Artikel mit Tag ursprung
Das perfekte Blogsystem
Wednesday, 11. May 2022
Ich fand mich bei einem Gedanken: Wie sähe das perfekte Blogsystem aus? Mit Serendipity bin ich mit dem hier laufendem klassischen PHP-Blogsystem ziemlich vertraut, mit ursprung habe ich mich an einem auf Ruby/Sinatra-basierendem Blogsystem mit ein paar alternativen Ideen versucht. Ich kenne Grundzüge von anderen Systemen wie Jekyll, Wordpress und ProcessWire, außerdem habe ich zwei Generatoren für statische Seiten geschrieben. All diese Lösungen haben Stärken und Schwächen, aber gibt es eine perfekte Kombination für Blogs?
Statisch und dynamisch
Wenn vom Leser eine Blogseite aufgerufen wird sollte diese nicht vom System dynamisch gerendert werden. Es sollte eine statische HTML-Seite sein, die der Webserver direkt ausliefern kann. Dem nahezukommen, das ist was die Cache-Plugins bei Wordpress und Serendipity versuchen, was aber nie optimal funktionieren kann wenn das Grundsystem dynamisch ist. Der Vorteil davon ist Performance: Zum einen geht der Server viel später in die Knie wenn ein Artikel mal populär wird, zudem ist im Normalbetrieb der statische Blog immer schneller als ein dynamisch generierter.

Das Blogsystem sollte aber nicht einfach ein statische Seiten auswerfender Generator sein. Denen fehlt zu viel was einen Blog ausmacht: Kommentare, Trackbacks/Pingbacks, auch das Backend mit seinen Moderatorfunktionen, dem Artikeleditor und der Mediendatenbank. Das sind nur ein paar der wichtigsten Funktionen, auf die ein perfektes System nicht verzichten würde. Dazu kommen beispielweise Dinge wie die Unterstützung mehrerer Nutzer, Veröffentlichungsworkflows, Rechteverwaltung und sicher noch viel mehr, was ich teilweise unten beschreibe.
Das perfekte Blogsystem wäre also zweigeteilt: Im Frontend würden statische Seiten generiert, aber parallel liefe ein dynamisches Backend, das Aufgaben wie das Entgegennehmen von Kommentaren übernimmt.
Stabilität, Erweiterbarkeit und Kompatibilität
Ein perfektes System wäre stabil. Damit meine ich inbesondere den Code und seine Sprache. PHP mit seinen fortwährenden Kompatiblitätsbrüchen ist beispielsweise eine besonders instabile Grundlage, die fortlaufend Entwicklungsarbeit verlangt. Das ist absurd für die Webumgebung, ist die doch grundsätzlich stabil: Selbst vor 30 Jahren erstellte HTML-Seiten können Browser von heute noch anzeigen. Es wäre also viel gewonnen, wenn das System um den Blog zu erstellen ebenfalls einmal gebaut werden könnte und dann gleichsam in 30 Jahren noch HTML/CSS und JS ausspuckt, dann zwar auf veraltetem Stand, der aber sicher noch verstanden werden würde.
Gleichzeitig sollte das System einfach erweiterbar sein. Was derzeit gute Blogsysteme auszeichnet ist ihr Pluginsystem und die Themebarkeit, sodass Entwickler mit wenig Aufwand das System anpassen können. Neue Logik hinzufügen und mit einem Theme die HTML-Ausgabe bzw das Design anpassen zu können, das ermöglicht die Anpassung an sich ändernde Zeiten ohne dauernd der Kern überarbeiten zu müssen.
Weil Blogs im Zweifel schon existieren bräuchte es im Sinne der Stabilität Importer. Die müssten Artikel so importieren können, dass ihre URL sich nicht ändert, wobei unter der alten URL Weiterleitungen auf eine neue sein könnten und Übersichtsseiten meiner Meinung nach nicht unbedingt erhalten bleiben müssen. Auch die Kommentare würden importiert. Bei der Frage wo die Daten dann landen bin ich zwiegespalten: Was ist perfekter, ein System das viele Datenbanken unterstützt oder eines, das sich auf SQLite konzentriert?
Umfassende Kompatibilität bedeutet auch die vollständige Unterstützung von Unicode. Wobei die Realität nunmal ist, dass alte Blogs in anderen Encodings geschrieben wurden. Ein perfekter Importer würde das konvertieren können.
Viele Standardfunktionen
In die großen Blogsysteme sind tausende Arbeitsstunden geflossen, in die meisten kleinen bestimmt immer noch hunderte. Entsprechend groß ist ihr Umfang. Schauen wir uns nur mal an was diesen Artikel hier von einem rohen handgeschriebenen HTML-Artikel unterscheidet.
So ist er nicht einfach in HTML geschrieben, sondern ist der rohe Text eine Mischung aus HTML und einer individuellen Markupsprache. Mit ihr sind Links einfacher setzbar. Umbrüche brauchen dank den nl2p-Plugin keine HTML-Tags. Zum Formatieren des Textes kann ich HTML oder die Markupsprache schreiben, aber alternativ sind hier auch Buttons beim Editor die das übernehmen können. Andere Systeme (und Serendipity optional) haben eine WYSIWYG-Ansicht oder eine Autovorschau, sodass der rohe Text schon beim Schreiben umgewandelt wird. Serendipity mit meinen Einstellungen hat dafür immerhin eine verlässliche Vorschau per Buttonklick, sodass ich Layoutfehler sehen kann bevor ich Artikel veröffentliche.
Im <head> ist in der Artikelansicht eine Anweisung für Suchmaschinen den Artikel zu indexieren, auf Übersichtsseiten dagegen wird das indexieren verboten. Es sind Tags gesetzt um den Artikel auf Twitter etc hübscher zu machen wenn er verlinkt wird, dabei wird auch ein Vorschaubild gesetzt, falls ich diesem Text noch ein Bild aus der Bibliothek hinzufüge wird dieses dafür benutzt werden. Thema Bilder: Die sind responsiv, kleine Bildschirme bekommen so kleinere und sparen Bandbreite.
Beim Schreiben kann ich komfortabel Schlagwörter und Kategorien zuweisen. Ich könnte den Artikel als Entwurf speichern oder die Veröffentlichung auf einen Moment in der Zukunft festsetzen. Er könnte dann sogar passwortgeschützt werden. Veröffentliche ich ihn, werden automatisch Trackbacks ausgesendet, was ich im Backend aber auch abstellen kann.
Gibt es nachher Kommentare kümmern sich direkt drei Plugins mit verschiedenen Ansätzen darum Spam auszusondern. Die sind so gut, dass Spam nur selten durchkommt. Wenn doch bekomme ich eine Email, wie auch bei legitimen Kommentaren. So kann ich auf die schnell reagieren. Eingehende Kommentare werden in einer Thread-Ansicht dargestellt, sodass Kommentatoren einander antworten können. Und natürlich gibt es für die Kommentare einen RSS-Feed, wie auch für die Artikel selbst und alle Kategorien.
Würde ich den Artikel dagegen in ursprung schreiben wäre der Editor komfortabel im Frontend auf der Startseite, der Kontextwechsel in ein Backend unnötig. Auch das ist eine Qualität, die ein perfektes System abdecken oder trumpfen müsste.
Und so ginge das jetzt sicher noch eine Weile weiter wenn ich alles aufzählen wollte. Man sieht schnell wie breit dieses Feld ist, wie viel ein neues System unterstützen müsste um auch nur gleichwertig zu sein.
Konkurrenz und Entwickler
Es gibt ziemlich viele Blogengines und CMS. So viele, dass es unmöglich ist einen Überblick zu behalten. Gleichzeitig gibt es mit Wordpress einen absoluten Gewinner, mit dem das halbe Internet läuft. Tatsächlich sehe ich das als Faktor: Ein perfektes System würde in einer Umgebung existieren in der es sichtbar werden kann, sodass seine Existenzberechtigung auch klar wird. So erwarte ich fast, dass ein Kommentator mir ein System benennen wird was den oben beschriebenen Ansatz teilt.
Und klar: Ein perfektes Blogsystem würde von einem aktiven Team netter und fähiger Entwickler geschrieben. Es wäre so perfekt, dass ich es nicht schreiben müsste (und auch nicht könnte). FOSS wäre es selbstverständlich auch. Sein Code wäre minimal, hätte keine instabilen Abhängigkeiten und wäre hervorragend lesbar.
Fazit
Wie seht ihr das, was habe ich vergessen? Ist was ich oben beschreibe überhaupt perfekt oder hätte sogar das beschriebene schon Macken?
Natürlich juckt es mich in den Fingern mich an einem solchen System zu versuchen. Dabei wäre das Ergebnis unzweifelhaft nicht perfekt – viele der Details wie die richtige Unterstützung der Markupsprachen und ob man das Markup oder das HTML speichert haben nicht die eine richtige Lösung – und einige der Anforderungen oben wie die Importer sind eine fast umstemmbare Mammutaufgabe, aber die Grundidee des statischen Frontends und dynamischen Backends umzusetzen hätte was. Sie hat generell derzeit etwas Aufwind, so geht Jamstack in die gleiche Richtung, ich sah in dem Kontext nur noch keine Umsetzung eines vollständigen Blogsystems.
Aber selbst wenn ich alle meine anderen Projekte zur Seite legen und mich der perfekten Blogengine widmen wollte: Scheiterte es nicht schon an der Sprachwahl? PHP wäre hier wegen seiner Instabilität offensichtlich Unsinn, wobei sein riesiger Vorteil der Hosterunterstützung damit wegfällt und schon deswegen eine Lösung ohne PHP kaum perfekt sein kann. Ich liebe Ruby, aber auch diese Sprache liefert nicht die Stabilitätsgarantien die das Projekt bräuchte. Ob Python da besser wäre erscheint nach dem Sprung auf Python 3 unwahrscheinlich. Vielleicht bräuchte es statischere Sprachen wie Rust, C oder Golang, aber komfortabel für Webanwendungen sind die nicht – und bei ihnen stolpere ich immer wieder über Projekte, die sich auf meinem System nicht kompilieren lassen. Stabilitätsgarantien in meinem Sinne gibt es da also nicht.
Was bleibt da? Etwas Lispiges wie Erlang, Common Lisp oder Racket? Etwas altgedientes wie TCL oder Perl? Eine Nischenlösung wie D?
Da erscheint direkt der erste Schritt zu schwierig.
Man nehme trotzdem den Gedanken mit, dass unsere Blogsysteme ziemlich gut, bessere Lösungen aber vorstellbar sind.
Mein Blogsystem ursprung ist jetzt 1.0
Sunday, 16. February 2020
Während hier Serendipity läuft, setzt der Blog von pc-kombo auf ursprung. Das ist eine von mir in Ruby/Sinatra geschriebene Blogengine, gestartet als Experiment für Blogs als dezentrales soziales Netzwerk, inzwischen auf das wesentliche reduziert – aber eben nicht minimaler als das, es ist kein Generator für statische Seiten, sondern ein echter Blog mit Kommentaren, Tags, Trackbacks, Designs; samt Spamfilter, Editor und Markdown.
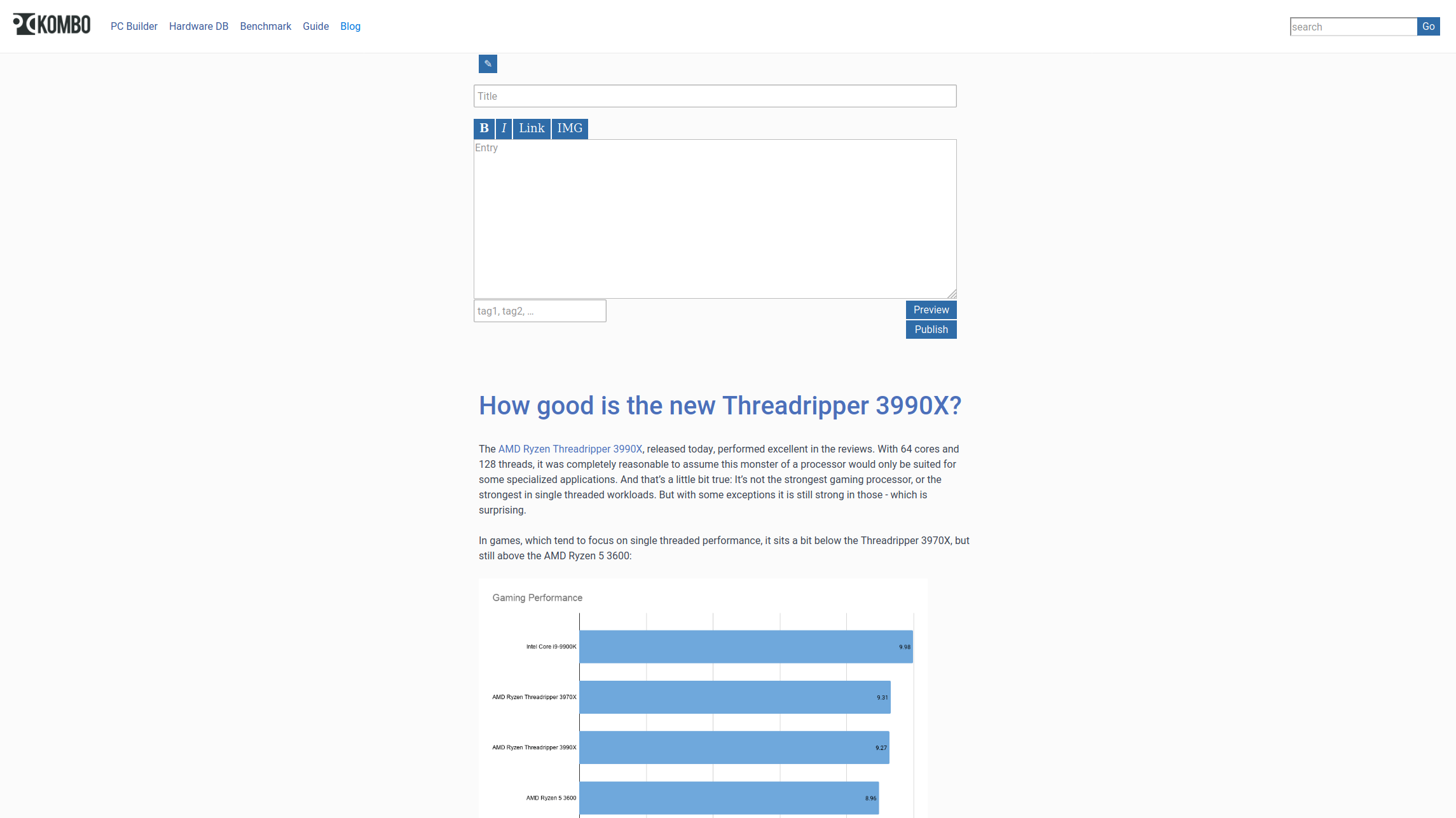
Für mich ist es weiterhin praktisch diese Alternative zu haben, die besser zu meinem bisher üblichen Serverstack passt: Ruby hinter Nginx. Da ist ursprung einfacher einbaubar als die meisten anderen Blogengines.
Die bestehende Installation werkelte jetzt ein paar Jahre fleißig vor sich hin, aber ich hatte das Repository etwas vernachlässigt und nicht alle dann doch angefallenen Patches dort sauber eingebaut. Beispielsweise funktionierte der Installer nicht mehr, weil er noch Browserid aufrufen wollte. Alles derartige ist jetzt bereinigt. Außerdem ging ich die Baustellen an, die mich bei einer Neuinstallation störten: Nokogiri zum Beispiel, das kompiliert werden muss und daran auf den Servern immer wieder scheitert, wurde durch das unproblematischere Oga ersetzt.
Um das zu verdeutlichen bekam ursprung auch endlich ein richtiges Release, die 1.0. 2015(!) hatte ich zuletzt mit der 0.1 einen Entwicklungsstand markiert, ab dem es ein echter Blog war und stabil zu laufen schien.
Das etwas angepasste und übersetzte Changelog:
- Der Editorinhalt wird im Browser zwischengespeichert, damit geschriebene Einträge nicht verlorengehen
- Einige Designs des classless-Projekts werden mitgeliefert.
- Wie oben beschrieben, Oga ersetzte Nokogiri. Dafür wurden auch ein paar andere Abhängigkeiten ausgewechselt.
- Einträge setzen einen Link als canonical, weil ähnlich wie bei Serendipity der Abschnitt hinter der id frei angepasst werden kann (und solcher duplicate content von Google nicht geschätzt wird)
- Der RSS-Feed validiert
- Login: Portier ersetzt Browserid/Persona
- Das Portier-Loginformular ist jetzt auch auf seiner eigenen Seite, ich fand das für Besucher zu störend.
- Fix: Trackbacks verschluckten sich an Leerzeichen in der URL
- Fix: Die Undo-Funktion für gelöschte Einträge ging nicht mehr, weil dabei die inzwischen aus Browsern entfernte Javascript Funktion
containsaufgerufen wurde.
Im Zweifel ist das nur Aufräumarbeit, die mir zugute kommt wenn ich ursprung woanders einsetze (Pipes z.B. sollte auch einen Blog haben). Wenn es noch jemandem sonst hilft, um so besser.
dsnblog wird ursprung
Monday, 27. April 2015
Ich habe mein Blogsystem dsnblog in ursprung umbenannt und ihm eine Vorstellungsseite gebaut.
Dsnblog - distributed social network blog - passte nicht mehr wirklich. Das war ein treffender Name, als der Blog nur Mittel zum Zweck für ein verteiltes Soziales Netzwerk sein sollte. Das weiterzuverfolgen habe ich aber aufgegeben, dafür fehlten mir die Ressourcen. Dsnblog war damit nur noch ein Blog, das sollte ein neuer Name widerspiegeln.
Ursprung ist natürlich ein seltsamer Name. Ich hoffe, er ist auch merkwürdig. Namen sind schwer, und alle naheliegenden mindestens von einem Blog besetzt. Und ich wollte unbedingt ein deutsches Wort als Namen, jetzt, wo ich nicht mehr in Deutschland wohne. Der Name soll auf die Entstehungsgeschichte der Software und auf meinen Feedreader feedtragón verweisen - der Blog als Quelle des Feeds für den Feedgierer, das passt auch generell als Beschreibung der Funktion von Blogs im System Internet. Wahrscheinlich ist das alles aber gar nicht wichtig.
Anlass des Ganzen war, dass ich die Software jetzt für einen kleinen Projekt-Blog benutzt habe, also weiß, dass sie im Grunde auch im Internet wirklich funktioniert.
Auf der Vorstellungsseite wollte ich vor allem die mehrspaltige Feature-Beschreibung ausprobieren, die ich damals für Serendipity vorgeschlagen hatte. Bin jetzt gar nicht so sicher, ob ich das Ergebnis mag, es ist textlastiger geworden als ich dachte, und ich finde es schwierig, passende Bilder zu finden. Mit der Seite als ganze bin ich aber erstmal zufrieden und hoffe, sie gefällt auch euch ein bisschen.

