Artikel mit Tag ruby
Linksammlung 23/2022
Friday, 10. June 2022
Victor: SVGs mit Ruby erstellen
Friday, 15. May 2020
Vom Code aus Bilder erstellen – da landet man dann schnell bei SVG. Um unter Ruby ein SVG zu erstellen kann victor benutzt werden. Das Readme zeigt direkt wie es geht. Dieser Code:
require 'victor'
svg = Victor::SVG.new width: 140, height: 100, style: { background: '#ddd' }
svg.build do
rect x: 10, y: 10, width: 120, height: 80, rx: 10, fill: '#666'
circle cx: 50, cy: 50, r: 30, fill: 'yellow'
circle cx: 58, cy: 32, r: 4, fill: 'black'
polygon points: %w[45,50 80,30 80,70], fill: '#666'
3.times do |i|
x = 80 + i*18
circle cx: x, cy: 50, r: 4, fill: 'yellow'
end
end
svg.save 'pacman'
erstellt diese Grafik:

Cool: Der Code hinter dem gem ist ziemlich minimal, das ist fast nur eine intelligent gestrickte kleine API, die genau richtig den Funken Komplexität versteckt, wegen dem man SVGs anonsten nicht per Hand schreiben will. Samt hilfreichen Beispielen wird es ein praktisches Werkzeug.
Ich finde es toll, wie SVG immer wieder in Projekte von mir reinrutscht. Nicht, weil es bei mir besonders beliebt wäre, sondern schlicht weil es immer wieder gut ein Problem löst.
Pipes ist nun frei
Friday, 17. April 2020
Ich habe mich entschieden, Pipes unter eine freie Lizenz zu stellen. Die Pipes CE ist nun auf Github, steht unter der AGPL und ist einfach installierbar.
Pipes ist ein Projekt von mir, eine Webanwendung, die Yahoo! Pipes nachempfunden ist. Es ist ein grafischer Editor, in den man Daten – gerne RSS-Feeds – hereinzieht und dann bearbeitet, indem Blöcke verbunden werden. Einfachstes Beispiel wäre das Filtern eines Blogs oder eine Nachrichtenseite nach einem bestimmten Thema. Die geteilten Pipes zeigen was andere damit anfangen, und ich hatte im Pipes-Blog eine kleine Artikelsammlung darüber geschrieben, was die Seite so kann.
Auf jeden Fall war diese Webanwendung bisher nicht offen. Auf der einen Seite muss sowas natürlich auch mal okay sein, andererseits ging mir das auch etwas gegen den Strich, und es ist gerade bei Pipes ein bisschen kritisch gewesen. Denn der Vorgänger (mit dem ich nichts zu tun hatte) wurde erst nicht weiterentwickelt, dann abgeschaltet. Klar, dass dann nicht jeder Zeit (oder gar Geld) in eine SaaS-Seite investieren will, bei der das wieder passieren könnte. Die neue freie Version soll gegen solche Bedenken helfen.
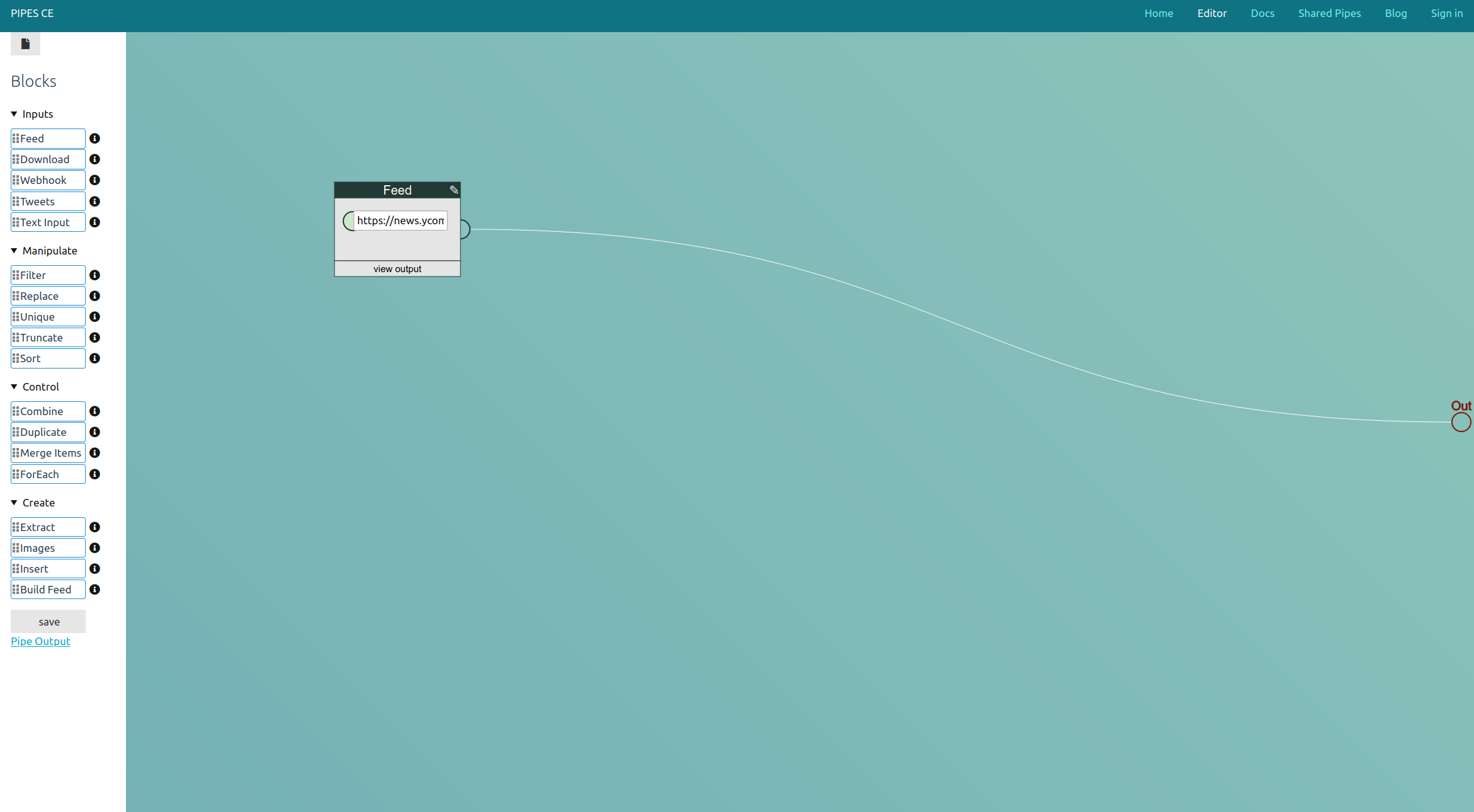
Pipes CE ist eine Ruby/Sinatra-Anwendung. Sie kann einfach installiert werden und läuft dann eben auf dem eigenen Rechner oder Server. Der Funktionsumfang ist momentan nicht geringer als bei Pipes, nur Zeug wie die Stripeeinbindung habe ich herausgenommen. Das Design ist auch angepasst, es soll ja nicht identisch aussehen. Im Laufe der Zeit könnte sich noch ändern wie ähnlich die beiden Versionen sich sind. Wie es jetzt weitergeht ist nicht genau durchgeplant und hängt ja auch davon ab, ob noch andere gerne mit der Software spielen wollen.
Mein Blogsystem ursprung ist jetzt 1.0
Sunday, 16. February 2020
Während hier Serendipity läuft, setzt der Blog von pc-kombo auf ursprung. Das ist eine von mir in Ruby/Sinatra geschriebene Blogengine, gestartet als Experiment für Blogs als dezentrales soziales Netzwerk, inzwischen auf das wesentliche reduziert – aber eben nicht minimaler als das, es ist kein Generator für statische Seiten, sondern ein echter Blog mit Kommentaren, Tags, Trackbacks, Designs; samt Spamfilter, Editor und Markdown.
Für mich ist es weiterhin praktisch diese Alternative zu haben, die besser zu meinem bisher üblichen Serverstack passt: Ruby hinter Nginx. Da ist ursprung einfacher einbaubar als die meisten anderen Blogengines.
Die bestehende Installation werkelte jetzt ein paar Jahre fleißig vor sich hin, aber ich hatte das Repository etwas vernachlässigt und nicht alle dann doch angefallenen Patches dort sauber eingebaut. Beispielsweise funktionierte der Installer nicht mehr, weil er noch Browserid aufrufen wollte. Alles derartige ist jetzt bereinigt. Außerdem ging ich die Baustellen an, die mich bei einer Neuinstallation störten: Nokogiri zum Beispiel, das kompiliert werden muss und daran auf den Servern immer wieder scheitert, wurde durch das unproblematischere Oga ersetzt.
Um das zu verdeutlichen bekam ursprung auch endlich ein richtiges Release, die 1.0. 2015(!) hatte ich zuletzt mit der 0.1 einen Entwicklungsstand markiert, ab dem es ein echter Blog war und stabil zu laufen schien.
Das etwas angepasste und übersetzte Changelog:
- Der Editorinhalt wird im Browser zwischengespeichert, damit geschriebene Einträge nicht verlorengehen
- Einige Designs des classless-Projekts werden mitgeliefert.
- Wie oben beschrieben, Oga ersetzte Nokogiri. Dafür wurden auch ein paar andere Abhängigkeiten ausgewechselt.
- Einträge setzen einen Link als canonical, weil ähnlich wie bei Serendipity der Abschnitt hinter der id frei angepasst werden kann (und solcher duplicate content von Google nicht geschätzt wird)
- Der RSS-Feed validiert
- Login: Portier ersetzt Browserid/Persona
- Das Portier-Loginformular ist jetzt auch auf seiner eigenen Seite, ich fand das für Besucher zu störend.
- Fix: Trackbacks verschluckten sich an Leerzeichen in der URL
- Fix: Die Undo-Funktion für gelöschte Einträge ging nicht mehr, weil dabei die inzwischen aus Browsern entfernte Javascript Funktion
containsaufgerufen wurde.
Im Zweifel ist das nur Aufräumarbeit, die mir zugute kommt wenn ich ursprung woanders einsetze (Pipes z.B. sollte auch einen Blog haben). Wenn es noch jemandem sonst hilft, um so besser.
Rubys FastGettext ist tatsächlich schnell
Thursday, 19. December 2019
Ich war mal wieder am Performance-Debuggen von pc-kombo. Die Seite soll schneller laden, wenn der Cache noch nicht befüllt ist, was doch immer wieder Besucher trifft. Dabei stolperte ich über diesen Abschnitt des Flamegraphs:
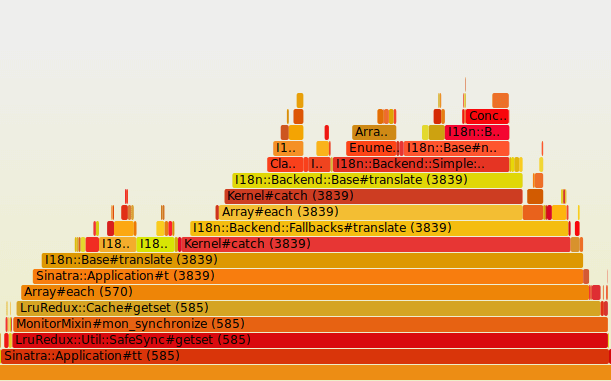
tt ist der Übersetzungshelfer, lru-redux der genutzte Cache, Grundlage das Gem i18n. Und dieser Abschnitt machte einen gewichtigen Teil des Seitenladevorgangs aus.
Also habe ich das alte Übersetzungssystem auf FastGettext umgestellt. Der Code in Sinatra sieht in etwa so aus:
helpers do
include FastGettext::Translation
def t(token, opts = {})
_(token.to_s) % opts
end
end
configure do
FastGettext.add_text_domain('pckombo', path: 'locales', type: :yaml)
end
before do
FastGettext.text_domain = 'pckombo'
if request.env['HTTP_ACCEPT_LANGUAGE']
languages = HTTP::Accept::Languages.parse(request.env['HTTP_ACCEPT_LANGUAGE'])
languages.each do |language|
case language.locale
when /en[_]*/
FastGettext.locale = "us"
break
when /de[_]*/
FastGettext.locale = "de"
break
when /fr[_]*/
FastGettext.locale = "fr"
break
when /es[_]*/
FastGettext.locale = "es"
break
end
end
end
end
Die alten yaml-Übersetzungen konnten weiterverwendet werden. So beginnt z.B. die locales/de.yml:
de:
cpu: Prozessor
Es ist also fast eine einfach so einsetzbare Alternative mit minimalen Codeänderungen.
Das Ergebnis:

Die Übersetzungen beim ersten Laden brauchen nun einen Bruchteil der Zeit. Das beste daran: Das wird nicht nur den speziellen Seitenaufruf beschleunigen den ich da betrachtet hatte, sondern generell der gesamten Webseite helfen.
Wer Übersetzungen in Ruby umsetzen muss, für den ist FastGettext ist definitiv einen Blick wert.
Wenn ein fehlender Index den Server lahmlegt
Monday, 10. September 2018
In letzter Zeit hatte ich bei meinem PC-Hardwareempfehler pc-kombo mit Performanceproblemen zu kämpfen. Auf meinem Rechner lief die Anwendung lokal gut. Aber wenn mehrere Besucher auf dem Server waren brach desöfteren die Performance ein. Und zwar aller Seiten, die irgendwie auf die SQLite-Datenbank zugriffen oder kompliziertere Berechnungen durchführten.
Bis hierhin hatte ich schon einige Stellen der Serveranwendung optimiert. Die Preisaktualisierung – für die große XML-Dateien geparst werden müssen, was die Serverperformance beeinträchtigen konnte – wurde auf einen zweiten Server ausgelagert, das war die größte Aktion. Geschickter und ebenfalls mit großem Effekt: Ein Cache verhindert das unnötige Neuberechnen des besten PCs für einen bestimmten Preispunkt, solange sich die Komponentenpreise nicht geändert haben. Übersetzungen werden nun genauso im Arbeitsspeicher zwischengespeichert, was die Customize-Funktion beschleunigt. Die Berechnung der Durchschnittsgröße eines Gehäuses wird nur noch durchgeführt, wenn die Detailseite eines Gehäuses mit dem Größenvisualisierer angezeigt wird, und so weiter. All das half, doch es war nicht die Ursache des Grundproblems. Dafür wurde das nun sichtbar.
Schuld an den Performanceeinbrüchen war wohl eine einzelne Datenbankabfrage.
Der Debugweg
Nach all den vorherigen Verbesserungen stach eine Seite als noch besonders langsam heraus: Die Detailansicht einer Komponente, z.B. die des Prozessors i7-8700K. Auf dem lokalen Rechner mit Testdaten war diese Seite allerdings schnell. Ich entschloss mich, trotzdem erstmal dort zu debuggen, da der langsamste Abschnitt auf meinem Rechner ja auf dem Server noch problematischer sein und die längere Verzögerung verursachen könnte.
Zum Performance-Debuggen benutze ich ruby-prof mit ruby-prof-flamegraph. Über die Gemseite finden sich gute Erklärungen. Bei mir sieht der gekürzte Code so aus:
get '/:country/product/:type/:ean' do |country, type, ean|
if settings.development?
require 'ruby-prof'
require 'ruby-prof-flamegraph'
begin
RubyProf.start
rescue RuntimeError => re
RubyProf.stop
RubyProf.start
end
end
html = doStuff()
if settings.development?
result = RubyProf.stop
printer = RubyProf::FlameGraphPrinter.new(result)
File.open("profiling/profile_data", 'w+') { |file| printer.print(file) }
end
html
end
Die Datei profiling/profile_data kann ich dann mit flamegraph.pl visualisieren:
flamegraph.pl --countname=ms --width=1920 < profile_data > product.svg
Und das sah so aus:

Mit 73% ging der größte Teil der Rechenzeit also in Hardware#priceHistory verloren. Auf meinem Rechner war das weniger als eine Sekunde. Aber auf dem Server hatte das Laden der Seite vorher – unter Last – ~8 Sekunden gedauert. Dort würde diese Funktion wohl ebenfalls den größten Teil der Rechenzeit ausmachen, vermutete ich.
Was macht priceHistory? In Grunde führt es diesen SQL-Query aus:
SELECT * FROM pmdb.priceHistory WHERE ean = ? AND (vendor = ? OR vendor = ?) ORDER BY date ASC
Ein ziemlich simples Select. Doch der Query-Plan sah nicht gut aus:
EXPLAIN QUERY PLAN SELECT * FROM priceHistory WHERE ean = "05032037108652" AND (vendor = "vendor1" OR vendor = "vendor2") ORDER BY date ASC; 0|0|0|SCAN TABLE priceHistory 0|0|0|USE TEMP B-TREE FOR ORDER BY
SCAN TABLE priceHistory ist der problematische Teil hier. Diese Erklärung bedeutet, dass zum Erfüllen dieser Abfrage die gesamte Tabelle gelesen werden muss. Aber wie groß kann eine solche Tabelle mit etwas Preishistorie schon sein?
du -sh /home/pc-kombo/www.pc-kombo.de/productMeta.db 823M /home/pc-kombo/www.pc-kombo.de/productMeta.db
Upps. Nicht alles davon sind die Preisdaten. Aber der größte Teil.
Um also die Detailseite anzuzeigen musste der Server jedes mal eine 800MB große Tabelle auslesen. Das führte dazu, dass ein Prozessorkern für ein paar Sekunden komplett ausgelastet war (was in Sprachen wie Ruby ohne echten Parallelismus besonders problematisch ist), und auch die Festplatte wurde dadurch natürlich komplett in Beschlag genommen. Kein Wunder, dass dann auch die anderen Seitenaufrufe langsam wurden.
Hier hilft normalerweise ein Index:
CREATE INDEX priceHistory_ean_vendor ON priceHistory(ean, vendor);
Und tatsächlich:
EXPLAIN QUERY PLAN SELECT * FROM priceHistory WHERE ean = "05032037108652" AND (vendor = "vendor1" OR vendor = "vendor2") ORDER BY date ASC; 0|0|0|EXECUTE LIST SUBQUERY 1 0|0|0|USE TEMP B-TREE FOR ORDER BY
Der Index wird direkt genutzt. Und so viel bringt das in Praxis:

Alleine durch diesen einen Index ist die Preishistorie nun nicht mehr der größte Zeitfaktor in der Berechnung, sondern mit 16% einer von mehreren. Und htop bestätigt das, denn bei dem Seitenaufruf schießt die Prozessorlast des einen Kerns nun nicht mehr auf 100%, sondern bleibt irgendwo unter 10%. Dementsprechend werden auch die anderen Seiten nicht mehr ausgebremst.
Die eigentliche Ursache
Es ist fast immer problematisch, wenn ein Provisorium länger genutzt wird als geplant. Genau das ist hier passiert. Als ich die Preishistorie entwickelte wollte ich die Preise nur für wenige Wochen in der Datenbank speichern. Die eigentliche Lösung sollte eine Zeitseriendatenbank wie rrdtool sein. Solche Datenbanken können die Datenmenge begrenzen, in dem für längere zurückliegende Zeiträume Datenpunkte entfernt werden. Statt den Preis einer Grafikkarte von vor zehn Jahren alle 5 Minuten parat zu haben, speichert rrdtool dann eben nur den Durchschnittspreis einer zehn Jahre zurückliegenden Kalenderwoche. Und bestimmt wäre bei der richtigen Lösung dann auch der Index gesetzt gewesen.
Stattdessen blieb das Provisorium bestehen, bis die Datenmenge so sehr anstieg, dass der fehlende Index – dessen Fehlen beim Entwickeln mit den wenigen Datenpunkten ja noch kein Problem war – den Server ausbremsen konnte.

