst meine übliche Wahl gewesen wäre. Ich hatte es zwischendurch auch mit protobuf probiert, kam mit der Logik dessen Ruby-Clients aber gar nicht zurecht.
Insgesamt funktioniert die neue Architektur. Und auch wenn die Preisaktualisierung schließlich nicht die Hauptursache des Performanceproblems war, hilft diese Auslagerung doch sicher dabei, die Performance nicht doch gelegentlich einbrechen zu lassen. Und auf dem zweiten Server kann ich nun besseres Monitoring einbauen, sodass ich mir der laufenden Preisaktualisierung sicher sein kann. Den ziemlich intransparenten Threadpool einzusehen war vorher nämlich schwierig.
Fazit: Nett, aber nicht ganz so ohne
Ich finde, das ist ein schönes Beispiel für den Einbau eines Microservices in einen bestehenden Monolith, bzw. die Auslagerung eines kritischen Programmbestandteils auf einen zweiten Servers. Es war allerdings auch eine größere Operation. Viele Probleme waren zu lösen: Welcher Code muss auf den zweiten Server dupliziert werden, um dort überhaupt Preise aktualisieren zu können? Ich wollte ja nicht alles neu schreiben. Letzten Endes liegt dort jetzt der gesamte Programmcode, nur wird er von einem neuen Ruby-Skript anders genutzt als vorher. Ähnliches Problem: Welche Daten müssen dupliziert werden? So war mir schnell klar, dass Benchmarkdaten nicht, dafür aber alle Hardwaredaten gebraucht werden. Dass es aber auch sinnvoll ist, die vorhandenen Preisdaten zu spiegeln um nur Änderungen zu senden (was das Datenaufkommen und damit die Last auf dem Hauptserver reduziert) wurde mir erst etwas später klar.
Von RabbitMQ habe ich einen gemischten Eindruck. Die Software funktioniert sehr solide, das Dashboard ist hervorragend gemacht. Doch war die Konfiguration gar nicht so einfach. RabbitMQ unterstützt verschiedene Arten von Queues, und mir war nicht ganz klar welche die passendste ist. Letzten Endes passte wohl der Standard. Hauptproblem der Software ist meinem Eindruck nach die Dokumentation: Sie erklärt zwar haarklein alles, schau dir nur die Installationsanleitung an! Aber sie erklärte nie genau das, was ich wissen wollte. Sie ist zu abstrakt und deckte nicht meine Fragen und Probleme ab, wie das richtige Nutzersetup um das Dashboard für einen Remotezugriff zu aktivieren, oder wie Letsencrypt-Zertifikate dieses absichern können.
Auch bunny entpuppte sich als Herausforderung. Der Client hat eine gute API und scheint angemessen ressourcenschonend zu funktionieren. Aber gelegentlich ist mir auf dem Hauptserver die Verbindung abgerissen und konnte nicht automatisch wiederhergestellt werden. Und ich finde es archaisch, zur Besprechung solcher Bugs auf Mailinglisten verwiesen zu werden. Dort konnte mir dann auch nur geraten werden, die automatische Verbindungsreparatur zu deaktivieren und sie manuell neu herzustellen, was keine tolle Lösung ist. Allerdings scheint die Verbindung stabiler zu funktionieren, seit das kernauslastende Performanceproblem gelöst ist. Vielleicht triggerte die Serverlast eine Race-Condition im Code von bunny. Das wäre natürlich ein schwer zu findender Bug.
Insgesamt war es eine lehrreiche Aktion, die glücklicherweise auch noch funktioniert hat.
Pocket-Topstories in Firefox aktivieren
Tuesday, 11. September 2018
Wenn ein fehlender Index den Server lahmlegt
Monday, 10. September 2018
In letzter Zeit hatte ich bei meinem PC-Hardwareempfehler pc-kombo mit Performanceproblemen zu kämpfen. Auf meinem Rechner lief die Anwendung lokal gut. Aber wenn mehrere Besucher auf dem Server waren brach desöfteren die Performance ein. Und zwar aller Seiten, die irgendwie auf die SQLite-Datenbank zugriffen oder kompliziertere Berechnungen durchführten.
Bis hierhin hatte ich schon einige Stellen der Serveranwendung optimiert. Die Preisaktualisierung – für die große XML-Dateien geparst werden müssen, was die Serverperformance beeinträchtigen konnte – wurde auf einen zweiten Server ausgelagert, das war die größte Aktion. Geschickter und ebenfalls mit großem Effekt: Ein Cache verhindert das unnötige Neuberechnen des besten PCs für einen bestimmten Preispunkt, solange sich die Komponentenpreise nicht geändert haben. Übersetzungen werden nun genauso im Arbeitsspeicher zwischengespeichert, was die Customize-Funktion beschleunigt. Die Berechnung der Durchschnittsgröße eines Gehäuses wird nur noch durchgeführt, wenn die Detailseite eines Gehäuses mit dem Größenvisualisierer angezeigt wird, und so weiter. All das half, doch es war nicht die Ursache des Grundproblems. Dafür wurde das nun sichtbar.
Schuld an den Performanceeinbrüchen war wohl eine einzelne Datenbankabfrage.
Der Debugweg
Nach all den vorherigen Verbesserungen stach eine Seite als noch besonders langsam heraus: Die Detailansicht einer Komponente, z.B. die des Prozessors i7-8700K. Auf dem lokalen Rechner mit Testdaten war diese Seite allerdings schnell. Ich entschloss mich, trotzdem erstmal dort zu debuggen, da der langsamste Abschnitt auf meinem Rechner ja auf dem Server noch problematischer sein und die längere Verzögerung verursachen könnte.
Zum Performance-Debuggen benutze ich ruby-prof mit ruby-prof-flamegraph. Über die Gemseite finden sich gute Erklärungen. Bei mir sieht der gekürzte Code so aus:
get '/:country/product/:type/:ean' do |country, type, ean|
if settings.development?
require 'ruby-prof'
require 'ruby-prof-flamegraph'
begin
RubyProf.start
rescue RuntimeError => re
RubyProf.stop
RubyProf.start
end
end
html = doStuff()
if settings.development?
result = RubyProf.stop
printer = RubyProf::FlameGraphPrinter.new(result)
File.open("profiling/profile_data", 'w+') { |file| printer.print(file) }
end
html
end
Die Datei profiling/profile_data kann ich dann mit flamegraph.pl visualisieren:
flamegraph.pl --countname=ms --width=1920 < profile_data > product.svg
Und das sah so aus:

Mit 73% ging der größte Teil der Rechenzeit also in Hardware#priceHistory verloren. Auf meinem Rechner war das weniger als eine Sekunde. Aber auf dem Server hatte das Laden der Seite vorher – unter Last – ~8 Sekunden gedauert. Dort würde diese Funktion wohl ebenfalls den größten Teil der Rechenzeit ausmachen, vermutete ich.
Was macht priceHistory? In Grunde führt es diesen SQL-Query aus:
SELECT * FROM pmdb.priceHistory WHERE ean = ? AND (vendor = ? OR vendor = ?) ORDER BY date ASC
Ein ziemlich simples Select. Doch der Query-Plan sah nicht gut aus:
EXPLAIN QUERY PLAN SELECT * FROM priceHistory WHERE ean = "05032037108652" AND (vendor = "vendor1" OR vendor = "vendor2") ORDER BY date ASC; 0|0|0|SCAN TABLE priceHistory 0|0|0|USE TEMP B-TREE FOR ORDER BY
SCAN TABLE priceHistory ist der problematische Teil hier. Diese Erklärung bedeutet, dass zum Erfüllen dieser Abfrage die gesamte Tabelle gelesen werden muss. Aber wie groß kann eine solche Tabelle mit etwas Preishistorie schon sein?
du -sh /home/pc-kombo/www.pc-kombo.de/productMeta.db 823M /home/pc-kombo/www.pc-kombo.de/productMeta.db
Upps. Nicht alles davon sind die Preisdaten. Aber der größte Teil.
Um also die Detailseite anzuzeigen musste der Server jedes mal eine 800MB große Tabelle auslesen. Das führte dazu, dass ein Prozessorkern für ein paar Sekunden komplett ausgelastet war (was in Sprachen wie Ruby ohne echten Parallelismus besonders problematisch ist), und auch die Festplatte wurde dadurch natürlich komplett in Beschlag genommen. Kein Wunder, dass dann auch die anderen Seitenaufrufe langsam wurden.
Hier hilft normalerweise ein Index:
CREATE INDEX priceHistory_ean_vendor ON priceHistory(ean, vendor);
Und tatsächlich:
EXPLAIN QUERY PLAN SELECT * FROM priceHistory WHERE ean = "05032037108652" AND (vendor = "vendor1" OR vendor = "vendor2") ORDER BY date ASC; 0|0|0|EXECUTE LIST SUBQUERY 1 0|0|0|USE TEMP B-TREE FOR ORDER BY
Der Index wird direkt genutzt. Und so viel bringt das in Praxis:

Alleine durch diesen einen Index ist die Preishistorie nun nicht mehr der größte Zeitfaktor in der Berechnung, sondern mit 16% einer von mehreren. Und htop bestätigt das, denn bei dem Seitenaufruf schießt die Prozessorlast des einen Kerns nun nicht mehr auf 100%, sondern bleibt irgendwo unter 10%. Dementsprechend werden auch die anderen Seiten nicht mehr ausgebremst.
Die eigentliche Ursache
Es ist fast immer problematisch, wenn ein Provisorium länger genutzt wird als geplant. Genau das ist hier passiert. Als ich die Preishistorie entwickelte wollte ich die Preise nur für wenige Wochen in der Datenbank speichern. Die eigentliche Lösung sollte eine Zeitseriendatenbank wie rrdtool sein. Solche Datenbanken können die Datenmenge begrenzen, in dem für längere zurückliegende Zeiträume Datenpunkte entfernt werden. Statt den Preis einer Grafikkarte von vor zehn Jahren alle 5 Minuten parat zu haben, speichert rrdtool dann eben nur den Durchschnittspreis einer zehn Jahre zurückliegenden Kalenderwoche. Und bestimmt wäre bei der richtigen Lösung dann auch der Index gesetzt gewesen.
Stattdessen blieb das Provisorium bestehen, bis die Datenmenge so sehr anstieg, dass der fehlende Index – dessen Fehlen beim Entwickeln mit den wenigen Datenpunkten ja noch kein Problem war – den Server ausbremsen konnte.
Ein Blick auf AppImage, erste Startschwierigkeiten und Lösungen
Monday, 27. August 2018
![]() Gestern war ich auf der Froscon. Nur kurz, es reichte für zwei Talks: Einmal eine nette kleine Einführung in node-red (was mich aufgrund von Pipes interessierte), dann noch in den englischen Let's talk about Desktop Linux Platform Issues. Ich ging da mit gemischten Gefühlen raus: Die Diskussion am Ende funktionierte nicht, aber der Sprecher wirkte nett und ehrlich an der Verbesserung von Linux interessiert. Er präsentierte AppImage als mögliche Lösung. Zwar weiß ich nicht, ob das Verfügbarmachen von Software per Binaries wirklich das große Problem des Linux-Desktops ist. Andererseits ist das Verteilen von Software unter Linux ja wirklich nicht so einfach wie es sein soll. Ich markierte mir also AppImage als Möglichkeit dazu vor.
Gestern war ich auf der Froscon. Nur kurz, es reichte für zwei Talks: Einmal eine nette kleine Einführung in node-red (was mich aufgrund von Pipes interessierte), dann noch in den englischen Let's talk about Desktop Linux Platform Issues. Ich ging da mit gemischten Gefühlen raus: Die Diskussion am Ende funktionierte nicht, aber der Sprecher wirkte nett und ehrlich an der Verbesserung von Linux interessiert. Er präsentierte AppImage als mögliche Lösung. Zwar weiß ich nicht, ob das Verfügbarmachen von Software per Binaries wirklich das große Problem des Linux-Desktops ist. Andererseits ist das Verteilen von Software unter Linux ja wirklich nicht so einfach wie es sein soll. Ich markierte mir also AppImage als Möglichkeit dazu vor.
Heute stolperte ich via Thomas über Please stop making the library situation worse with attempts to fix it. Im Artikel geht es nicht wirklich darum, dass AppImage und die anderen Versuche alles schlimmer machen würden, sondern darum, dass AppImage nicht richtig funktioniere. Bei aller (bewusst) zur Schau gestellten Naivität des Sprechers probono im Vortrag: Damit hatte ich nach der guten Darstellung nun nicht gerechnet. Also wollte ich mir das schon jetzt einmal selbst anschauen.
Mein Beispielprogramm ist simdock. Dem Programm könnte die Verteilung als AppImage helfen, es ist ein ziemlich gutes Dock, mit meiner Nischendistro fällt es mir aber schwer, es ordentlich für Ubuntu etc. zu verpacken. Ausgangssituation: Es gibt ein Github-Repo mit dem Quellcode, dort liegt auch ein debian-Ordner mit dem ganzen Boilerplate zum Bauen des .debs, zusätzlich gibt es ein ppa. Das Makefile ist simpel und listet alle Abhängigkeiten, sauber mit pkg-config. Es gibt sogar ein PKGBUILD im AUR. Einen besseren Kandidat für AppImage dürfte es nicht geben.
Hier ist die Anleitung. Es werden sechs Wege gezeigt:
- Nutze den Open Build Service (OBS)
- Konvertiere bestehende Binärpakete
- Travis CI builds wiederverwenden
- linuxdeployqt für Qt-Anwendungen
- electron-builder
- Ein AppDir erstellen
Nur eins oder zwei kann ich mir vorstellen. Travis CI benutzt simdock nicht. Simdock ist auch keine Qt-Anwendung. Electron passt sicher auch nicht, wir sind am anderen Ende des Stacks. Ein AppDir manuell zu erstellen wäre zum einen dauerhafte zusätzliche Arbeit (und die Aktion soll mich ja auf Dauer entlasten, nicht belasten), die Anleitung existiert aber auch nicht. Sie sei verschoben nach https://github.com/AppImage/docs.appimage.org/blob/master/source/packaging-guide/manual.md, das wirft einen 404. Wenn ich mich aber nicht vertue müsste ich dafür Binärpakete des Programms und der Abhängigkeiten von einer möglichst alten Distribution wie Ubuntu 14.04 besorgen, das wäre keine Option.
Der Verweis zu OBS führt mich zu https://github.com/AppImage/AppImageKit/wiki/Using-Open-Build-Service. Dort steht auch, dass Inhalt verschoben wurde, nach https://github.com/AppImage/docs.appimage.org/blob/master/packaging-guide/obs.md. Aber das ist auch nur ein weiterer 404. Immerhin, der Link zum OBS-Buildservice führt mich auf diese Seite:
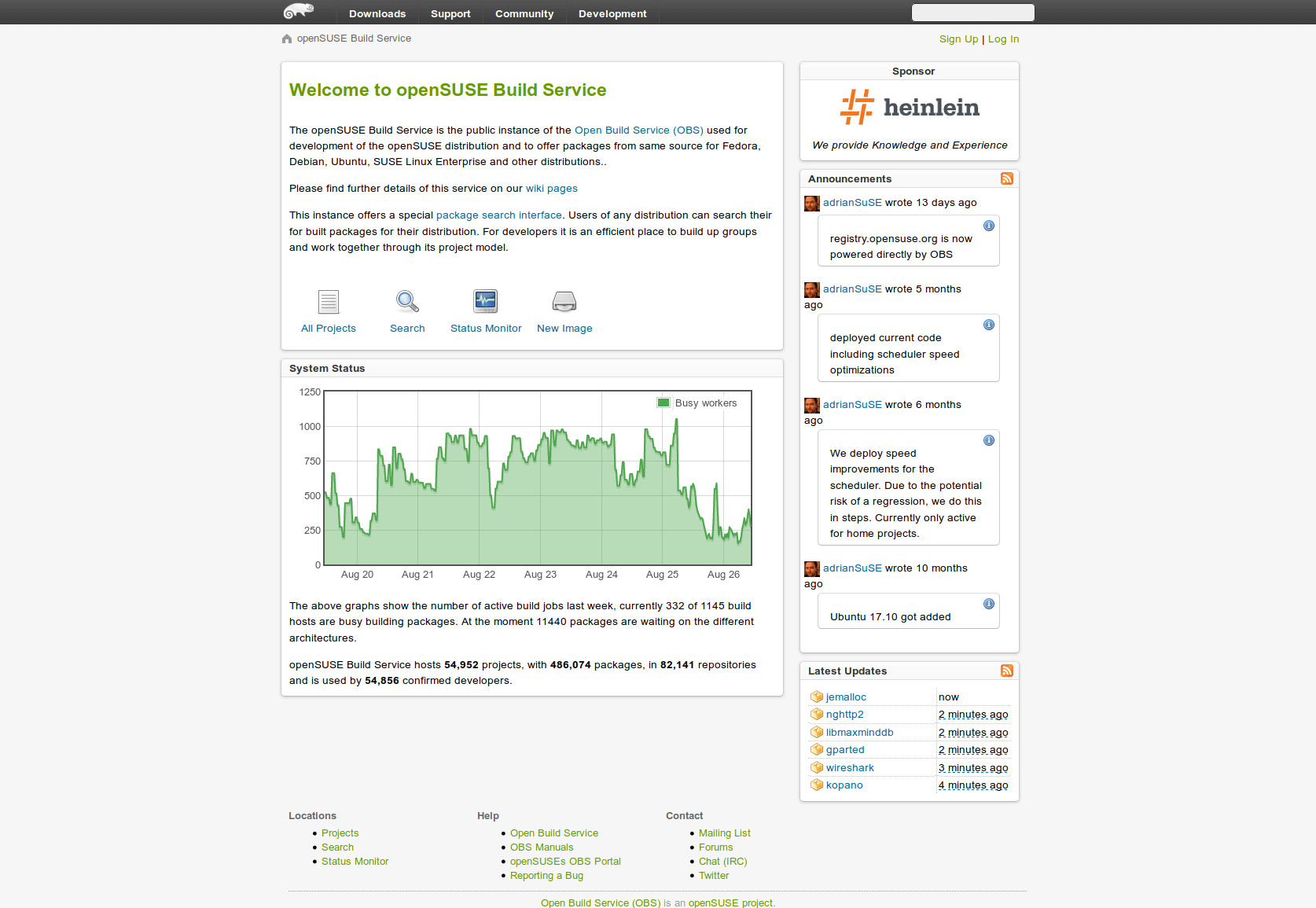
Aber das hilft mir nicht viel. Es ist mir überhaupt nicht ersichtlich, was ich dort tun kann. New Image vielleicht, obwohl ich nicht damit gerechnet hätte, dass die Funktion im OBS schon so heißt, und obwohl das Icon nicht wie der primäre Button der Seite aussieht. Dort kann ich dann auch tatsächlich AppImage als Template(?) auswählen, und unten meiner Appliance (ich dachte ich erstelle ein Image?) einen Namen geben. Der Button unten Create Appliance bleibt aber weiterhin ausgegraut. Das funktioniert also gar nicht.
Und ich glaube, ich scheiterte vor Jahren schon einmal an OBS, daran dass die Webseite einfach völlig kaputt war. Ich glaube das war, als ich dann stattdessen auf Launchpad ein PPA für simdock erstellte.
Bleibt der zweite Weg: Das Erstellen eines AppImages über das bestehende Paket. Da ich ein ppa mit .debs habe sollte das ja auch der einfachste Weg sein. Tatsächlich führt mich die Anleitung aber nur zu einem Bash-Script, ohne Erklärung wie es zu benutzen ist. Und zu Beispielen von yaml-Dateien, mit denen man wohl das Skript konfiguriert. Hier das von Geany, das sieht immerhin einfach aus und benutzt ein PPA. In dem Repo gibt es dann auch doch noch ein Beispiel dafür, wie man das Skript benutzt:
bash -ex ./pkg2appimage recipes/XXX.yml
Also habe ich das Geany-yaml genommen, auf simdock umgebogen, und den obigen Befehl ausgeführt. Das war das Ende der Ausgabe:
++ grep -e '^http' ./pkg2appimage: line 250: apt-get: command not found + URLS=
Das kann nicht gehen, ich habe weder Debian noch Ubuntu auf dem Rechner, natürlich findet es apt-get nicht.
Meine versuchte Erstellung eines AppImage für simdock war zu diesem Zeitpunk also erstmal gescheitert.
Warum das Steckenbleiben an diesem Punkt schade wäre
Bei seinem Vortrag hat probono viel davon geredet, dass Windows und MacOS eine Sache besser machen als Linux: Dort ist das Betriebssystem eine relativ stabile Plattform, sodass einmal darauf ausgelegt Programme fast dauerhaft dort laufen. Unter Linux dagegen müssen Programme sich immer wieder der sich ändernden Umgebung anpassen, vor allem, wenn ihr Quellcode nicht verfügbar ist (aber nicht ausschließlich nur dann, wie ich auch selbst mit simdock mehrfach schon erfahren musste). AppImage will das ändern, es ist als Erleichterung für Anwendungsentwickler gedacht. Aber in meiner Erfahrung funktioniert genau das eben nicht: AppImage erfordert von mir viel Arbeit, und es sieht absolut nicht einfach aus. Wo ist der Service, der ein Git-Repo nimmt, die Abhängigkeiten aus dem Makefile zieht, das Programm kompiliert und das Ergebnis als Makefile verpackt?
Stattdessen war ausgerechnet der klassische Weg in manche Distros einfach: Um das Programm nach Arch zu bringen musste ich gar nichts machen, ein Nutzer erstellte das PKGBUILD. Bei izulu – einem anderen Programm von mir – war es auch ein Nutzer, der es nach AUR packte. Ich weiß, dass es sehr einfach ist, für Gentoo ein overlay zu erstellen und es so verfügbar zu machen. Nur in die großen Distros komme ich mangels Popularität des Programms nicht, ohne mir Unmengen an Arbeit aufzuhalsen. Das Problem liegt also vor allem an Distributionen wie Debian, bei denen ich den Maintainer spielen müsste und zudem als Bittsteller auftreten würde, um in das Repository zu kommen.
Deswegen ist die Komplexität hinter AppImage schade: Ich würde mit sehr gerne davon helfen lassen, dann über AppImage wie per AUR meine Pakete in Distros verteilen können. AppImage scheint dafür aber derzeit der falsche Weg zu sein. Vielleicht liegt das an dem Fokus auf Binärpakete. Die zu vereinfachen, das scheint das große Ziel zu sein. Dafür will es Stabilität in den Library-Wirrwarr zu bringen, der im Vortrag auch sehr überzeugend gezeigt wurde. Meiner Erfahrung nach aber funktioniert in der Praxis aber nur der umgekehrte Ansatz: Mache es einfach, Quellcode zu kompilieren und direkt in die Distrospezifischen Pakete zu verpacken. Das erschlägt dann ebenfalls den Library-Dschungel, weil einfach immer der Quellcode entsprechend neu kompiliert wird.
Travis CI zur Rettung
Bevor ich diesen Artikel veröffentlichte habe ich mit den Leuten von AppImage Kontakt aufgenommen. Der einfachste Weg ging wohl an mir vorbei: Travis CI. Es ist einfacher als ich dachte bei jedem Commit den Kompilierungsvorgang zu starten, und AppImage kann sich hier reinhängen. Dann wird bei jedem Commit nicht nur automatisch das Programm erstellt, sondern auch das AppImage. Ich glaube allerdings nicht, dass ich ohne weitere Hilfe zurechtgekommen wäre, denn die Dokumentation ist auch dafür schwach (dafür weiß ich jetzt, dass eine neue Dokumentation gerade aufgebaut wird). Diese .travis.yml war der Startpunkt für Simdock:
language: cpp
compiler: gcc
sudo: require
dist: trusty
install:
- sudo apt-get -y install pkg-config libglib2.0-dev libgconf2-dev libgtk2.0-dev libwnck-dev libwxgtk3.0-dev libxcb1-dev libxcb-ewmh-dev xcb-proto librsvg2-dev
script:
- make -j$(nproc)
- make install DESTDIR=$(readlink -f appdir) ; find appdir/
- mkdir appdir/usr/share/applications/ ; cp simdock.desktop appdir/usr/share/applications/
- mkdir appdir/usr/share/icons/hicolor/256x256/apps ; touch appdir/usr/share/icons/hicolor/256x256/apps/simdock.png # FIXME
- wget -c -nv "https://github.com/probonopd/linuxdeployqt/releases/download/continuous/linuxdeployqt-continuous-x86_64.AppImage"
- chmod a+x linuxdeployqt-continuous-x86_64.AppImage
- unset QTDIR; unset QT_PLUGIN_PATH ; unset LD_LIBRARY_PATH
- export VERSION=$(git rev-parse --short HEAD) # linuxdeployqt uses this for naming the file
- ./linuxdeployqt-continuous-x86_64.AppImage appdir/usr/share/applications/*.desktop -appimage
after_success:
- find appdir -executable -type f -exec ldd {} \; | grep " => /usr" | cut -d " " -f 2-3 | sort | uniq
- bash upload.sh Simdock.AppImage
branches:
except:
- # Do not build tags that we create when we upload to GitHub Releases
- /^(?i:continuous)/
Ich glaube, hier muss das Projekt noch arbeiten: Erstens die Dokumentation dafür verbessern, und zweitens vielleicht auch einen Weg finden, diese Integration mit weniger Code umzusetzen. Denn als Lösung ist dies ja nahezu perfekt: Sich in Travis CI zu integrieren bedeutet, sich in den Github/Gitlab-Entwicklungsflow zu integrieren. Läuft das einmal muss der Entwickler darauf kaum noch achten und es werden trotzdem immer aktuelle AppImages für das Projekt erstellt. Aber es ist noch ein bisschen viel Voodoo.
Nun rödelt Travis, die Warteschlange ist gerade voll. Wahrscheinlich kommt aus dieser Aktion aber ein funktionierendes AppImage für simdock heraus. Ich bin gespannt, ob das Programm dann auch tatsächlich funktioniert. Unter Ubuntu 14.04 habe ich es lange nicht getestet, und das wäre hier die Basis.
Es hat sich gezeigt, dass die Technik selbst funktioniert. Aber dass das Projekt noch an seiner Dokumentation arbeiten muss. Die notwendigen Kompetenzen um AppImage als Lösung zu etablieren scheinen definitiv vorhanden zu sein. Ich drücke die Daumen, und versuche mein AppImage für simdock beizubehalten.
Steam mit integriertem Wine-Support ist ein Riesenschritt für Linux
Wednesday, 22. August 2018
 Valve hat heute die Beta von Proton aktiviert (via). Proton ist ein (ebenfalls freier) Port von Wine und nutzt dazu DXVK, es ist also eine Software, mit der man Windowsanwendungen unter Linux starten kann. Bisher war es ja so, dass nur Linux-Ports mit Steam installierbar waren. Nicht alle waren echte Ports, man denke an Witcher 2. Aber es waren dedizierte Linuxversionen, wovon es deutlich weniger als reine Windowsspiele gibt.
Valve hat heute die Beta von Proton aktiviert (via). Proton ist ein (ebenfalls freier) Port von Wine und nutzt dazu DXVK, es ist also eine Software, mit der man Windowsanwendungen unter Linux starten kann. Bisher war es ja so, dass nur Linux-Ports mit Steam installierbar waren. Nicht alle waren echte Ports, man denke an Witcher 2. Aber es waren dedizierte Linuxversionen, wovon es deutlich weniger als reine Windowsspiele gibt.
Proton wird diese Situation ändern, da durch diese Software auch reine Windows-Spiele unter Linux laufen. Das wird nicht mit jedem Spiel funktionieren, und dass die so behandelten Spiele schneller als unter Windows laufen wird auch nicht die Regeln sein. Aber es vergrößert die Spielauswahl unter Linux, potentiell enorm. Noch dazu soll gerade DXVK hervorragend funktionieren. Ich habe es noch nicht selbst getestet, aber die Berichte über damit laufende Spiele waren beeindruckend.
Proton wird nicht auf gut Glück für alle Windowsspiele aktiviert, sondern Valve hat einige Spiele ausgewählt. Das ist die Anfangsauswahl:

Ich sage seit Jahren: Damit Linux auf dem Desktop gegen Windows bestehen kann braucht es Unterstützung für die kommerziellen Computerspiele. Es ist einer der zwei fehlenden Bausteine (der zweite ist arbeitsrelevante Software wie Adobe Photoshop, aber dort sind die freien Alternativen inzwischen hervorragend) für den Desktop. Seitdem hat sich viel getan, es gibt für Pinguinfans eine echte und gute Spieleauswahl. Genug, um Spielern und Linuxern wie mir Windows vollständig zu ersparen. Aber die größte Gruppe an überzeugten Computernutzern sind die Core-Gamer, und für die ist ein fehlendes Call of Duty, Battlefield oder was auch immer gerade angesagt ist ein zu großes Manko, um sich Windows zu sparen.
Natürlich: Wine gibt es schon länger. Und DXVK, das DirectX zu Vulkan umwandelt und so unter Linux lauffähig macht, funktioniert auch außerhalb Steams. Aber erstens hat Valve hier in die Entwicklung investiert, zweitens ist all das nur durch den von Valve getriebenen Push zu besseren Treibern möglich. Und drittens und vor allem geht es nicht nur darum, Spiele mit Arbeit und nur eventuell zum Laufen zu bringen. Sondern es muss komfortabel und zuverlässig funktionieren. Genau das kann die Steamintegration bewirken.
Der Rest des enormen Spielekatalogs soll später getestet und Spiele wo möglich aktiviert werden. Wenn das klappt wie erhofft, wird das eine große Erleichterung für Spielefreunde unter Linux bringen. Und dem Linux-Desktop mittelfristig einen wesentlich größeren Marktanteil.
Auf pc-kombo: Wir bauen einen Heimserver
Tuesday, 21. August 2018
Hilft mesa_glthread Deus Ex: Mankind Divided?
Wednesday, 15. August 2018
Deus Ex: Mankind Divided ist besser als erwartet
Tuesday, 14. August 2018
Es dauerte lange, bis ich Mankind Divided spielen konnte. Erst war es mir zu teuer, dann lief es nicht auf meinem System – der Linux-Port hat eine SSE-Abhängigkeit, die Phenoms disqualifiziert. Ich war aber auch gar nicht zu sehr an dem Spiel interessiert: Zu kontrovers war der Launch mit seinen schlecht gemachten Abzocker-DLCs, aber auch die Kritik an Story und Spieldesign war nicht gerade einladend.
Das letzte Deus Ex ist aber doch ein gutes Spiel geworden.

Sicher, es hat einige Macken, und ich werde mit ihnen anfangen. Viele der Grundprobleme waren schon in Human Revolution, treten aber im neuen Teil voll zutage. Da wäre zum Beispiel die Hintergrundstory. In Human Revolution war der Spalt in der Gesellschaft noch halbwegs nachvollziehbar, aber vor allem die Begeisterung für Augmentierungen war unrealistisch. Kann sich jemand wirklich vorstellen, dass in zehn Jahren große Teile der Gesellschaft sich freiwillig Arme und Beine abhacken und mit mechanischen Geräten ersetzen? Und dann noch für immer von einer teuren Droge abhängig sind? In Mankind Divided ist die Stimmung gegen Augmentierungen gekippt und dieser Aspekt des Spielweltuniversums ausgeblendet, stattdessen ist die Gesellschaft noch gespaltener. Das wird übertrieben, das Verhältnis der Gesellschaft zu Augmentierten ist so offensichtlich eine Analogie für Rassismus, samt Apartheid und Segregation, dass es nur in ganz wenigen Momenten realistisch wirkt. Warum machen die neue Spiele das so viel schlechter als der erste Teil mit seinen einfachen und doch schlüssigen Verschwörungstheorien?

Es hakt auch etwas an der Spielerführung. Mankind Divided spielt zum größten Teil in Prag. Die Stadt ist in Sektoren aufgeteilt, verbunden mit der Metro, mit ziemlich langen Ladezeiten. Eigentlich ist Prag gut gemacht: Mehr noch als in den Stadt-Hubs des Vorgängers sind hier viele Nebenquests, Händler und Geschehnisse verteilt. Der Spieler sollte also viel Zeit damit verbringen, all das zu entdecken. Stattdessen aber drängt das Spiel über die Hauptstory dazu, genau das eben nicht zu tun, sondern schnellstmöglich die Verschwörung aufzudecken. Gerade am Anfang überfordert das völlig, wenn erst die Augmentierungen nicht funktionieren, dann korrupte Polizisten den Hintereingang zum Reperaturort blockieren und so die Erledigung eines Nebenquests erzwingen, und gleichzeitig Miller – der neue Chef – über das Interlink mehrfach befiehlt endlich auf der Arbeit aufzutauchen. Er hört dann zwar mit einem "Okay, komm wenn du kannst" damit auf, aber eine richtige Atempause um den Nebenquests zu folgen gibt das Spiel nicht. Die muss der Spieler sich nehmen und dafür negative Konsequenzen befürchten.

Außerdem sind viele Aspekte der Story sind völlig vorhersehbar. Natürlich stimmt mit der Psychologin was nicht, deren Charaktermodell besonders hübsch ist und die einfach zu nett mit Jensen redet. Immerhin merkt der das zwischendurch selbst. Aber warum kann ich dann das nächste Gespräch mit ihr nicht entsprechend schroff führen, sie abweisen und ignorieren?
Nebenbei: Die Psychologin ist vor allem deshalb wahrnehmbar hübsch, weil viele andere Personen komisch aussehen. Die Gesichter auch, aber vor allem die Körperformen. Besonders bei leichtbekleideten Frauen ist auffällig, dass da mit den Brüsten und der ganzen Körperform etwas nicht stimmt. Davon abgesehen ist die Grafik gut, aber das Spiel fordert viel zu viel Leistung von Prozessor und Grafikkarte. So gut ist die Grafik dann doch nicht, zumindest nicht auf den Einstellungen die mein System schafft. Witcher und Human Revolution (unter Windows zumindest) machten das besser.

Nochmal zur Vorhersehbarkeit. Es gibt einen Nebenquest, in dem eine Frau ermordet und ihre Augmentierungen entfernt wurden. Nach zwei Minuten mit der Zeugin sage ich mir "Mit der stimmt was nicht, sie ist sicher der Mörder." Direkt danach wird ein Serienmörder mit Augmentierungen ins Spiel gebracht, der aber im Gefängnis gestorben ist. "Über Augmentierungen lebt der Mörder in der vermeintlichen Zeugin weiter", sage ich mir. Natürlich war es dann auch praktisch genau so. Manchmal kann so etwas okay sein, wenn der Spieler dann auch entsprechend der Offensichtlichkeit handeln kann, man denke an den bombenlegenden Mechaniker im ersten Deus Ex. Hier aber musste dann noch Unmengen erledigt werden: Eine Polizeistation durchsuchen (samt verräterischen Emails der psychisch instabilen Frau, die unkommentiert bleiben), zwei andere Verdächtige entlasten, den Quest erstmal abhaken, dann später ihre Wohnung durchsuchen, mit einem an den Experimenten beteiligten Psychologen reden, in die Kanalisation steigen und dann den Quest auf einem von drei verschiedenen Wegen beenden. All das, obwohl nach zwei Minuten die Sache völlig klar war.
Es hilft auch nicht, wenn im Ladebildschirm mir Eigenschaften von Personen verraten werden, die erst kurz darauf in der Handlung eine wichtige Rolle spielen werden, und diese Eigenschaft offensichtlich eine Überraschung sein sollte. So passiert beispielsweise bei der Identität der Mutter des Maschinengott-Kultes.

Und doch hat mir Mankind Divided viel Spaß gemacht. Vor allem liegt das an den vielen Lösungsmöglichkeiten. Das macht es eigentlich noch besser als die beiden Vorgänger (und auch besser als der Konsolenfork Invisible War). Schleichend, hackend, schießend, durch Gespräche – die Quests lassen wirklich immer viele Lösungsmöglichkeiten zu. Die Spielwelt ist hervorragend darauf ausgelegt, alle möglichen Spielstile und aktivierten Augmentierungen zu unterstützen, ohne dass die alternativen Wege zu künstlich platziert wirken. Nichtmal die Bosskämpfe ändern daran etwas, denn sie können alle ohne tödliche Gewalt gelöst, alle sogar umgangen werden. So war direkt mein erster Spieldurchlauf pazifistisch. Mankind Divided ist das erste Deus Ex, das diese Spielstilfreiheit direkt richtig macht!
Adam Jensen hat eine Reihe neuer möglicher Augmentierungen. Ich fand sie teilweise etwas redundant: Jetzt gibt es eben zwei Schilde, und mehrere Möglichkeiten ohne Waffen aus der Ferne Gegner auszuschalten. Aber es sind auch ein paar nette Ideen darunter, wie der Dash. Insgesamt fand ich die Augmentierungen wieder ziemlich cool, sie geben durch die gute Unterstützung des Leveldesigns dem Spieler irre viele Möglichkeiten. Gerade im Vergleich zum ersten Teil hat sich die Serie hier sehr gut entwickelt, als viele der Augmentierungen noch nutzlos waren. Und so schafft es das Spiel wunderbar, dass der Spieler langsam immer mächtiger wird – sogar wenn man wie in meinem Fall gar nicht kämpft.
Mir hat auch die Hauptstory gefallen. Trotz den oben erwähnten Plausibilitätsproblemen des Szenarios ist die Geschichte selbst spannend, die Verschwörung mysteriös und fesselnd genug. Besonders die Rolle Jensens in TF29 und seine Verbindung zum Juggernaut-Kollektiv ist interessant und passt wunderbar zu Deus Ex. Der Kniff im Abspann lässt da auch für den Nachfolger hoffen, auf dass der große Storyrahmen noch richtig spannend wird. Ich hatte auch kein Problem mit dem Punkt, an dem das Spiel aufhört. Vielen ist wohl das Ende übel aufgestoßen, denn anders als in den Vorgängern gibt es bei Mankind Divided noch einige klar gestellte, aber ungelöste Fragen. Doch ich fand das okay, denn die erlebte Story ist eine komplette Geschichte mit spannendem Anfang und zufriedenstellendem Ende. Dass da offensichtlich noch mehr kommen soll verleidet mir das nicht. Das würde ich vielleicht etwas anders sehen wenn es wirklich keinen Nachfolger geben sollte, aber diese Gerüchte waren glücklicherweise wohl falsch – eigentlich offensichtlich, wer würde so doof sein und eine so beliebte und auch kommerziell erfolgreiche Spieleserie nicht weiterführen wollen.

Technisch bin ich mit der Linuxversion nicht ganz zufrieden. Es ist zwar an sich schon toll, dass ein solches AAA-Spiel unter Linux läuft. Ohne Grafikfehler, ohne Pulseaudio-Abhängigkeit, mit funktionierendem Sound. Aber dass es mit Phenoms nicht startet ist eigentlich inakzeptabel, diese alten 6-Kern-Prozessoren sind gerade in Spielen kaum schwächer als die FX-Prozessoren, die ja durchaus unterstützt werden. Ich hatte gelegentlich Abstürze, manchmal frierte das Bild ein. Alle Ladezeiten sind zu lang, besonders der erste Start, aber auch das Wechseln des Stadtgebietes per Metro (und dabei war es schon auf einer schnellen SSD installiert). Die FPS könnten besser sein. Meine Hardware ist wohl etwas zu alt für das Spiel, das muss ich akzeptieren, finde aber, dass dafür die Grafik nicht ausreichend gut aussieht. Wahrscheinlich haben die Entwickler hier einfach kompliziertere und vollgepacktere große Gebiete umgesetzt, die in Human Revolution so noch nicht möglich waren – wobei die höheren Einstellungen doch wirklich deutlich besser aussehen als der Vorgänger, der das nur mit seinem Goldschleier etwas kaschierte.
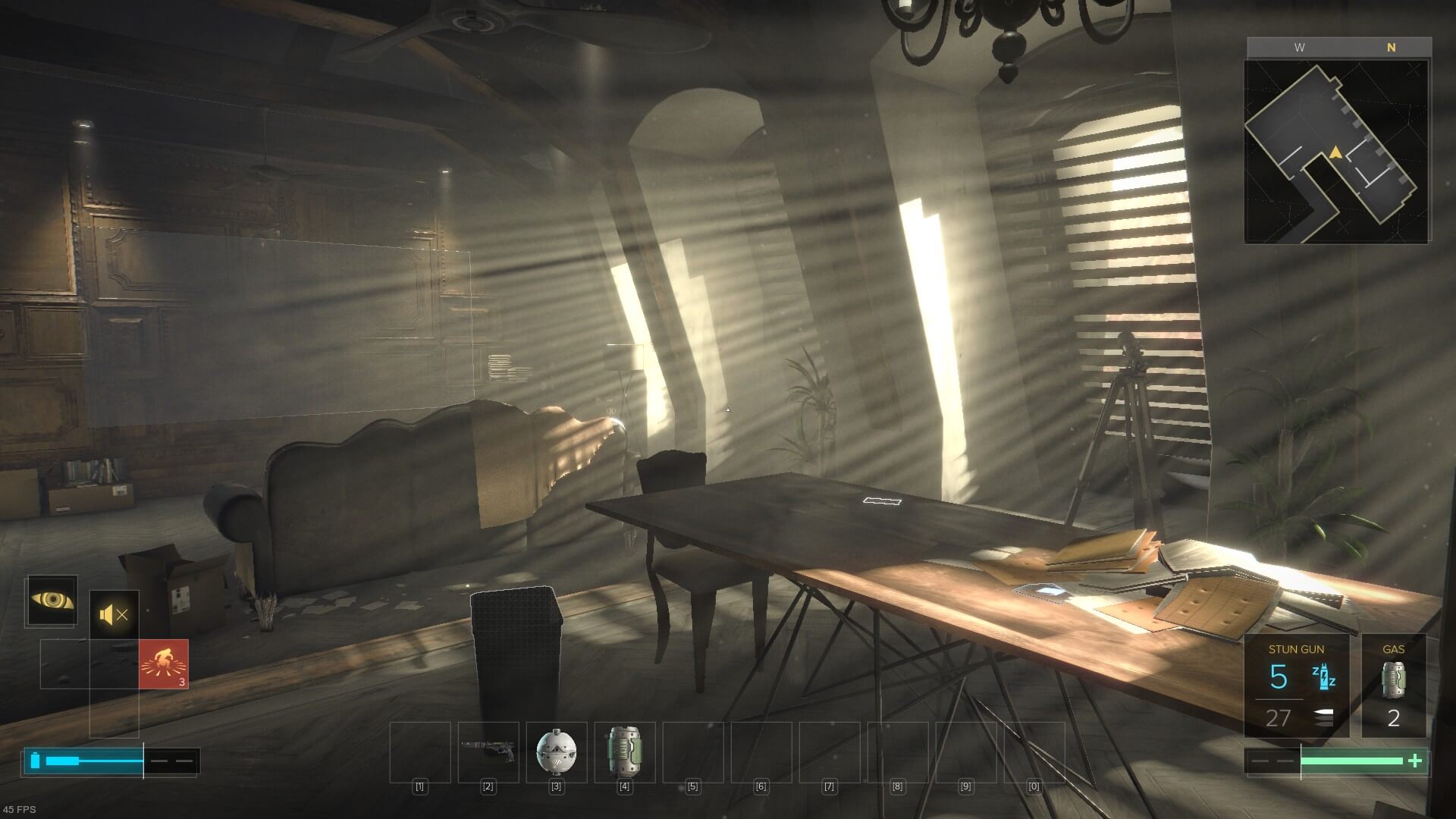
Mankind Divided ist ein gutes Deus Ex geworden. Viele Handlungsmöglichkeiten, gute Story, interessante Charaktere. Ich habe es jetzt nochmal angespielt und muss sagen, dass auch der Shooter-Teil des Spiels gut geworden ist, den ich ja in meinem ersten Stealth-Durchlauf nicht erlebt habe. Natürlich kann es den ersten Teil nicht erreichen, und es hat nicht alle Stärken seines direkten Vorgängers, wie den einzigartigen visuellen Stil. Aber es hat seine eigenen Stärken, zu denen ich sogar die Handlung zählen würde, auf jeden Fall aber die Auflistung der Konsequenzen der eigenen Entscheidungen am Ende, die Unterstützung verschiedener Spielstile, das vollgepackte Prag mit seinen Nebenquests. Am Ende überzeugte mich besonders die finale Mission, die im Grunde Jensen als klassischen Geheimagenten einsetzt, was hervorragend zu Deus Ex passt und doch noch nie in der Serie umgesetzt wurde.
Mankind Divided bietet Fans der Serie also richtig viel. Du solltest es spielen.
Torment: Tides of Numenera ist ein echtes Rollenspiel
Monday, 6. August 2018
Ich habe Planescape: Torment vor vielen Jahren durchgespielt, nachdem ich mich von der Idee verabschiedet hatte, ausgerechnet dieses textlastige Spiel als Übung auf Französisch zu spielen. Ich erinnere mich vage an die Story um den namenlosen Unsterblichen, an den fliegenden Skelettschädel. In meiner Erinnerung war das Kampfsystem schwach, es gab wirklich sehr viele Text, ich hörte nebenbei Metal und die Geschichte in diesem sehr anderem Universum war irritierend, besonders das Ende.

Torment: Tides of Numenera ist ein spiritueller Nachfolger zu Planescape: Torment. Hat der Nachfolger schon einen sehr seltsamen Namen, stiftet noch etwas zur Verwirrung bei: Fast gleichzeitig mit dem spirituellen Nachfolger wurde der Vorgänger in einer überarbeiteten Version neu aufgelegt. Sehr viel Interesse also für dieses alte Rollenspiel, das zwar als eines der Genregrößen gilt, aber schon damals verwirrend und wenig zugänglich war. Und doch ist es wohl eine der besseren Vorlagen für diese Renaissance der Computer-Rollenspiele.
Tides of Numeneria nimmt viel von dem Vorgänger auf. Der Hauptcharakter ist kein gewöhnlicher Spielecharakter, die Begleiter sind etwas absurder als in anderen Rollenspielen, es gibt mehr Texte und Entscheidungen als üblich. Besonders aber ist es eben noch ein Spiel alter Schule: Praktisch 2D und so weit wie möglich entfernt von den actionlastigen modernen RPGs wie Mass Effect.
Wieder ist der Spielercharakter ein Gotteskind und beginnt ohne Erinnerung, nachdem er (oder sie) gestorben ist. Diesmal aber stürzte er vom Himmel. Man begegnet nach dem Aufwachen direkt zwei möglichen Begleitern und startet mit dem ersten Quest im Logbuch.
Typisch für das Spiel ist die Folgesituation: Schatzsucher kommen angerannt, angelockt vom Himmelssturz. Die kann man nun im rundenbasierten Kampf ausschalten, dabei die in der Umgebung verteilten Artefakte nutzen. Alternativ lügt man sie an, überzeugt sie so, dass der Schatz in einem anderen Bereich der Karte ist. Oder man schüchtert sie ein. Für diese Gesprächsfähigkeiten können die drei Fähigkeitspools – Macht, Geschwindigkeit, Intelligenz – genutzt werden, die sich so aber auch bis zur nächsten Rast verbrauchen. Auch in Kämpfen werden diese Pools benutzt, selbst zum Aufladen normaler Schläge, man sollte also gut haushalten.
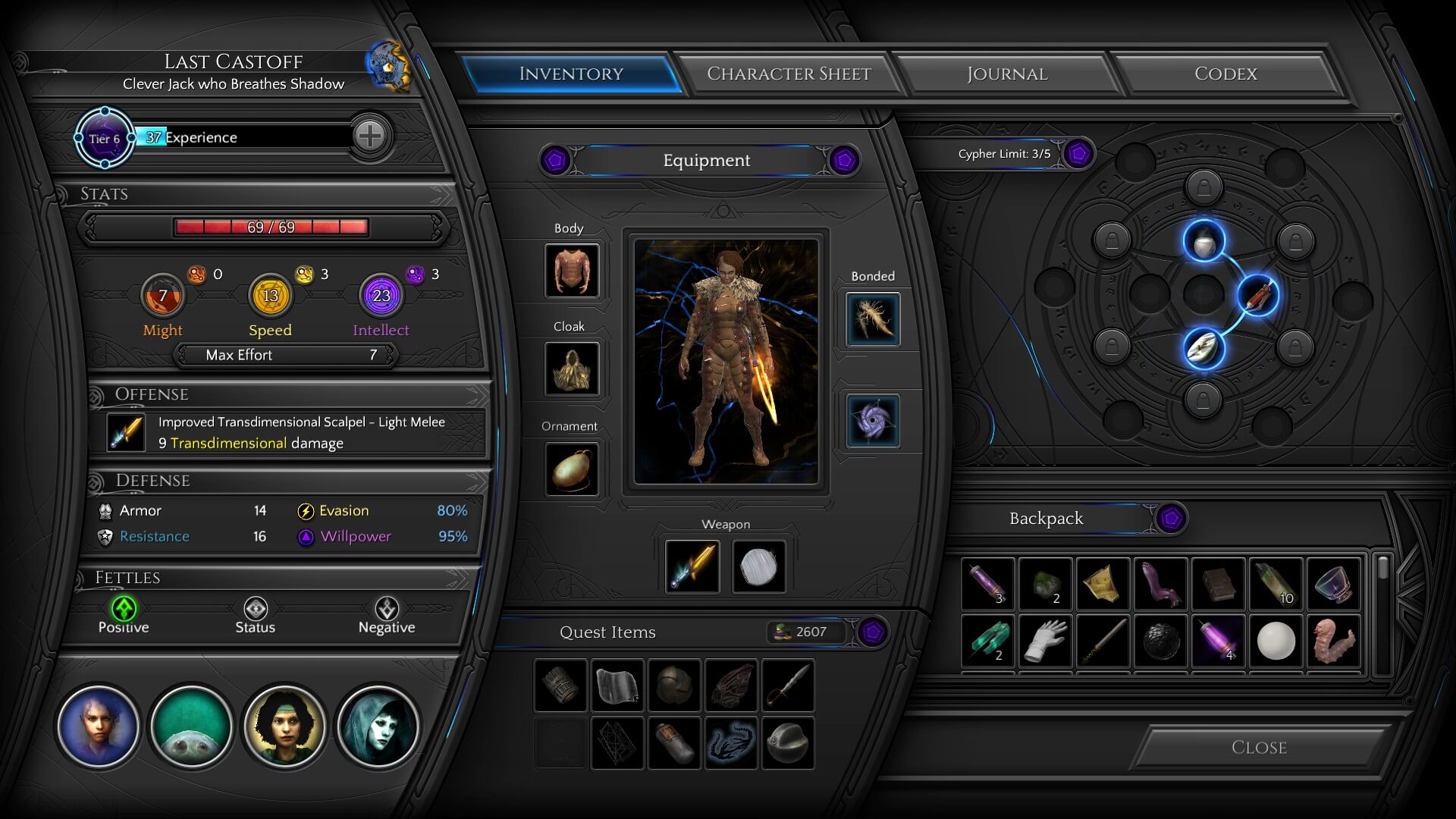
Das Verhalten in Gesprächen bestimmt auch das Karma. Da gibt es nicht gut oder böse, sondern mehrere farbkodierte Ausprägungen, von denen zwei zugleich aktiv sein können. So steht Gold für Selbstlosigkeit, Silber für Standesbewusstsein, Blau für Interesse an Wissen. Auf dieses Karma reagieren die anderen Menschen und es gibt einen Begleiter, der sogar darüber Boni auswählt. Zudem können in manchen Gesprächen bestimmte Optionen nur Dank des richtigen aktiven Karmas gewählt werden. Doch leider erklärt das Spiel das Karmasystem schlecht und zeigt nur selten seinen Einfluss, wodurch die Funktion schwächer ausgebaut wirkt als sie eigentlich ist.
Es ist ein echtes Rollenspiel, also gibt es Erfahrungspunkte und Levelaufstiege. So kann der Charakter stark spezialisiert werden, auf Kampffertigkeiten oder einem defensiverem Spielstil. Das entscheidet auch mit welchem Fähigkeitspool er hauptsächlich arbeitet. Kämpfe können oft vermieden werden, ich glaube aber nicht immer; das zu widerlegen und pazifistisch zu spielen wäre vielleicht eine interessante Herausforderung.
Typisch: Es gibt ein Artefakt, mit dem Gedanken lesbar werden und so andere Gesprächsoptionen möglich sind. Versteckt ist das im letzten Spielabschnitt bei einem einzigen Händler. In einem normaleren Rollenspiel wäre so etwas Teil der regulären Fähigkeiten, man denke an den Gesprächsanalysator per Implantat in Deus Ex: Human Revolution. Numenera dagegen versteckt so etwas zum Spielende in einem abgelegenen Winkel. Auch andere Boni sind immer wieder in der Spielwelt verteilt, gerade Attributssteigerungen nicht auf das Aufleveln beschränkt. Das ist so seltsam irregulär wie der Vorgänger und lockert das Spiel auf, macht es aber auch nicht gerade zugänglicher.

Die Hauptstory hat mir gut gefallen. Ohne zuviel verraten zu wollen: Der vermeintliche Schöpfer des Protagonisten spielt noch eine wichtige Rolle und es gilt große Entscheidungen zu treffen, welche die ganze Welt beeinflussen werden. Diese Geschichte wird direkt am Anfang eingeführt und verliert sich auch nicht im Spielverlauf. In der Hinsicht ähnelt es Pillars of Eternity, mit dessen Engine das Spiel auch umgesetzt wurde. Leider teilt es sich dabei dessen Problem: Für eine so episch angelegte Story sind die 26 Stunden Spielzeit zu kurz. Zu dem Zeitpunkt lebt der Spieler noch nicht völlig in dieser Welt. Wobei Numenera doch sehr viel richtig macht, um den Spieler trotz der relativen Kürze so stark wie möglich in die Spielwelt eintauchen zu lassen.
Ein Teil davon und sehr schön gelungen sind manche der Nebenquests und auch die Hintergrundgeschichten der Begleiter. Eine will ich teilweise erzählen: Die von Erritis. Den von einem goldenen Schimmer umgebene Kämpfer findet man in der Stadt neben einem abgestürzten Luftschiff, was absolute Verwunderung auslöst, denn die Dinger seien nahezu unmöglich zum Absturz zu bringen. Erritis stürzt sich in jeden Kampf, aber was die Realität und was Gefahren sind scheint er nicht zu überblicken. In mehreren Situationen kann er den Tod der Gruppe verursachen, in dem er die dümmstmöglichste Aktion wählt, dann muss man neu Laden. Er scheint von etwas getrieben zu sein, wovon wird man natürlich wird im Laufe der Geschichte erfahren.
Numenera lebt auch von solchen Geschichten und von seiner ungewöhnlichen Hintergrundgeschichte. Die Welt ist nicht einfach eine magische, sondern eigentlich eine SciFi-Welt. In der aber sind so viele Zivilisationen vergangen, dass die verbliebenen Artefakte wie Magie wirken – und es gibt auch Effekte, die im Kanon der Welt magisch sind, nicht technisch, aber oft ist das gar nicht klar entscheidbar. Die Spielwelt ist über diesen riesigen Hintergrund von vielen vergangenen und auch parallel noch bestehenden Zivilisationen aufgebaut, was viele ungewöhnliche Szenarien erlaubt. Das Spiel hat so angenehmerweise keinen Grund, auf die Klischees der Hochfantasie mit edlen Elfen in Wäldern und bösen Orks zurückzugreifen.
Ich habe Tides of Numenera sehr gerne gespielt. Vielleicht spiele ich es sogar nochmal, um die Auswirkungen alternativer Handlungen zu sehen. Die Linuxversion lief an sich hervorragend, nur der Sound hatte ein Knattern, das scheint aber kein übliches Problem zu sein. Die Karten sehen wieder hübsch aus und es ist ein fesselndes Rollenspiel geworden, das sehr viele verschiedene Möglichkeiten bietet. Selbst die Kämpfe fand ich gut gelungen, sie sind gewinnbar und doch fordernd, mit den Fähigkeiten der Charakteren sind sie kein stumpfes Hauen und Stechen, aber es wird auch nicht übermäßig komplex.
Ich verstehe aber auch, dass Tides of Numenera nicht jedem gefallen kann: Zu absonderlich ist die Welt, zu altbacken der Spielablauf, und wie bei Pillars of Eternity fehlt da noch etwas, um die Großen des Genres zu erreichen. Aber keinesfalls ist es schlecht. Es sei hiermit jedem empfohlen, der gerne noch ein neues klassisches Computer-Rollenspiel erleben will. Diesmal in einem etwas anderen Universum.

