Mein Rückblick aufs Studium, Teil 1: Bachelor Informatik TU Darmstadt
Monday, 27. September 2021
![]() Ich habe viel Zeit an der Uni verbracht, darüber aber hier nur selten geschrieben. Mittlerweile arbeite ich seit ein paar Jahren und das Studium wird mehr und mehr eine ferne Erinnerung. Zeit, ein paar Erfahrungen festzuhalten.
Ich habe viel Zeit an der Uni verbracht, darüber aber hier nur selten geschrieben. Mittlerweile arbeite ich seit ein paar Jahren und das Studium wird mehr und mehr eine ferne Erinnerung. Zeit, ein paar Erfahrungen festzuhalten.
Der Start war ein Informatikstudium an der TU Darmstadt, das ich vor fast genau einer Dekade abgeschlossen habe. Es war nur ein Bachelorstudium, den Master machte ich anderswo. Die Rahmenbedingungen waren gut: Die TU galt als gute Uni. Auch wenn es noch Diplomstudenten gab – einer davon wurde unser D&D-Dungeonmaster – war der Umstieg vom Diplomsystem mittlerweile fertig, es gab auch keine Wahl mehr, das schuf Fakten und Klarheit. Unsicherheit kam von den asozialen Studiengebühren, doch die wurden mir im ersten Semester erlassen und im zweiten dank Ypsilanti ganz abgeschafft. Das Studium selbst war von Seiten der Universität ziemlich toll organisiert, aber es war viel Arbeit und die Zeit insgesamt für mich ziemlich chaotisch.
Der Ablauf des Studiums
Da es keine Zulassungsbeschränkung gab saß ich am Anfang des Studiums mit sehr vielen anderen neuen Studenten in völlig überfüllten Hörsälen. Am schlimmsten war da Mathe 1, da passten die Leute nichtmal mehr auf die Stufen neben den Stühlen. Das blieb natürlich nicht so: Es würde mich sehr wundern, wenn mehr als 50% das Studium abgeschlossen haben, zudem sparten sich bald selbst viele die weitermachten die Vorlesungen.
Die Übungen waren sowieso wichtiger: In ihnen kam der Stoff vor, der dann in den Prüfungen getestet wurde. Geleitet wurden diese Übungen meist von Studenten, als Nebenjob. Alle meine Prüfungen waren schriftlich, mündliche Prüfungen gab es in anderen Kursen, aber sie waren selten und galten als schwierig. Bei allen regulären Vorlesungen gab es am Ende stattdessen eine schriftliche Prüfung. Ohne irgendeinen Tests an Scheine zu kommen war mit dem Diplomsystem so ziemlich abgeschafft worden, ging aber noch in Seminaren – da wurde dann eine Präsentation bewertet. Das war natürlich der große Stressfaktor: Dass man durch Prüfungen und nach dreimaligen Scheitern an einer Prüfung sogar durch das ganze Studium durchfallen konnte. Zum Glück blieb mir der Drittversuch erspart, aber nicht alle Prüfungen konnte ich auf Anhieb bestehen. Auch deswegen war es die oben erwähnte chaotische Zeit.
Die Massenvorlesungen am Anfang deckten die Grundthemen ab. Grundlagen der Informatik (GDI), Formale Grundlagen der Informatik (FGDI), Technische Grundlagen der Informatik (TGDI), Mathe. Davon gab es jeweils drei Kurse, nur TGDI blieb bei zweien. Nach den ersten Semestern kamen dann Kanonikfächer hinzu, "Einführung in X" – Computational Engineering, Computer Microsystems, Foundations of Computing, Human Computer Systems, Data and Knowledge Engineering und Net Centric Systems.
Gegen Ende gab es noch Wahlpflichtfächer, wo man sich aus einer Auswahl von Themen die seinen raussuchen konnte, das war die minimale Spezialisierungsmöglichkeit. Bei mir wurde das Kryptographie, Mensch-Computer-Interaktion (HCI) und Künstliche Intelligenz. Man musste ein Bachelorpraktikum abliefern, aber was da die Optionen waren krieg ich nicht mehr zusammen. War das mit der Bachelorarbeit kombiniert? Denn die galt es ganz zuletzt zu schreiben, wobei man dafür noch einen Kurs besuchen konnte und dann mit Kommilitonen den Fortschritt besprach, was sehr hilfreich war.
Studiumsinhalte
Worum ging es jeweils? Ich werde nicht alles durchgehen, will aber einen Eindruck der wichtigsten Inhalte geben.
In GDI ging es ums Bauen von Software. Am Anfang schlicht ums Programmieren: Wir lernten erst Scheme (jetzt Racket, ein LISP), dann Java, programmierten zusammen ein Spiel und lernten über die Komplexität von Algorithmen (O-Notation). Und das war alles GDI 1. An spätere Inhalte erinnere ich mich weniger gut. Ein kurzer Abschnitt wurde in C programmiert. Aber wir müssen auch Stoff über Wasserfallmodelle, Pflichtenhefte, Designpatterns und UML gehört haben – das meiste davon war anders als die erste Vorlesung im Nachhinein irrelevant, aber gut zu wissen dass es das mal gab. Spezielle Algorithmen wie Quicksort kamen später auch vor, das war schon hilfreicher, auch Datenstrukturen wie Bäume waren ein wichtiges und nützliches Thema.
FGDI war Logik. Meine Anleitungen um einen Zustandsautomaten zu mimieren und zum Markierungsalgorithmus stammen daher, ob das nun FGDI 1 oder 2 war ist mir unklar. Anfangs ging es um Grundlagen wie Prädikatenlogik. Ich habe es gehasst, die Artikel landeten im Blog um mir Inhalte ins Hirn zu prügeln und anderen zu helfen. Ich muss aber zugeben, dass es später hilfreich und notwendig war solche formalen Logikausdrücke lesen zu können. FGDI 3 war etwas anders: Da ging es um die Verifikation von Programmen. Die wurden dafür in einer Spezialsprache geschrieben und ihre Richtigkeit musste dann Annahme für Annahme bewiesen werden. Auf der einen Seite absurd komplett nicht praxistauglich, auf der anderen konnte man sich vorstellen, wie das irgendwann doch praxistauglich werden könnte, es hieß sogar Prozessorhersteller würden das bereits machen (und später las ich, sie hätten das größtenteils aufgegeben).
TGDI hasste ich nicht, aber diese technischen Grundlagen hatte ich nie gehabt. Und-, Oder-, XOR-Schaltungen, Verilog und damit irgendwas anfangen – ich schnappte ein paar Grundlagen auf und kam durch die Prüfung. Im zweiten Kurs ging es dann mehr um Prozessorarchitekturen. Ob wir hier oder in GDI in Assembler programmiert haben krieg ich nicht mehr zusammen, aber das war auf jeden Fall spaßig.
Bei Mathe kann ich kaum noch auch nur die Inhalt benennen. Mathe 1 und 2 war ein wilder Mischmasch von irgendwelchen Mathematikkenntnissen – irgendwas mit Reihen, Ableitungen, Beweisen. Mathe 3 war Computation (und Statistik?), also Mathematik vom Computer lösen lassen, was oft andere Ansätze braucht. Das hatte etwas Berechtigung. Aber Mathematik wie es dort zuvor gemacht wurde war ein pures Aussiebefach und vermittelte wenig, was irgendwie hängenblieb oder ich bisher nochmal gebraucht hätte. Teilweise wiederholten sich Inhalte in den spezialisierteren Fächern, die waren dann relevant und gut sie schonmal gehört zu haben, Gruppen beispielsweise. Aber hätte es kein Siebfach gebraucht hätte man Mathe schlicht weglassen und die Inhalte dort lehren können wo sie benutzt wurden.
Bei den "Einführung in X"-Fächern ging es um ganz verschiedene Themen. Bis jetzt lernten wir ja nur allgemeine Grundlagen. Net Centric Systems z.B. konnte dann über Netzwerke und über das Internet reden. Es ging auch darum grob die Forschungsbereiche der Informatik abbilden. Die Wahlpflichtfächer gingen da dann später etwas tiefer, für die, die Interesse an einem bestimmten Thema hatten.
Besondere Inhalte und Lektionen

Besonders prägend war Grundlagen der Informatik. Wegen dem Fach mit seinen Inhalten waren die meisten Studenten in dem Studiengang, mich eingeschlossen. Tatsächlich lernte man dort dann auch viele Konzepte, die für jeden Programmierer völlig relevant sind: Objektorientierte und funktionale Programmierung, Datentypen, Rekursion, Komplexität, aber auch generell das Entwerfen von und Arbeiten mit Algorithmen sowie das Planen von Programmen.
Trotz diesem praktischen Aspekt des Studiums wurde gepredigt, dass ein Informatiker Konzepte lernt und die dann in jeder beliebigen Programmiersprache anwenden kann. Ich merkte später: Das stimmt nur so halb. Um abstrakte Konzepte wirklich anzuwenden muss man die Sprache beherrschen, das braucht Übung mit ihr. Bevor ich Ruby lernte – eigenständig im Master – konnte ich zum Beispiel faktisch kaum Serveranwendungen bauen, völlig egal ob ich die Konzepte drauf hatte. Aber es stimmt, dass sich viel übertragen lässt, und zwischen ähnlichen Sprachen zu wechseln ist kein großes Problem. Es stimmt aber auch der Vorwurf am Hochschulstudium, dass selbst das Bachelorstudium noch zu abstrakt ist um den Studenten wirklich das Programmieren beizubringen. Das müssen sie aus eigenem Antrieb zusätzlich oder später machen, selbst GDI mit seinem Praxisteil schafft nur wenige Grundlagen. Oder zumindest war das damals so.
Was stimmte: Die Predigt vom Dekan ziemlich am Anfang des Studiums, dass er keinen von uns in gewöhnlichen Studentenjobs sehen will, wir seien alle jetzt schon als Programmierer beschäftigbar. Naja, vielleicht galt das nicht für alle, aber tatsächlich waren die Anfangsinhalte die wichtigsten und Firmen hätte mit den motivierteren Studenten definitiv arbeiten können.
Wieviel weiteres nützliches man aus dem Studium ziehen konnte hing aber auch von den Wahlpflichtfächern ab. Meine Themenwahl sehe ich heute noch mit Wohlwollen.
Künstliche Intelligenz war vor dem aktuellen Boom, neuronale Netze ein veraltetes Nischenthema. Trotzdem oder gerade deswegen war die Vorlesung super – denn KI hat im Kern das Thema, das mich an Informatik anfangs so faszinierte, nämlich wie man mit Algorithmen Probleme lösen kann. Der auf einem Infotag präsentierte Dijkstra-Algorithmus, der ein Wegfindeproblem lösen kann, hatte damals erst den Ausschlag gegeben dieses Studium zu wählen. Ich sehe KI als die komprimierte Essenz der Informatik, entsprechend spannend war die Vorlesung. Wobei ich wenig konkrete Inhalte aus ihr bisher anwenden konnte, wohl aber viele Ansätze.
Kryptographie zu belegen war überraschend lohnenswert, weil IT-Sicherheit in jedem Projekt ein Thema ist und die Grundlagen von damals mich immer noch tragen. Zudem war der Professor Johannes Buchmann, der es einfach drauf hatte die Vorlesung interessant und verständlich zu halten. Ich glaube, das war auch die Vorlesung für die ich RSA in Bash implementierte, was ein bisschen zeigt wie locker man das Thema angehen konnte.
Außerdem war HCI ein prägender Kurs zu Usability. Als Informatiker fand ich das besonders toll, weil es einen Weg vorwärts versprach wie man alles andere anwenden konnte. Nicht nur viel wissen, sondern auch herausfinden können was man überhaupt bauen soll und womit Nutzer umgehen können. Damit wollte ich weitermachen, also wurde das Thema mein Masterstudium – was nicht ganz klappte, aber dazu später mal mehr.
Und schließlich, etwas allgemeiner: Diese übliche Prophezeiung, dass im Studium viele gute Leute zusammenkommen und die dann auch oft besser sind als du, in Darmstadt stimmte das für mich. Auch eine Erfahrung.
Leben als Student in Darmstadt

Nach etwas Eingewöhnungszeit wurde das Studieren zum Alltag. Ich besuchte die Vorlesungen fast immer, nahm an den Übungen teil, und füllte die verbliebene Zeit mit anderen Dingen.
Am Anfang hatte ich keine Zeit über, denn anfangs bin ich von meinem Heimatort nach Darmstadt gependelt, was großer Mist war. Dass ich seitdem mit einer kurzen Ausnahme nie wieder gependelt bin ist kein Zufall. Erstens kriegte ich anfangs vom Studentenleben wenig mit, zweitens fühlte ich mich wegen der unsicheren Heimreise in Darmstadt nicht wohl, drittens schadete es der Motivation an den Vorlesungen und Übungen teilzunehmen und damit dem Studium. Gerade kommt mir der Gedanke: Man konnte beides damals nicht von Zuhause machen, vielleicht ginge zumindest die fachliche Seite mittlerweile trotz der Distanz etwas besser?
Später wohnte ich im Studentenheim, das half sehr. Es gab dort aber die absurde Situation, pfeilschnelles Internet zu haben, aber nur 10 oder 20 GB Traffic, danach wurde die Leitung für den Monat abgeschaltet. Ich hoffe, das ist heute Geschichte – ah, sie sind jetzt bei 120GB, das sind immer noch nur 2 AAA-Spiele. Peinlich. Und es half anfangs nicht gerade beim Sicherheitsgefühl in der neuen Heimat.
Studentenjobs an der Uni dagegen waren eine gute Sache für mich. Eine Weile war ich Mentor für Erstsemester, ihr einer Pflichttermin. Diese Tätigkeit hatte abgesehen der üblichen Anliegen der Menties bezüglich mancher Studieninhalte so gar nichts mit Informatik zu tun, das war eine interessante Erfahrung. Später als Tutor in Übungen lernte ich immerhin noch, wie schwer diese Rolle ist und wieviel man von dem Stoff auch wieder vergessen hat.
In meiner Freizeit verbrachte ich als Informatiker viel Zeit vor dem Rechner, klar. Von Darmstadt habe ich nicht viel mitbekommen, um in Cafes rumzusitzen zum Beispiel hätte mir auch schlicht das Geld gefehlt. Aber so ein bisschen Studentenleben nahm ich doch mit: Mit Jugger eine ungewöhnliche Sportart; Serien bekamen durch das Studentennetzwerk eine neue Bedeutung, Filme ebenso durch den Mathefilmabend (mit schlechten Filmen) und dem Studentenkino im Audimax (mit besseren); auf Vorschlag einer Kommilitonin lernte ich mit ihr Salsa, ich war und bin darin untalentiert, aber es war aus Gründen später eine der wichtigsten Sachen die ich hätte lernen können. Die D&D-Gruppe erwähnte ich oben über den Spielemeister, eine Brettspielgruppe fand sich auch, meine erste. Ein paar Klischees erlebte ich zudem: Den sich nie als nützlich erweisenden Sprachkurs, krude Charaktere in WGs, sogar eine für mich gescheiterte WG, ein paar wenige Studentenfeiern.
Man kann sich ja gerade bei Informatik auf den Standpunkt stellen, dass das Studium nicht lohnt. Einfach alles relevante online lernen, oder eine Ausbildung im Unternehmen machen und so früh wie möglich mit dem Arbeiten anfangen, beides bringe am Ende durch die gesparte Zeit mehr Gehalt. Stimmt monetär vielleicht. Aber wenn nicht gerade eine Pandemie alles sowieso blockiert, dann verpasst man so eben auch dieses Leben. Das zwar bei all der Arbeit, dem geringen Einkommen und dem dauernden Prüfungsstress auch nicht immer toll war, aber im Nachhinein echt keine schlechte Zeit.
Fazit
Man wurde im Informatikstudium mit Stoff bombardiert. Das schaffte viele Grundlagen, um Neues zu verstehen und auch anzuwenden. So brauchte ich beispielsweise diesen Schubs, um die praktische Funktion von Datenbanken zu verstehen und in meine Projekte einbauen zu können. Generell wurde alles was irgendwie praxisrelevant war besonders interessant: Beispielsweise auch der Bayes-Algorithmus wegen meinem Bayes-Spamblockplugin. Aber das funktionierte auch andersrum: Praktisch alles, für das ich einen Zugang finden konnte – was mir nicht komplett unergründlich war – hatte in den Folgejahren nochmal irgendwie eine Relevanz. Selbst manche der Mathematikkenntnisse, sogar die Logikformeln aus den formalen Grundlagen erleichterten später mindestens das Lesen mancher Veröffentlichungen.
Gut, manches war zu speziell oder ist mittlerweile veraltet. Das Wasserfallmodell als Entwicklungsmodell mit Lasten und Pflichtenheft zum Beispiel – klar gibt es das noch, aber es ist aus gutem Grund nicht der Standard. UML-Diagramme hätte man auch weniger machen können, damit Programme zu planen wurde sicher nicht die Zukunft der Programmierung. Wobei: No-Code-Programmierung baut ja irgendwo schon auf den gleichen Ideen auf, dafür gibt es derzeit verstärkt Aufmerksamkeit. Bei den Software-Designpatterns weiß ich nicht mehr, ob meine bis heute anhaltende kritische Haltung vom Dozent vermittelt wurde oder ob ich damals schon ihre Probleme wahrnahm. Aber das Thema zeigt die Gefahr, dass man an der Uni auch Dinge lernen kann, die einem Programmierer in der Praxis eher schaden – wie das übertriebene Anwenden von Designpatterns.
Doch insgesamt: Für jemanden, der später Software bauen wollte, war das Informatikstudium in Darmstadt eine gute Wahl. Dass ich mir ein eigenes Bachelorarbeitsthema aussuchen konnte, direkt einen tollen Betreuer fand und daran dann auch noch bei der Telekom arbeiten konnte war dann noch ein guter Endpunkt eines guten Studiums. Rückblickend muss ich auch loben, wie gut die Uni ausgestattet war (schon der PC-Pool im Keller mit sauber funktionierenden Linux-Computern), wie fähig die Professoren Vorlesungen hielten und wie gut das Studium organisiert war, abgesehen nur vom damals fast unschaffbar überfrachteten dritten Semester.
Müsste ich nochmal von vorne anfangen, würde ich direkt wieder dieses Studium wählen und auch wieder nach Darmstadt gehen. Stattdessen ging es mit einem Master weiter, über den es auch einiges zu erzählen gibt.
Impfzentrum, circa Juni 2021
Monday, 28. June 2021
Die in Deutschland aufgebauten Impfzentren sind Ausdruck unbedingten Impfwillens. Dort durchgeschleust zu werden fühlt sich an, als sei man ein Produkt auf einem Fließband. Gleichzeitig ist das schnell, effizient und relativ unbürokratisch – genau was gebraucht wurde.
Die Schlange wartet
Ankommen zum vergebenem Termin mit dem vorausgefüllten Aufklärungs- und Anamnesebogen in der einen Hand, dem Telefon mit dem QR-Code der Terminbestätigunge in der anderen. Es fehlt die dritte und vierte, um sich problemlos wie vorgeschrieben die Hände zu desinfizieren – bei dem folgenden Herumbalancieren sind sicher schon viele Telefonbildschirme zerstört worden. Die Frau vor uns, über 60, meint sie habe keinen QR-Code erhalten (er steht immer in der Terminbestätigung). Aber sie weiß auch nicht was das ist. Unser wird überhaupt nicht gescannt, der Ausweis ist aus gerade klargewordenem Grund wohl doch genug.
Weiter zur Anmeldung. Nett: Wir werden zusammengestellt, obwohl jeder seinen eigenen Termin hat, das macht alles einfacher. Vor dem Strich warten, dann setzen. Die Empfangsdame schaut auf die Dokumente, gibt meiner Begleiterin einen neuen Impfpass. Weiter zum Wartebereich.
Ob der QR-Code schon gescannt wurde? Nein. Aber eingecheckt seien wir. Also geht es trotzdem mit Papierwartenummer in der Hand – statt dem nicht mehr nötigen Telefon – in den Wartebereich. Der ist ziemlich voll.
In NRW wurden am Tag der Impfung die Impfzentren für alle freigegeben. Das war später als ich erwartet hatte, deutlich nach der offiziellen (wohl nur Möglichkeit der) Freigabe zu Beginn des Monats. Es hatte dazu geführt, dass ich uns doch bei Ärzten auf Wartelisten habe setzen lassen, auch wenn das so aussichtslos schien wie es dann auch ergebnislos war. Jetzt aber war das Impfzentrum für uns nicht nur offiziell freigegeben, sondern auch direkt greifbar, weil frühmorgens vor der offiziellen Freischaltung das Online-Buchungssystem schon funktionierte. Und dort gab es sogar Termine für den jetzigen Tag.
Entsprechend viele sitzen hier, wobei das Wort Zweitimpfung oft fällt und der Großteil älter ist als wir. Man muss dem Zentrum zugute halten, dass es überhaupt keine Probleme mit uns gibt – fällt doch der Impfberechtigungsnachweis weg und sind wir damit so ziemlich die ersten. Aber die Leute sind vorbereitet.
Das Nummern-Aufrufen ist etwas chaotisch. Die vorher noch Wartenden brauchen einen Moment um zu verstehen, wohin sie bei Aufruf der Nummer gehen sollen. Und dann fehlen manche Nummern einfach, sind die Impflinge verschwunden. Vielleicht waren es Begleiter, wobei wir zwei eine gemeinsame Nummer bekommen haben. Leichtem Chaos zum Trotz geht es schnell, nach wenigen Minuten sind wir in einer Kabine.
Ärmel hochkrempeln. Der Arzt schaut in die Mappe. Noch Fragen? Eigentlich nein, ein kurzes Detail wird noch von mir erwähnt, aber es passt nicht ins Schema, er zuckt die Schultern. Kleiner Pieks, Stempel ins Dokument, fertig!
Fertigstellung
Nicht ganz, es gibt noch den Wartebereich. Der scheint entgegen der offiziellen Beschreibung inzwischen optional geworden zu sein, wir werden freundlich gebeten doch bitte erstmal zu warten, weil die Schlange so lang sei. Angesichts der super-seltenen Nebenwirkungen ist das verständlich, aber gleichzeitig sind die für uns Grund genug sowieso auch warten zu wollen. Man weiß ja nie.
Beim Warten schätzt meine Begleitung den Durchsatz des Zentrums. 2 pro Minute sind es wohl, was auch genau mit unserer Wartenummer und Terminzeit zusammenpasst. Es ist bestimmt eines der kleineren Zentren.
Bei der Abmeldung wird nochmal auf die Dokumente geschaut. Dem Nachbar neben uns wird mit Händen, Füßen und etwas Englisch erklärt, dass er nochmal wiederkommen muss für die Zweitimpfung. Uns, dass ein weiterer QR-Code für den digitalen Impfausweis per Post ankommen wird. Auch wir sollen die Zweitimpfung nicht vergessen. Als ob wir die nicht schon begierig erwarten. Und jetzt hocherleichtert den Parkplatz erreichen.
Die Impfzentren müssen bleiben
Die Impfzentren sind eine gute Einrichtung und sie sollten unbedingt bis zum vollständigen Ende der Pandemie erhalten bleiben. Das ist keineswegs sicher, sie kosten ja Geld, die Finanzierung steht bis September. Anlass für Laschets NRW-Querdenker-CDU, pro-Corona zu wirken. Dass es Mutationen und weitere Impfungen geben wird wollen solche wohl ignorieren – so wie die CSU-Spinner jetzt schon wieder Lockdowns ausschließen. Immerhin fordert Söder mal wieder genau das richtige: Einen Erhalt der Impfzentren. Man kommt nicht umhin, dem Mann und seinen Positionen Respekt zu zollen.
Denn die Impfzentren viel besser geeignet als Hausärzte, fair und schnell viele Menschen zu impfen. Gerade solche wie uns, die weder Wurzeln noch einen Hausarzt in der Region haben wo sie wohnen. Die Praxen können die Impfrate erhöhen, indem sie ihre Stammkundschaft abdecken, aber sie haben nie im Leben die Kapazität und die Organisationsfähigkeit, so viele Menschen wie die Zentren effizient zu behandeln. Nichtmal, wenn alle Praxen mit einem gemeinsamen Buchungssystem arbeiten würden, wovon es sowieso keine Spur gibt. Unser Besuch und dass wir überhaupt einen Termin bekommen haben hat das nur zu deutlich gezeigt. Es braucht diese Fließbänder, keine verstaubten Warteräume mit Spielecke für die Kinder.
Trafficverbrauch eines Videos
Monday, 7. June 2021
Nach dem Artikel mit dem Gource-Video habe ich mich gefragt, welchen Effekt es für diesen Blog und seinen Bandbreitenhunger hat wenn ich hier Videos hoste.
Das Gource-Video war 77MB groß. Ich schrieb noch im Artikel, dass das für zweieinhalb Minuten zu viel ist. Aber Im Vergleich zu was sonst so im Internet oft auf Seiten sitzt ist das ja winzig. Es kleiner zu kriegen hatte mich zwar interessiert und meine Versuche dazu waren daher Teil des Artikelinhalts, aber das war technische Neugier, keine gefühlte Notwendigkeit. Sieht man so ein Video eines bisher kommentarlosen Artikels überhaupt in der Bandbreitennutzung dieses Blogs?
Tatsächlich tut man das sehr deutlich. Zwischen dem Server und dem Internet sitzt Cloudflare. Cloudflare misst den Trafficverbrauch und zeichnete mir diesen Graphen:

Das simple Video verzehnfachte den Verbrauch, von normalerweise etwa 400MB auf 4GB.
Kurioserweise sieht vultr, der Hoster des Blogs, ganz andere Werte. Auch bei dessen Messung ist eine deutliche Trafficspitze zu sehen:

Aber die Zahlen sind deutlich geringer.
Ich kann den Unterschied nicht erklären. Cloudflare wirkt zwar auch als Cache. Aber den Daten zufolge ist das Video nicht richtig von Cloudflares Cache aufgegriffen worden, die Cachenutzung war nur minimal erhöht:
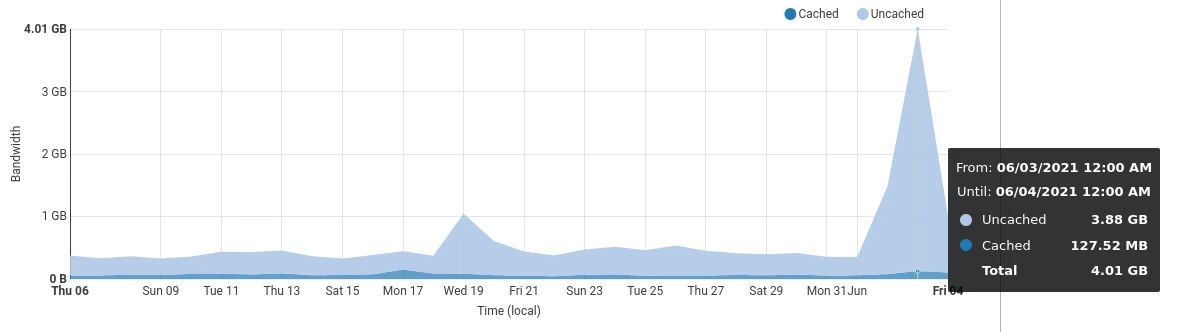
Wo sind die restlichen Gigabyte geblieben?
Trotz des Unterschieds zeigen die Graphen welchen enormen Effekt es haben kann, Videos im Blog hochzuladen. Bei meinem Inklusivtraffic ist da zwar noch viel Luft bis zur Grenze, ab der ich dann draufzahlen müsste. Aber sie scheint erreichbar. Wäre der Eintrag beliebter gewesen und mehr geteilt worden wäre auch das Video öfter heruntergeladen worden. Und dann will man das vielleicht nicht nur einmal machen, sondern veröffentlicht mehrmals im Monat ein neues Video. Bei Bloggern mit generell mehr Besuchern würde so der Trafficbedarf auch mit der regulären Besucherzahl ein Thema werden. Bei Videos im Blog lohnt sich also schnell ein Hostingpaket mit mehr freiem Trafficverbrauch.
Oder man packt es eben einfach auf YouTube oder PeerTube. Was ich bewusst nicht getan hatte: Bei beiden ist das ewige Fortbestehen des Videos nicht gerade sicher. Aber bei mehr Besuchern und mehr oder größeren Videos überwöge schnell der Nutzen dieses Bedenken.
Ein Printstylesheet für den Blog
Tuesday, 4. May 2021
Dieser Blog hat neues CSS für die Druckdarstellung bekommen. Der Artikel zur Witcherserie als Beispiel sieht im Web so aus:

Ausgedruckt – bzw mittels der Druckfunktion zum PDF umgewandelt – und dabei auf ein Blatt herunterskaliert kommt das dabei raus:

Erreicht wird die angepasste Darstellung durch dieses CSS, das ich einfach der regulären CSS-Datei hinzugefügt habe:
@media print {
#serendipitySideBarContainer {
display: none;
}
#content {
width: 100%;
}
#serendipityCommentFormC {
display: none;
}
.shariff {
display: none;
}
.dsgvo_gdpr_footer {
display: none;
}
#siteNav {
display: none;
}
body {
font-family: Iowan Old Style, Apple Garamond, Baskerville, Droid Serif, Times, Source Serif Pro, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol, Times New Roman, serif;
border: none;
}
html {
background-color: white;
}
.serendipity_entry_body {
column-width: 17em;
column-gap: 3em;
}
.serendipity_entry_body a[href*='//']::after, serendipity_commentBody a[href*='//']::after {
content: " (" attr(href) ")";
}
a {
color: black !important;
text-decoration: underline !important;
}
#serendipity_banner {
display: none;
}
#mainpane::before {
content: "onli-blogging";
display: block;
}
.serendipity_title a {
text-decoration: none !important;
}
.serendipity_title, .serendipity_date {
break-after: avoid;
break-after: avoid-page;
}
br + .serendipity_commentsTitle, .nocomments {
display: none;
}
.serendipity_entryFooter, .serendipity_comment footer {
display: none;
}
}
Wer das in seinen eigenen Serendipity-Blog übernehmen will müsste manche der Klassen wahrscheinlich anpassen, denn mein Design basiert mit codeschmiede auf älteren Code, den ich selbst nach HTML5 umgewandelt habe. Deswegen gibt es ein paar Unterschiede bei den Klassennamen zu 2k11 und anderen modernen Themes. Aber die Grundideen sind:
Ausgeblendete Seitenleiste und andere Elemente
Wer einen Artikel ausdrucken will kann auf dem Papier mit den Links in der Seitenleiste nichts anfangen, daher konnte die weg. Dazu habe ich den Header, der bei Einzelartikeln nur den Artikeltitel doppelte, den Footer des Blogs, die Artikelunterzeile und das Kommentarformular ausgeblendet.
Links ohne Farbe
Links sind hier im Blog normalerweise farblich markiert. In der Druckversion sind sie stattdessen schwarz, aber unterstrichen, und ihnen folgt das Linkziel als Text.
Serif-Schriftart
Für das richtige Papierdesign. Übernommen vom systemfontstack – es war gar nicht so einfach, passende Systemschriftarten für Serif- statt Sans-Serif-Schriftarten zu finden – aber leicht angepasst, denn Times New Roman war mir zu prominent platziert.
Spaltenansicht
Der Artikel wird wenn Platz ist in Spalten aufgeteilt. Auf dem Bild oben sind mehr Spalten als normal, da die Skalierung auf 60% reduziert war. Normalerweise sind es bei Din-A4 zwei Spalten im Querformat und nur eine, wie am Monitor, im Hochformat. Die Idee habe ich von sitepoint übernommen.
Titel hinzugefügt
Damit der Blogname trotz ausgeblendetem Header wenigstens irgendwo auftaucht wird er als Pseudoelement vor den Artikel gepackt.
Ganz bewusst nicht ausgeblendet sind die Kommentare, denn die könnten ja zum Artikel beitragen bzw das sein, was jemand ausdrucken wollte. Und auch das Videoelement ist absichtlich noch da, denn ohne es würde dieser Abschnitt des Artikel fehlerhaft wirken. Man kann es zwar nicht anklicken, aber sieht so zumindest dass es da war.
Insgesamt ging es also darum die Artikel auf dem Papier lesbarer zu machen, interaktive Elemente möglichst zu entfernen und auch die angezeigten Farben auf ein Minimum zu reduzieren. Damit wenn schon etwas ausgedruckt wird, es möglichst sparsam geschieht und das Ergebnis so lesbar wie möglich ist.
Dieser Blog lief zu lange ohne Backups
Wednesday, 10. March 2021
Heute ist OVH in Straßburg ein Rechenzentrum abgebrannt. Die Bilder sehen nicht so aus, als ob da Daten überleben könnten:
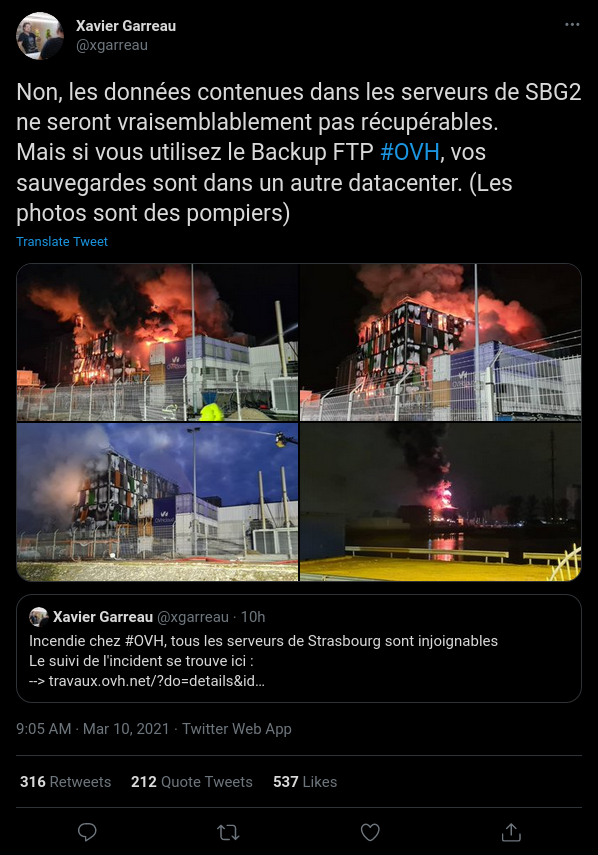
Und während auf Hackernews die Leser über ihre Notfallpläne diskutierten ging ich im Kopf auch die meinen durch. Lokales Backup via pogo, externes Backup via rsync. Selbst wenn da ein Datenzentrum abbrennt, kann nichts wirklich passieren. Oder? Um zu überprüfen, dass die Backups wirklich durchgeführt werden, ging ich meine Server durch. Auch den dieses Blogs. Und sah: Nichts.
Kein Backupskript. Kein Eintrag in der crontab. Keine aktuelle Backupdatei auf dem Backupserver. Selbst die Backupoption des Hosters (die 0.50€ kostet!) war aus.
Ich hatte bei meiner Blog-Migration von scaleway zu vultr Backups schlicht vergessen. Ich weiß noch, dass ich kurz dachte, das einen Moment später machen zu können weil ich wegen des Umzugs ein lokales Backup hatte. Ein Fehler. Es war eine stressige Zeit und ich habe da nie wieder dran gedacht. Bis heute.
Die Einträge eines Jahres wären verloren gewesen. Klar, mancher steckt vielleicht noch in Caches, aber garantiert nicht alle. Dieser Blog lebt seit 2008, es ist meine wichtigste Webpräsenz, auch nur Teile davon zu verlieren wäre furchtbar ärgerlich gewesen. Ich habe Unmengen Glück gehabt, dass die Daten auf dem Server ohne Backup überlebten. Backups, die jetzt wieder aktiviert sind.
Rennt da nicht rein: Überprüft eure Backups, macht welche wenn ihr noch keine habt.
Wie geht ihr mit alten Beiträgen um?
Friday, 8. March 2019
Ein letzter Blick auf die Pingdom-Statistik dieses Blogs
Tuesday, 29. January 2019
Pingdom schaltet seinen kostenlosen Monitoring-Service ab. Da der Blog hier ein Hobby und der Service nicht zwingen notwendig ist, werde ich nicht zu einen bezahlten Abo wechseln. Wahrscheinlich werde ich daher den Zugang zu den gesammelten Daten verlieren. Pingdom lud regelmäßig diese Seite, schaute ob sie antwortete und wie schnell sie das tat. Wenn der Blog offline war bekam ich eine Email. Seit dem 15.06.2014 bin ich dort angemeldet (wow, ne ganze Weile! Nutzer wie ich lohnten sich für die definitiv nicht). Schauen wir uns das Diagramm der Ladezeiten und Ausfällen gemeinsam an:
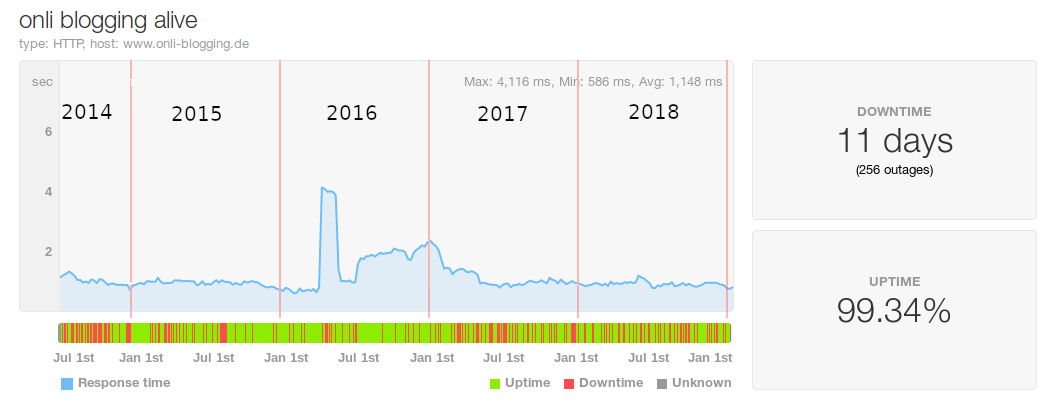
Auffällig sind für mich vier Dinge:
- Die schlechten Antwortzeiten Mitte 2016.
- Die dann besser wurden, aber erst Mitte 2017 akzeptabel.
- Mitte 2018 verbesserte sich die Situation noch ein bisschen.
- Es gibt relativ viele rot markierte Ausfälle.
Ich wollte dafür jetzt jeweils eine Erklärung liefern, stelle nun aber fest, dass ich mich kaum erinnere was da jeweils passiert ist. Teilweise habe ich hier im Blog darüber geschrieben, manches steckt in meinen Emails. So viel konnte ich rekonstruieren:
Der erste große Anstieg 2016
Der kommentarlose Artikel zu Pixel Piracy wird keinen Besucheransturm ausgelöst haben, der den Server lahmlegte. Nein, die Ursache war wahrscheinlich ein Serverwechsel.
Wenn ich mich richtig erinnere lag dieser Blog lange auf dem Server eines Kumpels, gehostet bei Hosteurope. 2016 schaltete der den Server ab und verabschiedete sich aus dem Internet. Das betraf mindestens eine meiner Webseiten, wahrscheinlich eben den Blog und pc-kombo. 2015 hatte ich Scaleway entdeckt. Und genau dorthin bin ich mit dem Blog damals gewechselt.
Der kleine Scaleway-ARM-Server war für Serendipity etwas zu schwach. Die Besucher des ersten Artikel reichten dann aus um ihn zu überlasten. Dazu kommt, dass ich nach den Cache-Tests im Jahr zuvor das simplecache-Plugin vermeiden wollte, um mich zu zwingen Arbeit in einen in s9y intergrierten Cache zu stecken. Dieser Cache kam dann kurz darauf mit der 2.1-beta2. In den ersten Tagen lief daher eventuell nichtmal das Simplecache-Plugin, die Antwortzeiten waren entsprechend schlecht.
Die Verbesserung Anfang-Mitte 2017
Im April wurde Serendipity 2.1 veröffentlicht, mit dem oben erwähnten integrierten Cache und Support für PHP 7.0. Beides großartig gerade für schwache Server, und Anfang 2017 lief dieser Blog noch auf dem schwachen Scaleway-Server. Das blieb nur noch kurz so und auch das beeinflusste sicher die Statistik: Im Mai 2017 fing Scaleway an, einen stärkeren ARM-Server zum gleichen Preis anzubieten. Dorthin zu wechseln, zusammen mit PHP 7 und dem aktivierten Cache, sorgte dann für stabile ordentliche Ladezeiten.
Eine kleine Verbesserung 2018
Es ist in Teilen eine optische Täuschung: Die Werte nach dem kleinen Anstieg im Juli sind gar nicht so viel besser. Die tatsächliche kleine Verbesserung erklärt sich vielleicht über die Artikelfrequenz, die im Sommer relativ hoch war und dann wieder niedriger wurde. Werden hier öfter und regelmäßig Artikel veröffentlicht, müssten über Feedreader und Google auch mehr Besucher hier sein, was die Serverlast ein bisschen erhöht. Nachher wurde es weniger, die durchschnittliche Serverantwortzeit konnte sinken.
Außerdem gab es 2018 mehrere kleine Serendipity- und Pluginupdates, die vielleicht auch der Performance gutgetan haben.
Ausfälle
Die Farbe auf der Skala unten muss täuschen, denn eine Uptime von 99,34% passt mit dem vielen rot nicht zusammen. Aber es lässt sich doch vermuten, dass 2014 hier irgendwas schief ging, der Server war nicht stabil. 2015 und vor allem 2016 war besser, die Ausfälle selten. Mit dem Wechsel auf den stärkeren Scaleway-Server scheinen die Ausfallzeiten aber zugenommen zu haben. Ich bin sogar schon selbst in die Situation gerannt, dass sich ein Server auf Scaleway nicht erreichen und zeitweise auch nicht neustarten ließ. Das sollte ich weiter beobachten.
Nur wird das wohl nicht mit Pingdom geschehen, wovon ich mich hiermit verabschiede.
Wie ich arbeite
Wednesday, 2. January 2019
Ich kopiere von Dirk und schreibe auf, womit ich 2018 gearbeitet habe. Tatsächlich hat sich ein bisschen was getan, nur Bruchstücke davon sind hier dokumentiert. Schreibe ich ein paar Jahre lang am Jahresende einen solchen Artikel könnte der Rückblick später nett sein.
Hardware
Auf der Arbeit benutze ich einen mir gestellten Laptop, der an einen 1440p‑Breitbildmonitor angeschlossen wird. Ich hatte da keinen Einfluss drauf, bin aber mit beiden Geräten sehr zufrieden. Nur eine ergonomische Maus (eine M618) hatte ich mir speziell gewünscht und erhalten.
Daheim ist mein Hauptwerkzeug mein Desktoprechner. Derzeit ist das ein AMD FX‑8320E, den ich günstig gebraucht gekauft habe, mit einer ebenfalls günstig gebraucht gekauften Radeon RX 580. Ryzen und das Platzen der Cryptoblase sorgten gegen Ende des Jahres für richtig nette Preise bei diesen Komponenten. Die FX‑Reihe ist nicht toll gewesen, der 8320E reicht als Prozessor für meine Zwecke aber völlig aus – und im Gegensatz zum Phenom II X6 kann er Deus Ex: Mankind Divided starten... Es blieb beim GA‑990FXA‑UD3 als Mainboard, mit mittlerweile 20GB Arbeitsspeicher, zur 120GB SSD kam eine 500GB SSD hinzu, dafür wanderte die 500GB HDD in einen anderen Rechner.
Der Monitor ist ein Dell U2312HM, 23.6", 1080p, IPS‑Panel. Er ist an sich sehr gut, hat aber inzwischen ein paar Macken in der Beschichtung und piepst bei runtergeregelter Helligkeit. 2019 könnte er ersetzt werden.

Die Grafikkarte ist noch ziemlich neu hier, ich habe seitdem Stabilitätsprobleme (zum Glück nur beim Spielen), die mit der Temperatur zusammenhängen zu scheinen. Ich vermute das Problem inzwischen allerdings beim Mainboard und werde versuchen, es mit mehr und etwas schneller laufenden Gehäuselüftern zu lösen.
Peripheriegeräte sind eine mechanische Cherry‑Tastatur (G80-3000), eine generische ergonomische Maus von CSL und der Logitech UE 6000, der sich als komfortabler als der Superlux HD 681B entpuppt hat, den ich auch sehr mochte und viele Jahre trug.
Das Wileyfox Spark+ ist weiterhin mein Smartphone, ich benutze es aber für die Arbeit nur um in Notfällen erreichbar zu sein, ansonsten unterwegs privat (Pokemon Go, Firefox, Google Maps). Leider wird es nicht mehr ordentlich mit Updates versorgt, es hat Android 7.0, der Stand der Sicherheitsupdates ist Januar 2018. Das ändere ich bald, Lineage wird installiert werden. Aber das Telefon soll auch dann nur noch als Backup dienen, der Ersatz steht schon bereit.
Am Ende des Jahres war ich lange im Urlaub. So lange, dass ich einen Weg haben wollte, Emails abzurufen und im Notfall die Server neustarten zu können. Das HP Touchpad wurde dafür auserkoren, mit Termux und K9‑Mail war alles notwendige auch unter Android verfügbar. Auch zum Browsen auf dem Sofa war das super. Alternativ hätte ich das Thinkpad R50 mitgenommen, aber es war mir für diesen Zweck zu schwer. Trotz langer Suche habe ich kein vernünftiges (=auswechselbare Batterie, 14" oder weniger, ordentlicher Bildschirm, linuxkompatibel), kleines, leichtes und bezahlbares Laptop gefunden.
Zwischendurch und wegen der Arbeit hatte ich eine Smartwatch getragen. Ich stellte dann aber fest, dass mich das tägliche Aufladen nervt und ich echte Uhren schöner finde. Seitdem trage ich wieder eine meiner Chinauhren.
Software
Im Büro
Der Arbeitslaptop lief dieses Jahr mit Windows. Ich wollte bewusst im neuen Job erstmal mit der vorgegeben IT‑Infrastruktur arbeiten und hatte anfangs versucht mit VMs zurechtzukommen, sobald Linux doch gebraucht wurde. Da nur wenig programmiert wurde und dann auch noch in Android Studio ging das bis jetzt ganz gut. Ansonsten war da wenige spezielle Software dabei, viel Office, am Ende etwas Axure – für Mockups und Prototyping scheint es erstaunlicherweise wenig geeignete Linuxsoftware zu geben!
Den Laptop nach Linux umzuziehen steht aber gerade ganz oben auf meiner Agenda, das neue Jahr soll etwas anders laufen. Und die VMs waren mir für den Desktopbetrieb weiterhin zu langsam, gerade beim Scrollen im Firefox.
Linux
Daheim ist am allerwichtigsten der Editor, wie die Jahre zuvor war das Geany mit dem Farbschema Solaris (dark). Pipes, pc‑kombo und all meine FOSS‑Arbeit entstand in Geany. Mehr brauche ich fast nicht: Trojita ist der Email‑Client, Firefox der Browser, urxvt das Terminal, der Linuxdesktop ansonsten weiterhin zusammengestückelt (IceWM, conky, simdock, trayer) und damit die einzige Besonderheit.
Die Linuxdistribution habe ich von Funtoo zu Void gewechselt. Wie immer ist so ein Umzug nicht ganz ohne, immer noch läuft nicht alles so gut wie vorher. Aber ich bin trotzdem sehr zufrieden: Void bietet aktuelle Pakete und erspart mir das dauernde Kompilieren der Updates, was mich nach einer Weile einfach zu sehr genervt hat.
Android
Unter Android läuft nicht viel erwähnenswertes, Firefox Beta ist die Hauptapp. F‑Droid ist installiert, genutzte Messenger sind derzeit Hangout und Telegram, aber auch SMS (wenn auch mit Silence) waren 2018 noch wichtig. Ich habe den DB‑Navigator entdeckt und kann nun Tickets und BahnCard damit vorzeigen, ein Quantensprung.
Web
Duckduckgo ist die Suchmaschine an den PCs, wobei ich noch oft !g eintippen muss um die Suche nach Google zu lenken, leider sind gerade die nicht‑technischen oder deutschen Suchergebnisse noch zu schlecht. Deshalb teste ich auf dem Telefon derzeit Qwant, was mir dort sehr gut gefällt.
Als Feedreader habe ich einen kostenlosen Account bei feedly.
Hoster sind auch wichtig, derzeit sind das Hetzner (pipes), scaleway (pc‑kombo, dieser Blog) und uberspace (Entwicklungsinstallationen und Emails).

