Artikel mit Tag spamblock_bayes
Spamblock-Bayes 1.0 als reduzierte modernisierte Version
Monday, 17. August 2020
Das Bayes-Plugin hat ein Update auf die Version 1.0 bekommen. Die neue Variante des Anti-Spamplugins für Serendipity hat weniger unnötige Funktionen, benutzt die neueste Version des b8-Filters und sollte alles in allem stabiler funktionieren.

Die erste Version des Plugins entstand 2009. Es ist dann eine ganze Weile gewachsen, bekam z.B. ein Backendinterface. Zwischendurch hatte ich sogar Pläne, die Spamdatenbank zwischen Blogs hin- und herzuschicken, sodass eine dezentrale geteilte Datenbank entsteht, aber damals fehlten mir dazu die Mittel das richtig umzusetzen und am Laufen zu halten.
Bayes wird immer noch benutzt, hier im Blog zum Beispiel, aber mittlerweile hat sich seine Rolle herauskristallisiert. Es ist meistens die letzte Verteidigungslinie. Die anderen Spamblockmaßnahmen sind oft genug, um den Großteil der Spamkommentare aus dem Blog herauszuhalten.
Jetzt hatte das Plugin schon länger keine größeren Updates gesehen und ein paar Sachen störten:
- Wir hatten damals den Bayesfiltercode in das Plugin integriert. b8 ist aber mittlerweile in der Lage, sich in andere Datenbanken einzuhaken und hat seine Berechnungen verbessert. Es wäre besser, es als externe Abhängigkeit zu nutzen und so von diesen Weiterentwicklungen zu profitieren.
- Das Admininterface war im Grunde unnötig, außer um mal den Papierkorb zu überprüfen musste man da als Blogbesitzer fast nie reinschauen.
- Es war zu viel Code. Die vorherige Version hatte über 2000 Zeilen PHP-Code in der serendipity_event_spamblock_bayes.php, dazu kam dann noch Smarty-Code, CSS, HTML und Javascript für das Backend
- Das enthaltene SQL und somit das Plugin funktionierte nicht mit PostgreSQL als Datenbank.
Die Version 1.0 ist daher eine große Aufräumaktion. Relativ wenig alter Code wurde übernommen, im Grunde nur der für den Papierkorb nötige und ein paar Helferfunktionen. Ich habe unseren Filtercode herausgeschmissen und stattdessen die neueste Version von b8 integriert. Damit das auch mit SQLite funktioniert brauchte das Projekt ein neues Datenbankbackend, das habe ich geschrieben und upstream zukommen lassen. PostgreSQL könnte man genau so nachrüsten, wenn sich ein Tester findet. Das Javascript für die Kommentarliste ist neu und nutzt jQuery, es sind nun ganz wenige Zeilen. Das Menü im Backend ist auch reduziert, dort findet sich nur noch der Papierkorb. Gleichzeitig funktioniert dessen Styling nun ordentlich im neuen Backenddesign.
Insgesamt dürfte das Plugin verlässlicher funktionieren. Auf jeden Fall ist der Code besser wartbar und es gibt weniger Fallstricke wie überflüssige und somit verwirrende Menüs.
Das Update ist schon in Spartacus. Die alte Spamdatenbank wird beim Update nicht übernommen.
Spamblock-Bayes: Theoretische Grundlagen
Friday, 22. June 2012
Bayes-Formel
Das Bayes-Theorem wurde entdeckt, verworfen und schließlich wiederentdeckt. Ich glaube, die mathematischen Einwände gegen die Formel finden sich manchmal noch in der Kritik an solchen Filtern wieder, deshalb sei ihr Vorhandensein erwähnt.Die allgemeine Formel lautet:

P(A) ist die Wahrscheinlichkeit für A, P(A|B) ist die Wahrscheinlichkeit für A unter der Bedingung B, also wenn B eingetreten ist.
Wie sieht das nun für Spam aus? So:
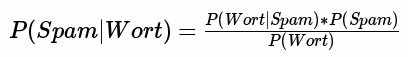
Zu beachten ist, dass wir diese Spamwahrscheinlichkeit für jedes Wort im Kommentar wissen wollen, daher am Ende mehrere Wahrscheinlichkeiten aufaddieren und normalisieren müssen.
Aufdröselung
Es gibt also genau drei Variabeln zu berechnen: Die Inverse Wahrscheinlichkeit, die Wahrscheinlichkeit von Spam und die Wahrscheinlichkeit für das Auftreten solcher Wörter. Das für jedes Wort. Was genau bedeuten die Formeln jeweils?- P(Wort|Spam)
- Dies ist die Wahrscheinlichkeit, dass in einem Spamkommentar dieses Wort vorkommt: Spamkommentare mit diesem Wort / Spamkommentare
- P(Spam)
- Die Gesamtwahrscheinlichkeit, dass ein Kommentar Spam ist: Spamkommentare / Kommentare.
- P(Wort)
- Die Wahrscheinlichkeit, dass dieses Wort überhaupt in einem Kommentar vorkommt: Kommentare mit diesem Wort / Kommentare
Programmiertechnische Konsequenzen
Es ist völlig klar, dass eine Datenbank gebraucht wird und die Bewertung größtenteils aus dem Heraussuchen der richtigen Daten zu den Worten besteht. Zuerst muss ein sogenannter Tokenizer den Kommentar in seine Einzelwörter zerlegen. Im Wesentlichen ist das ein:tokenize(text) {
tokens = split("\W", text )
return unique(tokens)
}
Das Lernen eines Kommentars als Ham oder Spam ist nun nichts anderes, als diese Tokens in diese Datenbank namens "tokens" zu schreiben:
token (text) | ham (number) | spam (number)Ist das Token schon vorhanden, wird der zugehörige Ham- bzw Spamwert um eins erhöht. Gleichzeitig wird der Gesamtzähler Hamkommentare bzw Spamkommentare um eins erhöht.
Diese Datenbank zusammen mit den Gesamtzählern gibt uns nun alle nötigen Werte:
- P(Wort|Spam)
spam = sql_query("Select spam from tokens where token = Wort") spam / (Spamkommentare)- P(Spam)
Spamkommentare / (Spamkommentare + Hamkommentare)
- P(Wort)
ham, spam = sql_query("Select ham, spam from tokens where token = Wort)" (ham + spam) / (Spamkommentare + Hamkommentare)
Formelveränderungen
Schaut man sich nun die Bewertungsfunktion im Bayes-Plugin an wird man feststellen, dass der PHP-Code nicht nur wesentlich unschöner als mein Pseudocode aussieht, sondern auch anders funktioniert. Das liegt daran, dass das Plugin auf b8 aufbaute, und b8 nicht simpel das Bayes-Theorem benutzt, die Wahrscheinlichkeiten addiert und dann durch ihre Anzahl teilt. Diese Änderungen basieren auf Tests und anderen theoretischen Annahmen als den hier gezeigten. Insbesondere die folgenden Änderungen sind enthalten oder denkbar:Law of total probability
Wer Vorkenntnisse hat oder nachrecherchierte, dem könnte aufgefallen sein, dass Wikipedias Bayes-Spamfilterformel anders aussieht:
P(Wort) wird hier gemäß dem Law of total probability umgeformt. Ohne das gerade nachgerechnet zu haben vermute ich, dass die Werte gleich sein sollten und diese Formel nur P(Wort) anders betrachtet.
Häufigkeit von Tokens im Kommentar
Wie oft ein Wort im Kommentar auftaucht sollte die Wahrscheinlichkeit beeinflussen. Dieser Artikel hier ist kein Spam, obwohl nun Viagra auftaucht, aber wäre jedes Wort Viagra, wäre er durchaus Spam. Deshalb beachtet b8 die Häufigkeit eines Tokens.Wichtigkeit
Eine beliebte Spammertaktik ist, Kommentare mit ewig langem Fülltext auszustaffieren und den Spammerinhalt so zu verstecken. Der Gedanke dabei ist, dass die vielen harmlosen Worte den ganzen Kommentar harmlos erscheinen lassen. Die auch von b8 genutzte Taktik dagegen ist die Einführung eines Wichtigkeitsfaktors: Beziehe nur die Tokens in die Schlussrechnung ein, die eine Tendenz zu Spam oder Ham haben, also um einen bestimmten Faktor von der Mitte 0,5 abweichen. Der Gedanke dahinter ist, dass die vielen Füllwörter die Bewertung sonst gegen 0,5 tendieren lassen würden.Optimierungsmöglichkeiten
Ich schrieb oben, dass dieser Artikel die theoretischen Grundlagen zwecks einer späteren Optimierung des Filters deutlich machen soll.Diese Optimierungsmöglichkeiten sehe ich bis jetzt:
Ham-Spam-Faktor
Der Anstoßgeber dieses Eintrags ist diese Diskussion. Grischa schlug vor, über irgendeinen Faktor auszugleichen, dass ein typischer Blog sehr viel mehr Spam als Ham bekommt und daher der Filter zu streng werden würde. Meiner Meinung nach ist das nicht wirklich ein Problem, da diese Verteilung elementar für den Filter ist, und nicht automatisch neuer Spam eingelernt wird, wenn man das nicht will.Wikipedia erwähnt, dass P(Spam) generell 0,8 sei. Vielleicht würde es helfen, diesen Wert festzusetzen statt ihn empirisch zu bestimmen?
Häufigkeit von Tokens
Wie oben beschrieben ist die Häufigkeit von Wörtern innerhalb eines Kommentars ein wichtiger Faktor. Zur Zeit fließt das aber nur indirekt in die Bewertung ein, indem es bei der Bewertung selbst ignoriert wird, beim Einlernen aber beachtet wird. Statt in der Tabelle den Ham- bzw Spamwert um eins zu erhöhen, wird er um die Anzahl der Tokens erhöht. Bei der Bewertung aber wird jedes Token nur einmal beachtet, selbst wenn es mehrmals vorkommt. Das könnte man ändern.Es ist auch ein kritischer Punkt, weil man sich hier leicht mit Anzahl der Tokens und Anzahl der Kommentare verheddern kann. Die Formel müsste genau geprüft werden.
Konstanten
Bei der Übernahme von b8 wurde die Klassifizierungsberechnung blind übernommen. In ihr enthalten sind einige Konstanten, die auf den Testergebnissen beruhen. Es geht um diese Zeile:$ratings[$word] = (0.15 + (($stored_tokens[$word]['ham'] + $stored_tokens[$word]['spam']) * $rating)) / (0.3 + $stored_tokens[$word]['ham'] + $stored_tokens[$word]['spam']);0,15 und 0,3 sind die Konstanten, die hier direkt die Bewertung beeinflussen und entfernt bzw verändert werden könnten.
Schlusswort
Es ist nunmal Mathematik. Ich hoffe, die Erklärung macht die Funktionsweise des Filters trotzdem klarer. Die Optimierung des Filters könnte ein sehr interessantes Projekt sein, aber auch sehr zeitaufwändig. Hinweise zu Fehler in den Formeln nehme ich dankend entgegenBayes 0.4.6: Backend-Verbesserungen
Sunday, 5. February 2012
Nachdem im Forum Verbesserungen für das Bayes-Plugin vorgeschlagen wurden, habe ich mich wirklich mal an das Backend gesetzt. Erstens ist es jetzt komplett smartifiziert. Zweitens wurde der Papierkorb überarbeitet. Und Drittens wurden einige kleine Verbesserungen eingebaut. Als Überblick:
-
Die Tabelle im Datenbankmenü war vorher blind auf 2000 Einträge beschränkt, damit das Einfärben der Zeilen nicht den Browser lahmlegte. Nun ist sie paginiert.

-
Die meisten sichtbaren Änderungen gibt es beim Papierkorb. Die wichtigste: Er ist nun durchblätterbar. Auch bei ihm bestand das Problem, dass er schlicht zu voll werden konnte und dann den Browser lahmlegte. Außerdem werden jetzt nur die sichtbaren Kommentare gelöscht und nicht blind alle. Statt der alten Tabelle wird jeder Kommentar nun in Listenform präsentiert und die Liste über detail/summary ausklappbar gemacht (mit polyfill für alle Browser außer Chrome, nur er kennt bereits das Element). Dadurch war auch genug Platz, Roberts Wunsch umzusetzen und den zugehörigen Artikel zu verlinken, und Grischas Wunsch zufolge wird die Kommentarbewertung angezeigt.

- Die Email-Benachrichtigung sollte zwischen den beiden Links den Text "Kommentar bewilligen und als valid markieren" anzeigen. Der wurde vorher verschluckt.
- Das Menü wird nur noch angezeigt, wenn der Nutzer die Rechte "adminComments" hat. Vorher war auch ohne dieses Recht das Menü sichtbar, aber die Aktionen wurden blockiert.
Nebeneffekt der Aktion ist, dass die serendipity_event_spamblock_bayes.php nun 200 teils sehr hässliche Zeilen weniger hat und damit wieder unter die 2000-Zeilen-Marke gerutscht ist. Der ganze HTML-Code gehört da auch wirklich nicht hin. Und durch die Templatisierung ist jede folgende Änderung einfacher.
Es wurde also doch nicht der komplette Umbau des Backends, den ich eine Weile in Betracht gezogen hatte, aber ich hoffe, durch die Änderungen ist nun alles etwas runder.
Bayes-Menü
Friday, 3. February 2012
Spamblock-Bayes 0.4.4: Troja
Sunday, 8. January 2012
Troja
Thursday, 15. September 2011
Troja wird gerade fertig. Es ist fertig geschrieben, Dirk hat es auf einem Server laufen, der erste Test schien erfolgreich. Dabei ist das die zweite Version, die erste war ein node.js-Server, der aber nur auf meinem System zu laufen schien (jetzt ist es ein socat-Bash-Skript).
Es fehlt noch der letzte Schliff, bessere Rückmeldungen nach den Aktionen, vielleicht mehr Adminaktionen, aber das Grundsystem steht.
Es gibt drei Aktionen, die vom neuen Import-Menü des Spamblock-Bayes-Plugins gestartet werden können:
Importieren
Aufgabe Trojas ist es ja, Spamdatenbanken per Klick importieren zu können. Das soll möglichst dezentral funktionieren, Troja ist nur der Vermittler. Mit der Funktion soll verhindert werden, dass Nutzer des Spamblock-Bayes-Plugins erstmal mit leerer Datenbank dastehen und lange brauchen, bis der Filter ordentlich funktioniert.
Nach einem Klick auf den "Importieren per Troja"-Button fragt das Plugin bei Troja nach. Troja schaut in seiner Datenbank nach einem eingetragenen Blog, wählt zufällig einen aus. Von diesem holt es einen RSA-verschlüsselten Key, entschlüsselt ihn, und sendet dann den Key und die Ziel-URL zum anfragenden Blog. Dieser kann nun mit dem Key bei dem anderen Blog die Spamdatenbank holen und sie einlernen.
Registrieren
Damit Troja nicht nur aus Dirks und meinem Blog besteht, kann sich jeder s9y-Blog dort eintragen. Das Plugin sendet nach einem Klick auf den Button die eigene URL an Troja, dann fragt Troja bei dieser URL nach, ob der Blog wirklich eingetragen werden soll.
Wichtig: Man muss sich nicht Registrieren, um Importieren zu können!
Austragen
Soll der Blog nicht mehr zum Ziel von Importanfragen werden, kann man sich natürlich einfach wieder austragen. Das Protokoll ist das gleiche.
Ich werde es hochladen, sobald ich von Dirk ein "Ja, funktioniert" höre :)
Troja angefangen, Spamdatenbanken tauschen
Thursday, 21. April 2011
Bayes 0.4.2
Wednesday, 23. February 2011
Bayes: Zählen von Kommentaren beim Import
Friday, 17. December 2010
Bayes 0.3.9: Import/Export
Thursday, 25. November 2010
YellowLed hat explizit danach gefragt und auch Dirk hatte so etwas in groß mal vorgeschlagen, daher liefert das neue Update für das Spamblock-Bayes-Plugin eine Import- und eine Exportfunktion nach. Mit diesen kann der gesamte Inhalt der Datenbank in eine CSV-Datei gespeichert und wieder in einen Blog geladen werden.


So etwas könnte man auch direkt über einen Datenbank-Dump machen, aber der Weg über die CSV-Datei vereinfacht das natürlich. Außerdem funktioniert das etwas anders: Die CSV-Datei wird mit dem bestehenden Datenbankinhalt kombiniert.
In der Datenbank stehen die Einträge in folgender Form:
|token| |ham| |spam| |type| casino 2 100 body
Das Beispielwort casino kam - im Textteil - 2x in validen Kommentaren und 100x in Spamkommentaren vor. Beinhaltet nun eine andere Datenbank und damit die von dort importierte CSV-Datei diese Zeile
casino 100 100 body
Dann wird das zusammengemischt, also
casino 102 200 body
Klingt und ist einfach, ist aber auch wichtig zu wissen, dass über die Importfunktion die Datenbank eben nicht einfach überschrieben wird.
Download: serendipity_event_spamblock_bayes-0.3.9.tar.gz oder über Spartacus.
Bayes 0.3.8: Bessere Analyse
Saturday, 26. June 2010
Bayes 0.3.7: Bewertungsanpassung und Erweiterung
Tuesday, 15. June 2010
Die neue Version des Spamschutz-Plugins ist nun per Spartacus installierbar.
Die Änderungen
Zwar von der Bezeichnung wieder nur ein Sprung um eine 0.1, aber diesmal sind die Änderungen etwas umfassender als beim letzten Mal.
Bewertungsfunktion
Das Plugin bewertet jedes einzelne Feld eines Kommentars, also z.B. den Namen und den Text eines Kommentars unabhängig voneinander. Dann werden die Werte aufaddiert und durch die Anzahl der Felder geteilt. Normalerweise zumindest. In der alten Version war es so: Wenn ein Feld über 90% war, der Kommentar also deutlich Spam, wurde direkt der größte Wert als Gesamtbewertung genommen.
Diese Umgehungsfunktion sollte gegen Spam helfen, bei dem beispielsweise alles außer der URL valide ist, nur diese auf eine Spamseite zeigt.
Leider führte das dazu, dass ab und an Kommentare fälschlicherweise als Spam erkannt wurden. Grundsätzlich ist das natürlich immer möglich, die Qualität des Filters hängt von der Datengrundlage ab. Stimmte die aber bei einem einzelnen Feld nicht, führte dies zur Spambewertung des ganzen Kommentars.
Deshalb geht die nun so: Es wird die Anzahl der Felder über 90% und die derer unter 10% verglichen. Nur wenn es mehr Spamfelder gibt als eindeutig valide, also mehr mit 90%, wird deren Wert genommen - ansonsten wird ganz normal der Durchschnitt errechnet.
Standardwert
Für die Bewertung werden nur wichtige Wörter genommen, also solche, die größer als 0,2 von der Mitte 0,5 abweichen. Ist kein solches Wort in einem Kommentar, wurde aber 0 als Bewertung genommen, dies hätte beim oben beschrieben Zusammenrechnen also als eindeutig valides Feld gezählt. Das wurde nun geändert auf die 0,5 - es sollten also eher mal Werte im Mittelbereich auftreten.
Analyse
Für die Überprüfung der Bewertungsfunktion schaue ich immer mal wieder nach, wie die Bewertung der einzelnen Felder aussieht. Das könnte aber auch für einen Nutzer interessant sein, um die korrekte Funktionsweise des Filters zu prüfen. Daher findet sich nun im Menü der Punkt "Analyse".
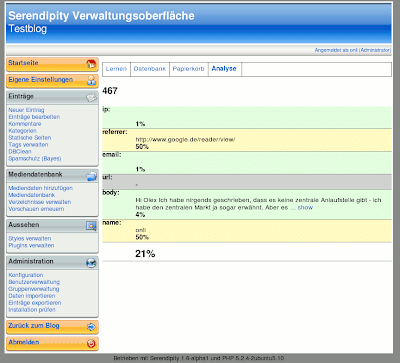
Sonstige Erweiterungen und Korrekturen
- Aus dem Papierkorb wiederhergestellte Kommentare werden direkt als "valid" eingelernt, zusätzlich gibt es einen Schalter, um beim Leeren des Papierkorbes alles als "Spam" zu lernen.
- Im Papierkorb ging beim letzten Update die von mir gewünschte Reihenfolge der Felder verloren, diese ist nun wieder wie gewollt.
Bitte bei Problemen wie immer melden.
Bayes 0.3.6: Zeit und Buttons
Monday, 24. May 2010
Das Bayes-Spamschutzplugin wird mit der neuen Version behutsam erweitert.
Es wird im Papierkorb nun auch der Speicherzeitpunkt des Kommentars angezeigt.
Außerdem ist auf der Kommentarseite ein "Markiere markierte Kommentare als Ham"-Button vorhanden, wobei fieldsets dafür sorgen sollen, dass die Pluginbuttons besser von den immer vorhandenen unterschieden werden können.

Das Update sollte inzwischen per Spartacus verfügbar sein.

