Artikel mit Tag serendipity
15 Jahre Serendipity als Entwickler - ein Rückblick und ein Ausblick
Monday, 27. November 2023
Es ist jetzt ziemlich genau 15 Jahre her, dass ich das erste mal als Entwickler an der Blogsoftware Serendipity gewerkelt habe. Zumindest sagt so mein Archiv. Und mir ist in dieser Winterzeit melancholisch, sodass ich zurückblicken will, gleichzeitig suche ich einen Ort um Zukunftspläne für Serendipity aufzuschreiben. Mach ich beides doch hier.
Rückblick
Ich hatte nie vor, an Serendipity zu arbeiten. Es war kein geplantes Projekt. Es war vielmehr so, dass ich meinen Blog von einer Blogplattform (twoday.net) umzog, Dirk mir Zuflucht aus seinem Server anbot und dabei Serendipity als Blogsoftware vorschlug. Als ich die Software einmal am Laufen hatte, wollte ich auch meinen Blog anpassen. Das tat ich. Und als ich dann merkte, dass auch im Projekt selbst Platz dafür wäre, rutschte ich da langsam rein.
Beginn mit Plugins, Dokumentation und kleinen Anpassungen
Es war ein Plugin zur Livevorschau der Kommentare, das ich damals zuerst in den Blog stellte. Erinnere ich mich richtig war das meine erste Begegnung mit PHP und jQuery. 2008 dürfte ich im Informatikstudium gewesen sein, bekam dadurch also etwas Programmierübung, brauchte aber dringend mehr. Serendipity bot sich dafür damals sicher an.
Generell hatte mich der Kommentarbereich ziemlich gepackt. Den wollt ich in meinem Blog so gut wie möglich haben. Daher wohl auch das Plugin. Ich ergänzte das dann durch Änderungen am Design des Bereichs selbst. Noch heute sind mir Kommentare wichtig – und für mich ist es auch amüsant, das solche Nutzbarkeitsüberlegungen später mal mein Beruf wurden. Bei manchen Dingen war ich die letzten Jahre ziemlich konstant.
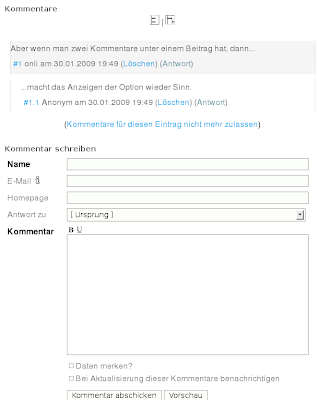
Es folgt ein Plugin für Markupbuttons im Kommentarformular, das existiert vom Konzept heute noch so und ist immer noch praktisch. nl2p danach war eine Fortführung meiner Auseinandersetzung mit dem Webteam von UbuntuUsers, die sich geweigert hatte Nutzer neue Zeilen ohne nötige Leerzeile setzen zu lassen – mir war es wichtig zu beweisen, dass die technische Argumentation dagegen vorgeschoben war. Der Code dafür lebt heute im nl2br-Plugin, von Stephan gründlich überarbeitet. Autotitel danach war eine gute Idee, es setzte den Titel der verlinkten Seite als Titel des Links. Es krankte aber an den Limitierungen der PHP-Plattform; Das müsste im Hintergrund geschehen, was aber nicht ging (nicht geht sogar!), daher setze ich es heute nicht mehr ein.
Das wichtigste Plugin war aber sicher das Bayes-Plugin, eine Kooperation mit dem Forumnutzer kleinerChemiker. Wir nahmen einen Bayes-Filter und ließen den zur Spamerkennung über Blogkommentare laufen und stellten fest: Das funktioniert super. Gleiches gilt heute noch, auch wenn der Code deutlich überarbeitet wurde und die neueste Version des verschlankten Plugins den Bayes-Filter als Library nutzt. Das Bayes-Plugin läuft heute noch hier und in einigen anderen Serendipity-Blogs.
Als ein guter Schlusspunkt für diese Zeit taugt die Anleitung zum Pluginschreiben, traute ich mir also inzwischen zu sowas zu verfassen. Und dann wurde es etwas ruhiger. Es gab noch den Template-Editor, woraus man heute wahrscheinlich was nutzbareres formen könnte. Aber im Grunde war ich mit den Pluginideen durch und genug damit beschäftigt, die meinen am Leben zu halten.
Wenn ich mir die Artikel von damals ansehe kommen neben den Plugins nun langsam andere Überlegungen dazu. Zum Beispiel die, dass man die Suche verbessern könnte. Auch, dass Archiv-URLs stabil sein sollten, was inzwischen wirklich fest im Kern ist und absolut richtig war. Oder ich erwähnte früh, dass dem Adminbereich eine Überarbeitung gut tun würde. Und genau das sollte später folgen.
Die 2.0-Überarbeitung
Mit Serendipity 2.0 war ich dann wirklich als Serendipity-Entwickler aktiv. Vorher hatte ich ein paar kleinere Patches eingebracht und wie oben gezeigt an meinen eigenen Plugins gearbeitet. Aber 2.0 war eine andere Dimension.
Wir – 2.0 war eine große Teamarbeit – hatten damals erkannt, dass Serendipity ein Problem hatte: Der Adminbereich war damals eine ziemlich wüste Implementierung. Er bestand komplett aus PHP-Dateien, die den Großteil der Logik sowie das gesamte HTML beinhalteten. Meine vorherigen Ideen zur Verbesserung des Bereichs waren so überhaupt nicht umsetzbar, das HTML war nicht editierbar. Und das war ein Tabellenlayout, natürlich, wohl geschrieben von vor-CSS geprägten Entwicklern. Was nicht abfällig klingen soll, so hatte ich es ja auch zuerst gelernt.
Das Großprojekt in 2.0 war also die Smartifizierung des Blog-Backends. Smarty, weil das die Template-Sprache war, die auch in den existierenden Blog-Themes genutzt worden war. Wir machten das so: Wir rissen das HTML aus den PHP-Dateien, packten sie in Smarty-Templates, und wo immer vorher in den PHP-Dateien Logik die HTML-Ausgabe steuerte wurde stattdessen eine Variable gesetzt, die dann an die Smarty-Templates übergeben wurde. Wir, das waren meiner Erinnerung nach in dem Fall ophian und ich. Gleichzeitig war YellowLed dran, das so entstehende HTML zu verbessern und mit einem CSS-Design zu versehen. Wobei ich auf Backendseite half. Dafür trafen er und ich uns sogar in Mumble und besprachen die Änderungen. Das Ergebnis ist der heute noch genutzte Adminbereich.
Den stellte YellowLed sogar in einem Video vor:
Serendipity 2.0 war mir so wichtig, dass ich andere Probleme von Serendipity mit angehen wollte. So hieß es eine Weile, ein Problem für die Adaption von Serendipity sei ein fehlendes Theme für Bilderblogs. Also baute ich eines. Und weil ich schon dabei war gleich noch ein zweites, gedacht als Alternative für textlastige Blogs. Es freute den inneren Kern ersichtlich, aber hatte ansonsten nicht den gewünschten Effekt.
Wie auch Serendipity 2.0, wenn man ehrlich ist. Die große Anstrengung bewahrte vielleicht die Nützlichkeit der Software für moderne Browser (und Telefone!). Aber sie bewirkte nicht den großen Popularitätssprung, den zumindest ich mir für Serendipity erhofft hatte. Vielleicht war es zu wenig zu spät (wir brauchten viel länger als gedacht), vielleicht waren die Alternativen zu gut, vielleicht hatten wir Pech oder es war einfach nie in den Karten. Aber ich glaube wirklich, man kann den negativen Effekt davon am nächsten Abschnitt sehen.
PHP 7, 8 und das Team
Nach 2.0 wurde es bei mir im Blog etwas ruhiger um Serendipity.
Im Idealfall hätten wir 2.0 neue große Releases nachgeliefert. Aber das schafften wir nicht, die Luft war raus. Nachfolgende Releases hatten durchaus noch Neuerungen: Responsive Bilder und die Bildergalerien per Mediendatenbank, echtes UTF-8 für MySQL-Datenbanken, ein neuer Cache, Komfortverbesserungen wie das Aktualisieren aller Plugins auf einmal. Das fällt zumindest mir direkt ein. Aber das ist wenig im Vergleich zu einem neuen Backend, von der Sichtbarkeit und vom Aufwand her. Während also neue Entwickler die Lücke hätten füllen müssen, blieben die bis auf ein paar Ausnahmen aus – oder rannten gegen die gewünschte Backwards-Kompatibilität und gaben auf, das beobachtete ich gleich dreimal.
Auch neue Plugins von mir wurden seltener. Das VGWort-Plugin als nächstes größeres Plugin z.B. brauchte ein paar Jahre. Es ist kein Zufall, dass ich mich später zu einer Serendipity-Entwicklerwoche erst aufraffen musste (gute Idee übrigens, da kamen nette Sachen bei raus).
Es kamen mehrere Dinge zusammen. Tatsächlich war es nicht (nur) die Enttäuschung über dem fehlenden Nachhall von 2.0. So wechselte ich mein Studium bzw meinen Job und hatte mit jedem Wechsel weniger Zeit – Zeit, die sich Serendipity mit meinen anderen und inzwischen mir auch sehr wichtigen Projekten teilen musste, insbesondere PC-Kombo und Pipes. Und das zwischenzeitliche Auswandern nach Frankreich war auch ein Lebensumbruch, wo s9y erst später wieder reinpasste.
Aber so ähnlich ging es scheinbar auch den anderen, die an 2.0 beteiligt gewesen waren. Jeder wird seine Gründe gehabt haben. Aber Fakt ist: Nach 2.0 war der Code teils verbessert, das Projekt aber nicht gesünder, sondern es fehlten Entwickler. Und ich war im Konflikt: Sinnvoller, das Projekt sich heilen zu lassen und sich rauszuhalten? Oder im Gegenteil Arbeit reinzustecken, um Entwicklungen zu beschleunigen?
Gleichzeitig wurde wiederholte Anstrengung nötig, ob wir wollten oder nicht, was dann für mich entschied. Und zwar aufgrund der PHP-Updates. Sowohl bei PHP 7 (da war z.B. Serendipity 2.3 für die Versionen nach 7.1), als auch bei PHP 8, jede Punktversion dieser Versionen brach alten PHP-Code auf neue Art und Weise. Und Serendipity ist vollständig alter PHP-Code. Zwei Glücksfälle kamen bei PHP 8.0 zusammen und ermöglichten Serendipity 2.4: Ich hatte durch einen Jobwechsel wieder mehr Zeit und neue (bzw neue alte) Entwickler tauchten wie für PHP 7 eben doch auf, wie surrim, sodass das Projekt die Codemigration stemmen konnte. Trotzdem war PHP 8.0 für Serendipity ein Monster, das sich zum Glück seitdem nicht wiederholt hat.
Es gab also die großen Entwicklungsbemühungen durchaus noch. Auch von mir. Aber anstatt in schön sichtbares und präsentierbares zu fließen ging viel der Energie für die schnöde Kompatibilität mit neuen PHP-Versionen drauf. Dafür kann das Projekt nichts, aber es schadete ihm. Oder vll stimmt das nichtmal, vll ist Serendipity einfach erwachsen genug, dass weitere Änderungen abseits von Wartungsarbeit kaum nötig waren?
Ein möglicher Ausblick

Und damit kommen wir zum Ausblick. Serendipity ist eine ziemlich großartige Blogsoftware und ein Projekt, das sich jetzt viele Jahre gehalten hat, sich also viele weitere Jahre halten wird. Aber es ist auch ein Projekt geworden, das sich langsamer entwickelt und bei Releases hinterherhinkt. Für etablierte Software ist das in Teilen gut, es ist sogar Projektphilosophie, so stabil wie möglich zu sein. Aber klar, die Gefahr ist, dass irgendwann zu wenig Bewegung im Projekt ist, um neue Entwicklungen mitzugehen und die Software deswegen irgendwann sogar stirbt. Und nebenbei: Wenn ich mir die untere Liste anschaue beantworte ich meine Frage von oben mit nein, s9y hätte durchaus mehr aktive Entwicklungsarbeit gut vertragen können, das Innehalten war nicht nur Zeichen der fertigen Entwicklung.
Es ist jetzt leider ganz konkret davon auszugehen, dass ich in Zukunft wieder weniger oder sogar eine Weile gar keine Zeit haben werde – ich rechnete stattdessen mit mehr Zeit, aber es kam etwas dazwischen. Andere werden das abfangen. Aber was wird das Projekt überhaupt in Zukunft machen? Was würde ich angehen, wenn ich mehr statt weniger Zeit hätte, wenn gar jemand Entwicklungsarbeit an Serendipity sponsern würde? Das sind meine Überlegungen dazu:
Kompatibilität mit neuen PHP-Versionen
Weil das PHP-Projekt auf Rückwärtskompatibilität scheißt wird es ein gewichtiger Teil der zukünftigen Arbeit werden, Serendipity einfach am Laufen zu halten. PHP 8.3, gerade veröffentlicht, hat wieder Breaking Changes, es wird bei 8.4 nicht anders sein. Bestimmt treffen die uns. Und weh dem, der Serendipity an PHP 9.0 anpassen muss.
Dazu ist es ja nicht nur der Kern von Serendipity, der hier Arbeit erfordert. Sondern auch die vielen Plugins, von denen der Großteil keinen aktiven Maintainer hat. Warum auch, sie funktionierten Jahrzehnte vor sich hin. Die Themes genauso, sie können viel Arbeit erfordern, wenn wieder wie bei PHP 8.0 Smarty versagt und die Codeänderungen nicht auf der Ebene der Template-Engine abfedert.
Gleichzeitig ist diese Kompatibilität auch die Arbeit, die auf jeden Fall gemacht werden wird. Zu viele Entwickler nutzen Serendipity für ihre eigenen Blogs. Wenn nicht die derzeitigen Entwickler handelten, würden andere zugunsten ihrer eigenen Blogs die nötigen Codeänderungen schreiben und bestimmt auch teilen. Es ist die auf den ersten Blick besorgniserregendste Herausforderung, aber auf den zweiten die ungefährlichste.
Automatisierte Tests
Die Arbeit an den PHP-Versionen ist auch deswegen schwer, weil das Projekt hier nicht gut aufgestellt ist. Es fehlen automatisierte Tests für Serendipity selbst. Sie fehlen auch besonders für die Spartacus-Plugins. Es bräuchte einmal ein System, das interne Codestellen durch Unit-Tests absichert – das wäre mit Github auch gut umsetzbar und wir haben mit ersten Tests den Ansatz dafür. Aber es braucht vor allem zweitens ein Testsystem, das alle Plugins installiert und prüft, dass zumindest die Kernfunktionen des Blogs weiterhin funktionieren. Und das jeweils mit allen PHP-Versionen, den neuen wie den alten.
Das wäre einmalige Arbeit, vll eine Heidenarbeit sogar, die letzten Endes aber Arbeit sparen würde.
Webmentions
Von mir initial geschmäht, gab es in den letzten Jahren eine Bewegung namens IndieWeb. Grundsätzlich kompatibel mit der Idee von Blogs, scheinen die Akteure nicht in der alten Blogosphäre verhaftet gewesen zu sein. Ergo bauten sie Webmentions und erfanden Trackbacks neu, gerade so abgewandelt, dass sie inkompatibel sind.
Trotz meiner negativen Bewertung denke ich mittlerweile, dass Serendipity den Standard trotzdem unterstützen sollte. Neben Trackbacks und Pingbacks ist die Aufnahme von Webmentions kein technisches Problem. Es wäre fürs Projekt wichtig, solche neuen Impulse aufzunehmen und ggf. so neue Entwickler anzusprechen. Ich denke dabei ganz konkret beispielsweise an Beko Pharm – sein ist ein Blog, wie er früher mit Serendipity gebaut worden wäre, wofür sich Serendipity aber wahrscheinlich mehr in sein Dienstenetzwerk eingliedern müsste.
ActivityPub
Gleiche Denkrichtung: ActivityPub. Wir reden schon ewig davon, dass Kommentare zu Blogartikel in sozialen Netzwerken auch im Blog gespiegelt werden sollten. Denn der Blog sei das Zentrum der Netzpräsenz, die Heimat. Genau das wäre mit ActivityPub möglich, wenn auch nicht mit Facebook, so doch mit Mastodon und anderen föderalisierten Diensten. Genau so wäre es möglich, Blogs ohne den Umweg RSS direkt in Mastodon etc zu abonnieren, wenn Serendipity ein paar Daten aussenden und empfangen würde.
![]()
Es gibt dafür mit ActivityPhp sogar ein passend erscheinendes PHP-Projekt, mit dem das als Plugin oder Teil des Kerns relativ vernünftig umsetzbar erscheint.
Theme-Archäologie
Gleichzeitig sollte Serendipity seine Identität bewahren. Ich meine, seine Geschichte vielleicht sogar herausstellen. Ich zumindest beobachte an mir echte Freude, wenn ich einen klassischen Blog mit klassischem Design sehe. Und genau davon hat Serendipity eine Riesenauswahl im Spartacus-Repository.
Diese Themes sind aber wirklich alt. Gerade mit Serendipity 2.0 (bzw 2.1?) gingen sie teils richtig kaputt: Wir hatten damals auch das Standard-Frontend auf 2k11 umgestellt und damit weg vom tabellenbasierten vorherigen default-Theme. Damit können viele der alten Themes aber immer noch nicht umgehen. Teils habe ich sie für PHP 8.0 etwas repariert, aber da sind immer noch Darstellungsfehler. Plus: Auch das HTML ist teilweise arg veraltet.
Es wäre toll, das alles wirklich zu reparieren. Die alten Themes technisch so zu modernisieren, dass sie erstens ein responsives CSS-Layout ausgeben, zweitens richtig mit dem von Serendipity ausgegebenem neuem HTML und CSS (wie im Kommentarformular) zusammenarbeiten. Damit wäre ein derzeit kaputter Teil von Serendipity für Nutzer wieder ohne den derzeit entstehenden negativen Eindruck nutzbar und Serendipity würde gleichzeitig seine Geschichte betonen.
Spartacus modernisieren
Und schließlich würde ich Spartacus modernisieren.
Bei Spartacus stören mich drei Dinge:
- Um zu erkennen, ob ein Plugin eine neue Version verfügbar hat, muss die aktuelle Version ausgelesen und dafür die PHP-Datei (des Plugins auf dem eigenen Server) interpretiert werden. Stattdessen sollte die Versionierung über eine .INI oder .toml-Datei laufen, also per Metadatendatei. Das würde auch bei Inkompatibilitäten mit neuen PHP-Versionen helfen.
- Gleichzeitig muss für Spartacus auf einem Server jeden Tag XML-Dateien generiert werden. Die gehen dann an die Blogs, so wissen sie welche Versionen es auf Spartacus gibt. Eine Lösung ohne diesen Generierungsschritt wäre ausfallsicherer. Vielleicht könnten wir im Git-Repository durch einen Git-Task diese Liste der aktuellen Pluginversionen automatisch erstellen, wann immer sich eine der Metdatendateien ändert?
- Spartacus aktualisiert derzeit Themes nicht, nur Plugins. Themes werden einmalig heruntergeladen, aber Updates werden nicht erkannt. Gerade im Hinblick auf das obere Theme-Projekt wäre das aber nötig, plus auch um Updates für zukünftige Smarty-Versionen ausliefern zu können.
Spartacus ist ein Kernbestandteil der Nutzung von Serendipity, Änderungen daran wollen wohlüberlegt sein. Und die alte Infrastruktur ist für sich gesehen ziemlich beeindruckend. Trotzdem fände ich es wirklich gut, wenn Serendipity sich hier verbessern könnte.
Nutzeranforderungen und Nutzertests
Als letzter Zusatz: Serendipity war jetzt so lange Entwickler- und Feedback-gesteuert, dass man auch hier nochmal ansetzen könnte. Was machen Nutzer mit Serendipity, was sind die Stolpersteine, Anwendungsfälle.

Da könnte viel bei rauskommen, was dann weitere Entwicklungen steuern könnte. Und ich habe inzwischen wirklich die Erfahrung, solch eine Erhebung und Auswertung ordentlich durchzuführen. Aber für die dann angesagten Entwicklungen müsste das Projekt danach eben auch die Kapazitäten haben, sonst wäre der Aufwand verschwendet.
Soweit meine Überlegungen. Ich hoffe, die Retrospektive ist für den einen oder anderen Serendipity-Blogger interessant. Ob sie sich mit euren Eindrücken deckt? Es ist ja alles nur meine Perspektive, gefiltert durch ein paar verstrichene Jahre und durch das, was ich eben nicht in den Blog getan und seitdem vergessen habe. Und viel wird bewusst unterschlagen, der Artikel war eh schon zu lang.
Zu den Zukunftsplänen, ich habe natürlich keine Ahnung, ob irgendwas davon Realität werden wird. Vielleicht entwickelt sich ja sogar das PHP-Projekt in Zukunft verantwortungsbewusster und selbst die Gewissheit der Anforderungen von dort fällt flach. Ansonsten sind die Ideen vielleicht für den einen oder anderen Entwickler ansprechend und werden dadurch Wirklichkeit, selbst wenn ich nicht dazu komme. Oder meine verfügbare Zeit entwickelt sich ganz anders, als ich derzeit glaube… Vielleicht aber haben andere auch ganz andere Pläne, auch das könnte völlig okay sein.
Serendipity 2.4.0 ist draußen (das stabile Release für PHP 8.0)
Wednesday, 23. November 2022
Hier lief schon eine Weile die Beta der nun als Version 2.4.0 fertiggestellten neuen Serendipityversion, die jetzt auch hier der neuen Version weichen musste.
Hauptthema PHP 8
Was hat sich seit der Beta getan? Ein paar Beispiele:
Stephan hatte erkannt, dass das automatische Speichern des Editorinhalts kaputt war. Der Fix folgte. Matthias reparierte einen Fehler im Installer. Markus beschleunigte die Permalinkerstellung. Hanno machte die Artikelseite Spec-konformer. Mich nervte, dass beim Speichern von Templatekonfigurationen dessen Cache nicht immer neu erstellt wurde, und änderte das.
Aber der Fokus lag klar auf dem PHP-Support, wozu es auch seit Betabeginn noch einige Fixes gab. Im Kern und bei den Plugins.
Denn PHP 7.4 wird bei vielen Hostern nun abgeschaltet, deswegen auch das Release jetzt. Wir hätten ansonsten länger warten können und sicher noch mehr Bugs gefunden, nach Fehlerberichten mehr Plugins zum Laufen gebracht. Aber nun ging Warten nicht mehr und es ist auch gut, dass irgendwann der Zahn gezogen wird.
Führt euch bitte kurz vor Augen, was das für ein Projekt war und damit, was das für ein Release ist. PHP 8.0 hat vielen alten PHP-Code invalid gemacht, als altes Projekt besteht Serendipity zu 100% aus alten Code. Praktisch jede Codedatei schmiss nun Warnungen, es war anfangs erschreckend überfordernd. Im Kern wurden schließlich in einer gemeinsamen Anstrengung alle solchen Vorkommnisse angepasst, aber bei den Plugins war das illusorisch: Weder kennen wir alle Plugins, noch haben auch nur alle Spartacus-Plugins aktive Maintainer (hier wird Hilfe gebraucht!). Daher werden diese zumeist irrelevanten Warnungen nun unterdrückt (nur bei Beta und stabilen Versionen von Serendipity), was allerdings bei einem Serendipity-Teammitglied nicht zuverlässig funktioniert. Wenn es funktioniert macht es automatisch viele Plugins wieder kompatibel, ohne störende Warnmeldungen.
Allerdings hatte PHP 8.0 auch komplett inkompatible Änderungen, z.B. wenn von PHP-Kernfunktionen die Reihenfolge der Parameter geändert wurde. Das könnte gerade noch manche weniger populäre Plugins betreffen, die trotz der langen Betalaufzeit nicht getestet wurden und dann echte Fehler werfen. Da hilft nur Fehler melden, Fehler reparieren oder das Plugin zu löschen.
Ich wünsche viel Spaß mit der neuen Version und viel Erfolg beim Upgrade. Aktualisiert alle Plugins, deaktiviert das Kommentar-Seitenleistenplugin (wegen diesem Bug), habt während des Upgrades PHP 7.3 oder PHP 7.4 am Laufen. Das Upgrade sollte kein Problem sein (außer vll, wenn MySQL benutzt wird und die Beta noch nicht lief, wegen der utf8mb4-Umstellung, da braucht es dann ein Datenbankbackup), kritischer wird der dann folgende Test mit PHP 8.0. Wenn es dabei Probleme gibt hilft das Forum, aber bei inkompatiblen Plugins sollte wer kann die Ärmel hochkrempeln und sie (per Pull-Request im Github-Repo) für alle reparieren.
Tatsächlich freu ich mich riesig, dass dieses Release nun erschienen ist und auch über die drumherum gesehene Projektaktivität :) Auf dieser Grundlage wird das nächste Release (für PHP 8.1?) wohl wesentlich einfacher werden.
Das perfekte Blogsystem
Wednesday, 11. May 2022
Ich fand mich bei einem Gedanken: Wie sähe das perfekte Blogsystem aus? Mit Serendipity bin ich mit dem hier laufendem klassischen PHP-Blogsystem ziemlich vertraut, mit ursprung habe ich mich an einem auf Ruby/Sinatra-basierendem Blogsystem mit ein paar alternativen Ideen versucht. Ich kenne Grundzüge von anderen Systemen wie Jekyll, Wordpress und ProcessWire, außerdem habe ich zwei Generatoren für statische Seiten geschrieben. All diese Lösungen haben Stärken und Schwächen, aber gibt es eine perfekte Kombination für Blogs?
Statisch und dynamisch
Wenn vom Leser eine Blogseite aufgerufen wird sollte diese nicht vom System dynamisch gerendert werden. Es sollte eine statische HTML-Seite sein, die der Webserver direkt ausliefern kann. Dem nahezukommen, das ist was die Cache-Plugins bei Wordpress und Serendipity versuchen, was aber nie optimal funktionieren kann wenn das Grundsystem dynamisch ist. Der Vorteil davon ist Performance: Zum einen geht der Server viel später in die Knie wenn ein Artikel mal populär wird, zudem ist im Normalbetrieb der statische Blog immer schneller als ein dynamisch generierter.

Das Blogsystem sollte aber nicht einfach ein statische Seiten auswerfender Generator sein. Denen fehlt zu viel was einen Blog ausmacht: Kommentare, Trackbacks/Pingbacks, auch das Backend mit seinen Moderatorfunktionen, dem Artikeleditor und der Mediendatenbank. Das sind nur ein paar der wichtigsten Funktionen, auf die ein perfektes System nicht verzichten würde. Dazu kommen beispielweise Dinge wie die Unterstützung mehrerer Nutzer, Veröffentlichungsworkflows, Rechteverwaltung und sicher noch viel mehr, was ich teilweise unten beschreibe.
Das perfekte Blogsystem wäre also zweigeteilt: Im Frontend würden statische Seiten generiert, aber parallel liefe ein dynamisches Backend, das Aufgaben wie das Entgegennehmen von Kommentaren übernimmt.
Stabilität, Erweiterbarkeit und Kompatibilität
Ein perfektes System wäre stabil. Damit meine ich inbesondere den Code und seine Sprache. PHP mit seinen fortwährenden Kompatiblitätsbrüchen ist beispielsweise eine besonders instabile Grundlage, die fortlaufend Entwicklungsarbeit verlangt. Das ist absurd für die Webumgebung, ist die doch grundsätzlich stabil: Selbst vor 30 Jahren erstellte HTML-Seiten können Browser von heute noch anzeigen. Es wäre also viel gewonnen, wenn das System um den Blog zu erstellen ebenfalls einmal gebaut werden könnte und dann gleichsam in 30 Jahren noch HTML/CSS und JS ausspuckt, dann zwar auf veraltetem Stand, der aber sicher noch verstanden werden würde.
Gleichzeitig sollte das System einfach erweiterbar sein. Was derzeit gute Blogsysteme auszeichnet ist ihr Pluginsystem und die Themebarkeit, sodass Entwickler mit wenig Aufwand das System anpassen können. Neue Logik hinzufügen und mit einem Theme die HTML-Ausgabe bzw das Design anpassen zu können, das ermöglicht die Anpassung an sich ändernde Zeiten ohne dauernd der Kern überarbeiten zu müssen.
Weil Blogs im Zweifel schon existieren bräuchte es im Sinne der Stabilität Importer. Die müssten Artikel so importieren können, dass ihre URL sich nicht ändert, wobei unter der alten URL Weiterleitungen auf eine neue sein könnten und Übersichtsseiten meiner Meinung nach nicht unbedingt erhalten bleiben müssen. Auch die Kommentare würden importiert. Bei der Frage wo die Daten dann landen bin ich zwiegespalten: Was ist perfekter, ein System das viele Datenbanken unterstützt oder eines, das sich auf SQLite konzentriert?
Umfassende Kompatibilität bedeutet auch die vollständige Unterstützung von Unicode. Wobei die Realität nunmal ist, dass alte Blogs in anderen Encodings geschrieben wurden. Ein perfekter Importer würde das konvertieren können.
Viele Standardfunktionen
In die großen Blogsysteme sind tausende Arbeitsstunden geflossen, in die meisten kleinen bestimmt immer noch hunderte. Entsprechend groß ist ihr Umfang. Schauen wir uns nur mal an was diesen Artikel hier von einem rohen handgeschriebenen HTML-Artikel unterscheidet.
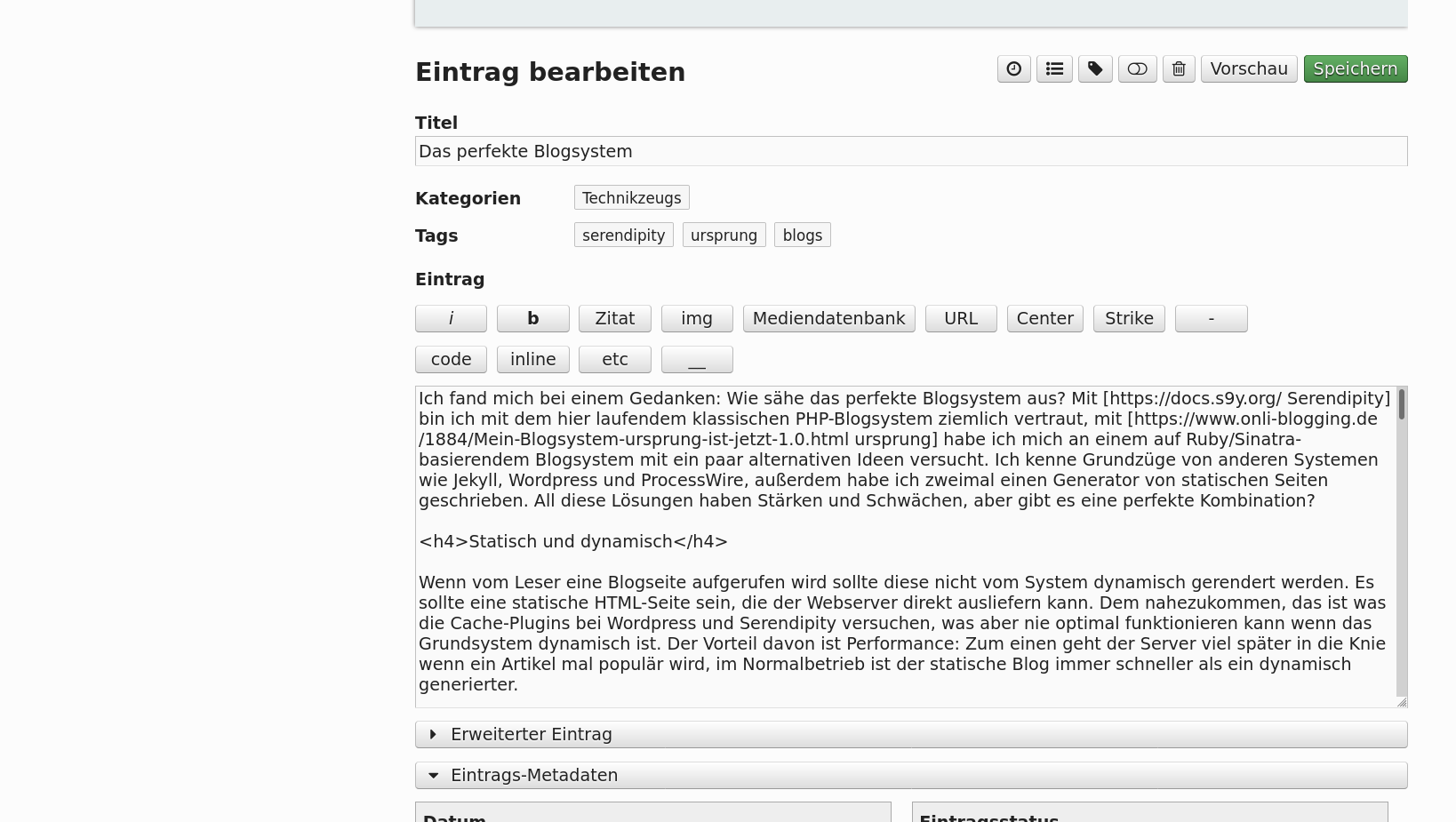
So ist er nicht einfach in HTML geschrieben, sondern ist der rohe Text eine Mischung aus HTML und einer individuellen Markupsprache. Mit ihr sind Links einfacher setzbar. Umbrüche brauchen dank den nl2p-Plugin keine HTML-Tags. Zum Formatieren des Textes kann ich HTML oder die Markupsprache schreiben, aber alternativ sind hier auch Buttons beim Editor die das übernehmen können. Andere Systeme (und Serendipity optional) haben eine WYSIWYG-Ansicht oder eine Autovorschau, sodass der rohe Text schon beim Schreiben umgewandelt wird. Serendipity mit meinen Einstellungen hat dafür immerhin eine verlässliche Vorschau per Buttonklick, sodass ich Layoutfehler sehen kann bevor ich Artikel veröffentliche.
Im <head> ist in der Artikelansicht eine Anweisung für Suchmaschinen den Artikel zu indexieren, auf Übersichtsseiten dagegen wird das indexieren verboten. Es sind Tags gesetzt um den Artikel auf Twitter etc hübscher zu machen wenn er verlinkt wird, dabei wird auch ein Vorschaubild gesetzt, falls ich diesem Text noch ein Bild aus der Bibliothek hinzufüge wird dieses dafür benutzt werden. Thema Bilder: Die sind responsiv, kleine Bildschirme bekommen so kleinere und sparen Bandbreite.
Beim Schreiben kann ich komfortabel Schlagwörter und Kategorien zuweisen. Ich könnte den Artikel als Entwurf speichern oder die Veröffentlichung auf einen Moment in der Zukunft festsetzen. Er könnte dann sogar passwortgeschützt werden. Veröffentliche ich ihn, werden automatisch Trackbacks ausgesendet, was ich im Backend aber auch abstellen kann.
Gibt es nachher Kommentare kümmern sich direkt drei Plugins mit verschiedenen Ansätzen darum Spam auszusondern. Die sind so gut, dass Spam nur selten durchkommt. Wenn doch bekomme ich eine Email, wie auch bei legitimen Kommentaren. So kann ich auf die schnell reagieren. Eingehende Kommentare werden in einer Thread-Ansicht dargestellt, sodass Kommentatoren einander antworten können. Und natürlich gibt es für die Kommentare einen RSS-Feed, wie auch für die Artikel selbst und alle Kategorien.
Würde ich den Artikel dagegen in ursprung schreiben wäre der Editor komfortabel im Frontend auf der Startseite, der Kontextwechsel in ein Backend unnötig. Auch das ist eine Qualität, die ein perfektes System abdecken oder trumpfen müsste.
Und so ginge das jetzt sicher noch eine Weile weiter wenn ich alles aufzählen wollte. Man sieht schnell wie breit dieses Feld ist, wie viel ein neues System unterstützen müsste um auch nur gleichwertig zu sein.
Konkurrenz und Entwickler
Es gibt ziemlich viele Blogengines und CMS. So viele, dass es unmöglich ist einen Überblick zu behalten. Gleichzeitig gibt es mit Wordpress einen absoluten Gewinner, mit dem das halbe Internet läuft. Tatsächlich sehe ich das als Faktor: Ein perfektes System würde in einer Umgebung existieren in der es sichtbar werden kann, sodass seine Existenzberechtigung auch klar wird. So erwarte ich fast, dass ein Kommentator mir ein System benennen wird was den oben beschriebenen Ansatz teilt.
Und klar: Ein perfektes Blogsystem würde von einem aktiven Team netter und fähiger Entwickler geschrieben. Es wäre so perfekt, dass ich es nicht schreiben müsste (und auch nicht könnte). FOSS wäre es selbstverständlich auch. Sein Code wäre minimal, hätte keine instabilen Abhängigkeiten und wäre hervorragend lesbar.
Fazit
Wie seht ihr das, was habe ich vergessen? Ist was ich oben beschreibe überhaupt perfekt oder hätte sogar das beschriebene schon Macken?
Natürlich juckt es mich in den Fingern mich an einem solchen System zu versuchen. Dabei wäre das Ergebnis unzweifelhaft nicht perfekt – viele der Details wie die richtige Unterstützung der Markupsprachen und ob man das Markup oder das HTML speichert haben nicht die eine richtige Lösung – und einige der Anforderungen oben wie die Importer sind eine fast umstemmbare Mammutaufgabe, aber die Grundidee des statischen Frontends und dynamischen Backends umzusetzen hätte was. Sie hat generell derzeit etwas Aufwind, so geht Jamstack in die gleiche Richtung, ich sah in dem Kontext nur noch keine Umsetzung eines vollständigen Blogsystems.
Aber selbst wenn ich alle meine anderen Projekte zur Seite legen und mich der perfekten Blogengine widmen wollte: Scheiterte es nicht schon an der Sprachwahl? PHP wäre hier wegen seiner Instabilität offensichtlich Unsinn, wobei sein riesiger Vorteil der Hosterunterstützung damit wegfällt und schon deswegen eine Lösung ohne PHP kaum perfekt sein kann. Ich liebe Ruby, aber auch diese Sprache liefert nicht die Stabilitätsgarantien die das Projekt bräuchte. Ob Python da besser wäre erscheint nach dem Sprung auf Python 3 unwahrscheinlich. Vielleicht bräuchte es statischere Sprachen wie Rust, C oder Golang, aber komfortabel für Webanwendungen sind die nicht – und bei ihnen stolpere ich immer wieder über Projekte, die sich auf meinem System nicht kompilieren lassen. Stabilitätsgarantien in meinem Sinne gibt es da also nicht.
Was bleibt da? Etwas Lispiges wie Erlang, Common Lisp oder Racket? Etwas altgedientes wie TCL oder Perl? Eine Nischenlösung wie D?
Da erscheint direkt der erste Schritt zu schwierig.
Man nehme trotzdem den Gedanken mit, dass unsere Blogsysteme ziemlich gut, bessere Lösungen aber vorstellbar sind.
Serendipity 2.4-beta1 bringt Kompatibilität mit PHP 8.0
Monday, 13. September 2021
Serendipity hat gestern eine neue Version bekommen: Die 2.4-beta1, die jetzt auch hier in meinem Blog läuft.
Die Hauptänderung: PHP 8.0 wird sauber unterstützt
Wer hier mitgelesen hat kennt die Hauptmotivation hinter dem neuen Release: PHP 8.0 kam raus, brachte viele Änderungen und forderte damit auch viele Änderung vom alten Serendipity-Quellcode. Nicht alles davon Sisyphusarbeit, weil die Änderungen bei den Warnungen auch ein paar Bugs entlarvten, doch vieles war unnötiges Gedrängsel wo sich die Sprache künstlich dumm stellt – aber gut, jetzt ist es halt erledigt. Der PR von surrim gibt glaube ich einen besonders guten Eindruck davon, was für diese Kompatibilität erledigt werden musste.
Man beachte den PHP8-Upgrade-Guide falls mit dieser Serendipity-Version die Gelegenheit zum Upgrade auf PHP 8 genutzt wird.
Wer eigene Erweiterungen an Serendipity vorgenommen oder eigene Plugins laufen hat sei etwas beruhigt: Man sollte die zwar gut testen, aber Serendipity verschweigt jetzt auch in der Beta einfache Warnungen, was alten Plugins und Themes zugute kommt. Wohlgemerkt: Im Kern sind alle Warnungsquellen repariert worden, beim schweigsameren Warnungsverhalten geht es um Kompatibilität mit PHP 8 für alten Code der nicht vom Projekt kommt. Wobei das manche Plugins und alte Themes auf Spartacus einbezieht, denn auch dort gibt es welche ohne Maintainer.
Diese Änderung des Warnungslevels geht zusammen mit dem Beheben einiger Bugs bei der internen Fehlermeldungsfunktion, wodurch die erst jetzt so funktioniert wie sie einmal gedacht war. Das betrifft allerdings vor allem Entwickler, die Alpha-Versionen benutzen.
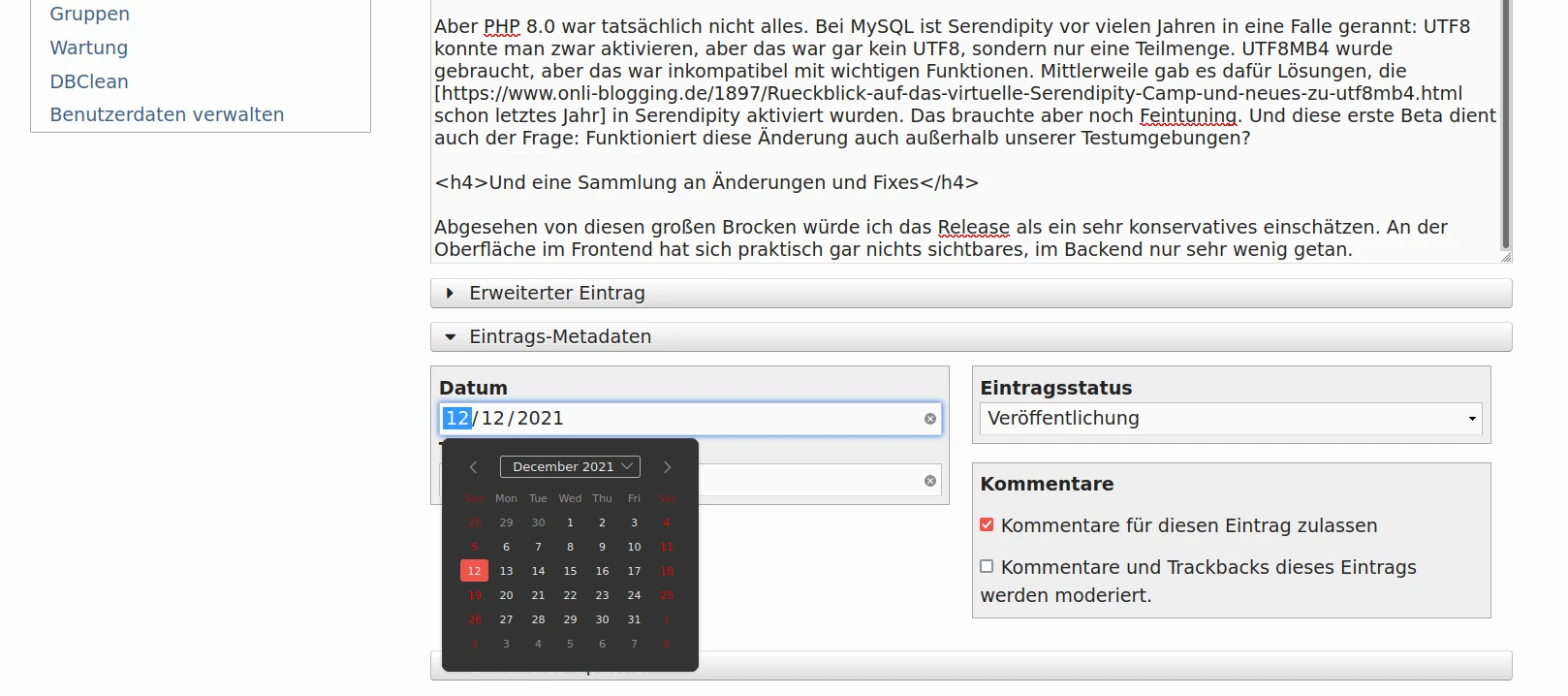
Dazu: UTF8MB4
Aber PHP 8.0 war tatsächlich nicht die einzige große Änderung. Bei MySQL ist Serendipity vor vielen Jahren in eine Falle gerannt: UTF8 konnte man zwar aktivieren, aber das war gar kein UTF8, sondern nur eine Teilmenge. UTF8MB4 wurde gebraucht, aber das war inkompatibel mit wichtigen Funktionen. Mittlerweile gibt es dafür Lösungen, die schon letztes Jahr in Serendipity aktiviert wurden. Sie brauchten noch Feintuning. Diese erste Beta dient auch der Frage: Funktionieren diese Änderung auch außerhalb unserer Testumgebungen?
Bei Neuinstallationen ist es einfach: Da wird einfach die neue Datenbank mit dem richtigen Zeichensatz angelegt, wenn die Datenbankengine neu genug ist. Upgrades sind das schwierigere Thema. Die Intention des Codes ist, die gleiche Prüfung zu machen und wenn dann schon UTF8 sowieso an ist, dann den Zeichensatz zu wechseln, was in Tests funktionierte. Im Idealfall ist das unsichtbar und danach können einfach mehr Zeichen gespeichert werden, wie Emojis.
Und eine Sammlung an Änderungen und Fixes
Abgesehen von diesen großen Brocken würde ich das Release als ein konservatives einschätzen. An der Oberfläche im Frontend hat sich praktisch gar nichts sichtbares, im Backend nur wenig sichtbares getan. Aber nicht nichts, und hinter den Kulissen noch etwas mehr.
Im Eintragseditor ist das Datumsfeld nun aufgeteilt, weil Browser mit einem Widget für datetime nach jetzt zu vielen Jahren Wartezeit immer noch nicht angekommen sind. Jetzt gibt es eben ein Eingabefeld fürs Datum und eins für die Zeit, was Browser dann doch unterstützen. So sieht es bei mir im Firefox aus:
Ähnliche Verbesserungen betreffen den Umgang mit Bildern. Die responsiven Bilderfunktion sollte etwas geschickter Thumbnails wählen, sodass kleine Bilder nicht so leicht unscharf werden. Und die Mediendatenbank hat einen Bug behoben bekommen, bei der nach dem Upload von Bildern vom Editor aus ein anschließendes Ordnerwechseln zur Standardmediendatenbank führte, von wo der Upload nicht durchzuführen war. Der Bug hat mich hier persönlich im Blog lange genervt. Nette neue Bonusfunktion: Beim Einbinden neuer Bilder in Einträgen wird das Attribut loading="lazy" gesetzt, wodurch sie nicht sofort Laden, sondern erst wenn weiteres Scrollen sie bald sichtbar machen würde. Das sollte vielen Blogs einen netten Performanceboost in der Praxis bringen, gerade ihren Startseiten.
Natürlich, wie bei jedem neuen Release, gab es Updates der gebündelten Libraries. Dort hab ich etwas Chaos aufgeräumt, das ich mit einer umständlichen composer-Einbindung angerichtet hatte. Die Updates betreffen auch den CKEditor. Bei dem wurden zum einen ein paar alte Zöpfe abgeschnitten, sodass seine Konfigurierbarkeit sehr viel beherrschbarer sein sollte. Außerdem wurde die Standardkonfiguration angepasst (nach Rückmeldung im Forum), sie sollte jetzt ein paar typische Probleme im WYSIWYG-Modus umschiffen.
Es gab relativ tiefgreifende Fixes für die Multisprachunterstützung, die der Performance dienen sollten und auch Fehler in dieser Funktion beheben (von stephanbrunker). Die Tokengenerierung für die Aktionen bei den Emails ist jetzt sicherer (von hannob). Der Installer prüft jetzt, ob das benötigte XML-Modul vorhanden ist (von UweKrause). Und die Liste ginge noch deutlich weiter, wenn ich jetzt weiter durch die Commits gehen würde.
Ich hoffe, die neue Version gefällt den Serendipity-Bloggern. Mir liegt diese Version sehr am Herzen – zum einen, weil sie angesichts des sich langsam nähernden Endes von PHP 7 (7.4 bekommt reguläre Updates bis November 2021, Sicherheitsupdates bis November 2022) notwendig war, aber auch weil die Arbeit am Code meiner Wahrnehmung nach diesem sehr geholfen hat. Es tat gut, das lange schwelende MySQL-Zeichensatzproblem anzugehen, und auch einige alte Zöpfe im Code abzuschneiden. Und gefühlt war ich seit 2.0 mit der Smartymigration des Backends nicht mehr so involviert, davor sowieso nicht.
Bis alle Plugins mit PHP 8.0 kompatibel sind steht noch etwas Arbeit an, aber damit das in einem guten Tempo im Ganzen gelingt braucht es Hilfe, kurz: Mehr aktive Entwicklung. Serendipity ist einfach insgesamt ein ziemlich großes System. Auch bei den alten Themes könnte man viel machen und mit PHP 8.1 steht im Kern dann die nächste Migration an. Das schafft Modernisierungsdruck, aber auch -potential. Für neue Entwickler wäre Serendipity gerade und in naher Zukunft ein ziemlich spannendes Projekt, da kann ich nur einladen.
YouTube-Videos einbinden, ohne dass die Seite lahm wird (+Serendipity-Plugin)
Friday, 4. June 2021
Wenn mehrere YouTube-Videos auf einer Seite landen wird diese ziemlich schwer. Zumindest, wenn man den Einbindungscode nutzt den YouTube selbst vorschlägt. Da das hier im Blog schnell mal passiert, so wie jetzt, da mehrere Artikel mit Videos auf der Hauptseite sind, habe ich mich nach Alternativen umgesehen.
Normalerweise sieht das Iframe so aus:
<iframe width="560" height="315" src="https://www.youtube.com/embed/XhG-4zdVx0I" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
Auf den ersten Blick harmlos. Das Problem ist all das Javascript, das in diesem Iframe dann bezogen wird. Was sofort geschieht, da nach dem Laden die Iframe-Zielseite sofort den Player initialisiert.
Auf dev.to schlug Arthur vor, stattdessen ein alternatives Iframe zu nutzen:
<iframe
width="560"
height="315"
src="https://www.youtube.com/embed/XhG-4zdVx0I"
srcdoc="<style>*{padding:0;margin:0;overflow:hidden}html,body{height:100%}img,span{position:absolute;width:100%;top:0;bottom:0;margin:auto}span{height:1.5em;text-align:center;font:48px/1.5 sans-serif;color:white;text-shadow:0 0 0.5em black}</style><a href=https://www.youtube.com/embed/XhG-4zdVx0I ?autoplay=1><img src=https://img.youtube.com/vi/XhG-4zdVx0I/hqdefault.jpg><span>▶</span></a>"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen
></iframe>
Das ist schon von mir leicht verändert und der Artikel beschreibt verschiedene Zwischenschritte auf dem Weg zu dieser Lösung. Schaut euch das ruhig im Originalartikel an.
Aber die Kernidee ist, dass in dem Iframe der Videoplayer erst nach einem Klick auf das Vorschaubild geladen werden wird. Statt einem halben MB an Code ein kleines Bildchen zu laden geht beim ersten Laden der Seite wesentlich schneller. Und da das Video nach einem Klick wie zuvor sofort startet, dank dem autoplay=1, wird dem Seitenbesucher der Unterschied kaum auffallen. Denn das ist das Ergebnis:
Einfluss auf die Seitenperformance
Ich stolperte über diese Baustelle, als ich die neue Version Googles Pagespeed testete. Beim Prüfen dieses Blogs hier erschrak ich über das miserable Ergebnis:

Gut, die Mobilvariante des Tools ist häufig sehr hart, aber so schlecht hatte ich meinen Blog nicht gesehen. Ein Blick auf die Problemliste zeigte dann deutlich, dass Youtube-Videos die Ursache sind:
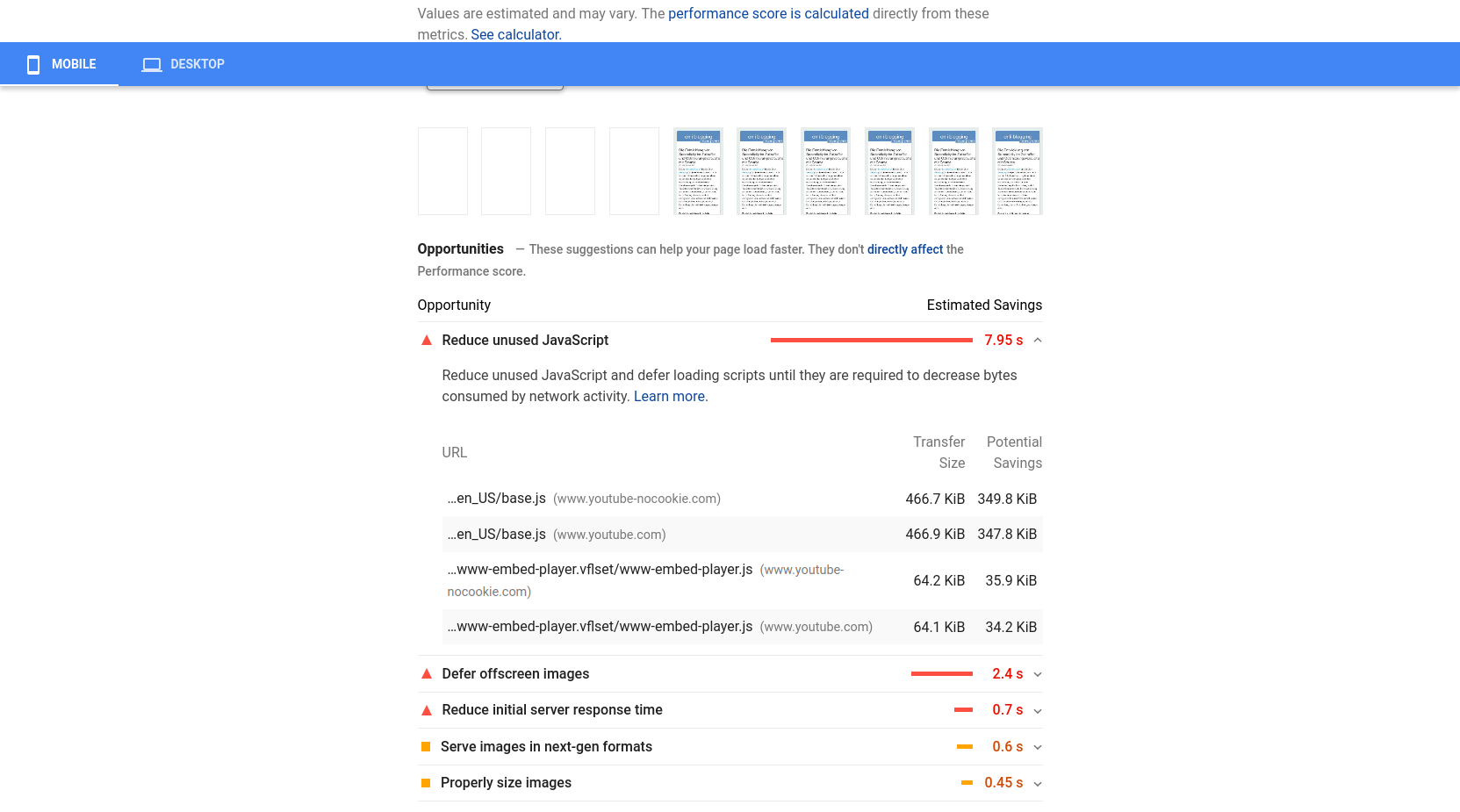
Was schlicht daran liegt, dass derzeit mehrere Artikel mit Videos von Youtube hier auf der Startseite sind.
So sieht das Ergebnis jetzt aus, da alle diese Videos mit den neuen Iframes ersetzt sind:

Viel besser! Sogar für Telefone wird die Geschwindigkeit der Seite als hervorragend bewertet. Wie es bei einem einfachen Blog ja auch sein soll.
Serendipity-Plugin
Ich wollte die regulären Iframes nicht per Hand ersetzen. Und generell wollte ich den originalen Code beibehalten. Ich gehe davon aus, dass die Kompatibilität mit dem derzeitigen Einbindungscode fast für ewig erhalten bleiben wird. Während bei dem angepassten Iframe Annahmen drin sind die sich ändern könnten, vor allem der Pfad zum Vorschaubild.
Deswegen habe ich ein Plugin geschrieben, das die normalen Iframes umwandelt. Der Blogger schreibt also ganz normal seinen Artikel, bezieht den normalen Einbettungscode von Youtube, und das Plugin serendipity_event_lazyoutube wandelt dann automatisch diesen Code von Youtubes lahmen Standard-Iframe zu der hier gezeigten schnellen Alternative um, die den Videoplayer erst nach einem Klick auf das Vorschaubild lädt.
Außerdem kann man damit, angelehnt an oEmbeds, den Einbettungscode vom Plugin erstellen lassen – falls einem das Bewahren des Original-Iframes im Artikelquellcode nicht so wichtig ist. Statt dafür nur einen Link zu setzen geht das mit [Youtube-Link], also [https://www.youtube.com/watch?v=XhG-4zdVx0I] für das Video von oben.
Nur damit der zu erstellende Code einfacher zu erzeugen ist habe ich oben auch das Iframe angepasst. Im Original ist da noch an zwei Stellen der Titel des Videos drin. Aber um den abzufragen müssen wir mit der Youtube-API arbeiten oder den Artikelschreiber das eintragen lassen, beides wollte ich vermeiden.
Das Plugin ist ganz frisch und es fehlt mindestens noch der Versuch, gewählte Anfangszeiten zu unterstützen. Deshalb liegt es bisher nur in einem eigenen Github-Repo. Hier im Blog ist es aber schon aktiv und Tester wären mir hochwillkommen.
Die Entwicklung von Serendipity im Zeitraffer und Optimierungsversuche mit Gource
Wednesday, 2. June 2021
Drüben bei gnulinux.ch bin ich über Gource gestolpert. Gource braucht man nur ein Git-Repository zu geben, damit es aus der der dort gespeicherten Aufzeichung ein Video mit einer Visualisierung der Entwicklung erstellt. Tatsächlich kannte ich die Visualisierung aus einem Youtubevideo, aber ich hatte keine Ahnung, dass sie mit frei verfügbarer Linxusoftware erstellt wurde. Und mir gefiel die Konfiguration der Darstellung, die im Artikel vorgeschlagen wird.
Das ist die nicht ganz komplette Entwicklung von Serendipity:
Ich finde es toll zu sehen, wie viele Entwickler da am Wirken waren und wie Garvin von der Software ins Zentrum gestellt wird. Und natürlich bereitet es ganz besonders Freude, wenn der eigene Name auftaucht und den Dateibaum verändern beginnt.
So ein Video zu erstellen ist einfach. Gource war auch bei Void Linux in den Quellen. Einmal installiert, muss nur das Git-Verzeichnis erstellt, darein gewechselt, Gource gestartet und die Ausgabe an FFmpeg übergeben werden:
git clone git@github.com:s9y/Serendipity.git Serendipity.git cd Serendipity.git gource -1280x720 --date-format %Y-%m-%d --seconds-per-day 0.025 --auto-skip-seconds 0.05 --no-time-travel --stop-at-end --highlight-users --max-user-speed 125 -r 30 -o - | ffmpeg -y -r 30 -f image2pipe -vcodec ppm -i - -vcodec libx264 -preset medium -pix_fmt yuv420p -crf 18 gource.mp4
Tatsächlich habe ich aber viel Zeit in den Versuch versenkt, das zu optimieren. Ich wollte FFmpeg statt .mp4 erst .ogv und dann .webm mit VP9 erstellen lassen. Denn das mit H.264 gebaute und oben eingebundene .mp4 ist immerhin 77 MB groß.
Übrigens das erste mal seit langer Zeit, dass ich mir einen stärkeren Prozessor gewünscht habe. Videos zu enkodieren ist einfach heftig. Aber auch beeindruckend, dass die 4GB große .ppm problemlos auf unter 100MB gebracht werden kann.
Beim Versuch, eine kleinere Datei als die obige für diesen Artikel zu erhalten, orientierte ich mich an der Dokumentation von FFmpeg und den Hinweisen von Google. Aber die Videos waren entweder größer oder mit mehr sichtbaren Kompressionsartefakten. Und das selbst bei der Two-Pass-Enkodierung, die ich so versuchte:
gource -1280x720 --date-format %Y-%m-%d --seconds-per-day 0.025 --auto-skip-seconds 0.05 --no-time-travel --stop-at-end --highlight-users --max-user-speed 125 -r 30 -o gource.ppm ffmpeg -y -r 60 -f image2pipe -vcodec ppm -i gource.ppm -c:v libvpx-vp9 -b:v 0 -crf 37 -pass 1 -row-mt 1 -an gourceq37.webm ffmpeg -y -r 60 -f image2pipe -vcodec ppm -i gource.ppm -c:v libvpx-vp9 -b:v 0 -crf 37 -pass 2 -row-mt 1 -an gourceq37.webm
Das produzierte relativ große Dateien (hier 130MB), während die Google-Vorgaben sehr kleine (22MB), aber deutlich sichtbar komprimierte Videos erstellten:
ffmpeg -y -r 60 -f image2pipe -vcodec ppm -i gource.ppm -vf scale=1280x720 -b:v 1800k -minrate 900k -maxrate 2610k -tile-columns 2 -g 240 -threads 4 -quality good -crf 32 -c:v libvpx-vp9 -an -pass 2 -speed 4-y gource_google.webm ffmpeg -y -r 60 -f image2pipe -vcodec ppm -i gource.ppm -vf scale=1280x720 -b:v 1800k -minrate 900k -maxrate 2610k -tile-columns 2 -g 240 -threads 4 -quality good -crf 32 -c:v libvpx-vp9 -an -pass 2 -speed 4 gource_google.webm
Kein guter Startpunkt.
Die Single-Pass-Kodierung ist laut der Dokumentation nicht empfohlen, und tatsächlich lässt sich mit ihr zwar etwa die gleiche Größe erreichen:
gource -1280x720 --date-format %Y-%m-%d --seconds-per-day 0.025 --auto-skip-seconds 0.05 --no-time-travel --stop-at-end --highlight-users --max-user-speed 125 -r 30 -o - | ffmpeg -y -r 30 -f image2pipe -vcodec ppm -i - -vcodec libvpx-vp9 -preset medium -pix_fmt yuv420p -crf 30 -row-mt 1 gource.webm
Aber das Video sieht ein bisschen schlechter aus. Und mit schlechterer Qualitätsstufe (hier 35) leidet die Darstellung dann deutlich:
Wenn ich mir die Dateigrößen und die Qualität von ja oft deutlich längeren Youtube-Videos anschaue glaube ich, dass das besser gehen müsste.
Kommt VP9 generell schlecht mit dem Blur zurecht? Oder ist der Kodierer in FFmpeg subobtimal? Gibt es doch einen Weg, die Komprimierung des .mp4-Video bei visuell gleicher Qualität zu schlagen?
Trackbacks für Serendipity mit PHP 8
Wednesday, 26. May 2021
Kleine Wasserstandsmeldung aus gegebenem Anlass.
Die Arbeit, um Serendipity mit PHP 8 kompatibel zu machen, ist noch nicht fertig. Aber sie ist weit vorangeschritten. Ich habe mittlerweile alle Backend- und Frontendfunktionen getestet und fast alle mit Standardtheme und vorinstallierten Plugins zum Laufen gebracht.

Ein wichtiger noch fehlender Baustein waren die Trackbacks. Die Kommentare bei Dirks Bloggeburtstag waren sicher der Anlass sie jetzt zu testen, auch wenn mir das gestern Abend gar nicht bewusst war. Es war eine Erinnerung, deretwegen ich den Test vorzog, an die ich in dem Moment nicht mehr direkt dachte. Ihr kennt das bestimmt.
Tatsächlich waren die Trackbacks kaputt. Die Korrekturen sind größtenteils Kleinigkeiten. Auf einem Server, der Warnungen verschluckt, würde wahrscheinlich auch jetzt schon alles laufen. Aber die Warnungen zu reparieren kann der Codequalität nur dienen und Warnungen werden eben nicht immer ausgeblendet, was dann Funktionen kaputtmachen kann.
Bei den Trackbacks speziell ist, dass der Browser ja gar keine Daten sendet. Das machen die Server unter sich aus, was im Zweifel schwer zu beobachten ist. Wir haben Logs, aber die zeigen bei PHP-Fehlern nur wo der Empfang abbricht. Um das richtig zu debuggen sendete ich den Trackback stattdessen mit curl:
curl -X POST -d 'type=trackback&entry_id=16&url=https://example.com/s9y_dev/index.php?/archives/19-trackbacktest-2.html&title=trackbacktest 2&blog_name=John Doe personal blog&excerpt=link2' https://example.com/s9y_dev/comment.php
So waren die Fehler schnell sichtbar und relativ einfach zu reparieren.
Es fehlt, das gleiche mit Pingbacks (ggf. via Wordpress) zu testen. Ansonsten müssten noch die restlichen Plugins und Themes durchgegangen werden. Ich habe mir vorgenommen, die mitgelieferten Plugins, die populären in Spartacus und die modernen Themes tatsächlich noch selbst anzusehen. Damit müsste eine PHP-8-kompatible Beta dann in Reichweite sein, wobei gerade die Plugins selbst bei Beschränkung auf die populäreren noch ein ziemlicher Brocken sein könnten.
Ein Printstylesheet für den Blog
Tuesday, 4. May 2021
Dieser Blog hat neues CSS für die Druckdarstellung bekommen. Der Artikel zur Witcherserie als Beispiel sieht im Web so aus:

Ausgedruckt – bzw mittels der Druckfunktion zum PDF umgewandelt – und dabei auf ein Blatt herunterskaliert kommt das dabei raus:

Erreicht wird die angepasste Darstellung durch dieses CSS, das ich einfach der regulären CSS-Datei hinzugefügt habe:
@media print {
#serendipitySideBarContainer {
display: none;
}
#content {
width: 100%;
}
#serendipityCommentFormC {
display: none;
}
.shariff {
display: none;
}
.dsgvo_gdpr_footer {
display: none;
}
#siteNav {
display: none;
}
body {
font-family: Iowan Old Style, Apple Garamond, Baskerville, Droid Serif, Times, Source Serif Pro, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol, Times New Roman, serif;
border: none;
}
html {
background-color: white;
}
.serendipity_entry_body {
column-width: 17em;
column-gap: 3em;
}
.serendipity_entry_body a[href*='//']::after, serendipity_commentBody a[href*='//']::after {
content: " (" attr(href) ")";
}
a {
color: black !important;
text-decoration: underline !important;
}
#serendipity_banner {
display: none;
}
#mainpane::before {
content: "onli-blogging";
display: block;
}
.serendipity_title a {
text-decoration: none !important;
}
.serendipity_title, .serendipity_date {
break-after: avoid;
break-after: avoid-page;
}
br + .serendipity_commentsTitle, .nocomments {
display: none;
}
.serendipity_entryFooter, .serendipity_comment footer {
display: none;
}
}
Wer das in seinen eigenen Serendipity-Blog übernehmen will müsste manche der Klassen wahrscheinlich anpassen, denn mein Design basiert mit codeschmiede auf älteren Code, den ich selbst nach HTML5 umgewandelt habe. Deswegen gibt es ein paar Unterschiede bei den Klassennamen zu 2k11 und anderen modernen Themes. Aber die Grundideen sind:
Ausgeblendete Seitenleiste und andere Elemente
Wer einen Artikel ausdrucken will kann auf dem Papier mit den Links in der Seitenleiste nichts anfangen, daher konnte die weg. Dazu habe ich den Header, der bei Einzelartikeln nur den Artikeltitel doppelte, den Footer des Blogs, die Artikelunterzeile und das Kommentarformular ausgeblendet.
Links ohne Farbe
Links sind hier im Blog normalerweise farblich markiert. In der Druckversion sind sie stattdessen schwarz, aber unterstrichen, und ihnen folgt das Linkziel als Text.
Serif-Schriftart
Für das richtige Papierdesign. Übernommen vom systemfontstack – es war gar nicht so einfach, passende Systemschriftarten für Serif- statt Sans-Serif-Schriftarten zu finden – aber leicht angepasst, denn Times New Roman war mir zu prominent platziert.
Spaltenansicht
Der Artikel wird wenn Platz ist in Spalten aufgeteilt. Auf dem Bild oben sind mehr Spalten als normal, da die Skalierung auf 60% reduziert war. Normalerweise sind es bei Din-A4 zwei Spalten im Querformat und nur eine, wie am Monitor, im Hochformat. Die Idee habe ich von sitepoint übernommen.
Titel hinzugefügt
Damit der Blogname trotz ausgeblendetem Header wenigstens irgendwo auftaucht wird er als Pseudoelement vor den Artikel gepackt.
Ganz bewusst nicht ausgeblendet sind die Kommentare, denn die könnten ja zum Artikel beitragen bzw das sein, was jemand ausdrucken wollte. Und auch das Videoelement ist absichtlich noch da, denn ohne es würde dieser Abschnitt des Artikel fehlerhaft wirken. Man kann es zwar nicht anklicken, aber sieht so zumindest dass es da war.
Insgesamt ging es also darum die Artikel auf dem Papier lesbarer zu machen, interaktive Elemente möglichst zu entfernen und auch die angezeigten Farben auf ein Minimum zu reduzieren. Damit wenn schon etwas ausgedruckt wird, es möglichst sparsam geschieht und das Ergebnis so lesbar wie möglich ist.
Reviews im Blog per Plugin mit Schema.org auszeichnen
Thursday, 22. April 2021
Das im letzten Jahr hier vorgestellte Schema.org-Plugin setzt automatisch Markup, um Blogartikel als Blogartikel zu beschreiben. Das ist zwar nett, aber der Nutzen ist beschränkt – so hat Google diese Auszeichnung bisher nicht aufgegriffen.
Was mir aber im pc-kombo-Blog wahrscheinlich einige Besucher beschert hat war das Markup für Reviews. Das ist eigentlich logisch: Was soll es auch viel helfen wenn die Suchmaschine sich sicherer ist, dass die Blogartikel hier Blogartikel sind. Wovon sie handeln und was sie aussagen, das sind die verwertbaren Informationen um den Artikel im richtigen Moment besser dargestellt anzuzeigen.
Ich habe damals mit recht simplem JSON-Markup gearbeitet und das manuell in die Artikel eingebaut. Jetzt habe ich das Schema.org-Plugin erweitert, um das gleiche Markup in Serendipity-Blogs halbautomatisch zu erstellen. Zum Beispiel sieht der vom Plugin generierte JSON-Code in meinem Artikel zum Sharkoon-DAC so aus:
{"@context": "http://schema.org",
"@type": "Product",
"name": "Sharkoon DAC Pro S V2",
"image": ,
"description": "",
"brand": {
"@type": "Thing",
"name": "Sharkoon"
},
"review": {
"@type": "Review",
"author": {
"@type": "Person",
"name": "onli"
},
"datePublished": "2021-04-02T06:34:00+0000",
"reviewRating": {
"@type": "Rating",
"ratingValue": "4.0"
}
}
}
Der Code ist teilweise automatisch generiert, der Rest muss manuell über die freien Felder des Entrypropertyplugins eingegeben werden.
Dafür erstellt man vier freie Felder in dessen Pluginkonfiguration:
schemaType, schemaName, schemaBrandName, schemaRating
Die ersten drei beschreiben das Thema des Artikels. Hier war schemaType ein Product, schemaName der Name des DAC, und schemaBrandName der Name des Herstellers. Wäre ein Film das Thema gewesen hätte ich Product mit Movie ausgewechselt – Googles Dokumentation beschreibt das als gültigen Wert, andererseits hat der Markuptester bei mir mit vielen der dort angegebenen Werten nichts anfangen können, auch wenn er nicht meckerte.
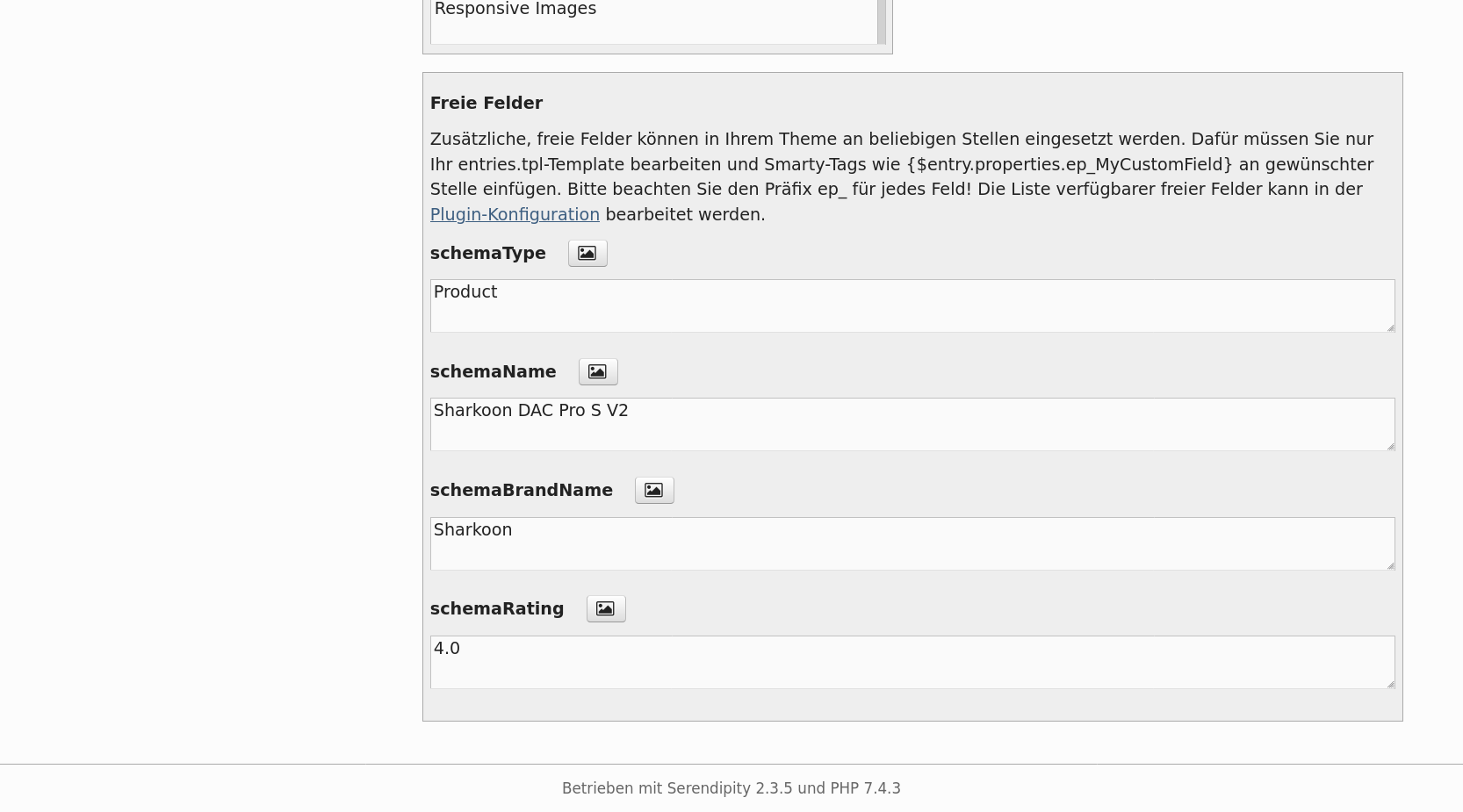
Das vierte Feld schemaRating ist schließlich die Bewertung. Da ich keine Skala angeben möchte geht die von 0 bis 5. Eine numerische Bewertung angeben zu müssen ist manchmal blöd, da meine Artikel normalerweise keine finale Bewertung abgeben. Aber für das Snippet wird sie verständlicherweise gebraucht.
Der Schema.org-Reviewcode wird nur ausgegeben, wenn alle vier Felder gefüllt sind. Er ist ein Zusatz zum regulären Blogartikelbeschreibungscode, den das Plugin bisher ausgegeben hat. Der bleibt unverändert erhalten.
Das Plugin ist nicht auf Spartacus, aber kann von seinem Github-Repo heruntergeladen werden. In dessen Readme ist auch die Konfiguration nochmal erklärt.
Zur Zukunft von Serendipity mit PHP 8.0
Tuesday, 16. March 2021
Uberspace hat PHP 8.0 aktivierbar gemacht. Da dort meine Entwicklungsinstallation lebt habe ich mir angeschaut, was da genau auf die Blogsoftware zukommt. PHP 8.0 ist zwar schon draußen, PHP 7.4 wird aber noch eine ganze Weile unterstützt, es eilt also nicht. Andererseits gibt es viel zu tun. Zumindest ist das meine Einschätzung.
Die inkompatiblen Änderungen von PHP 8.0
PHP 8.0 ist inkompatibel mit einigem Code, der in den letzten 20 Jahren bei Serendipity zusammengekommen ist. Vor allem diese Änderungen (von hier) machen der Software zu schaffen:
A number of notices have been converted into warnings:
Attempting to read an undefined variable.
…
Attempting to read an undefined array key.
…
Serendipity macht beides sehr, sehr oft. Und noch öfter, wenn man die Smarty-Templates hinzurechnet, die nun ebenfalls bei Zugriff auf undeklarierte Variablen solche Warnungen werfen. Werden Warnungen geworfen ist das im Zweifel im Blog sichtbar, kann generiertes HTML und CSS kaputtgehen, bei Entwicklungsversionen bricht die Ausführung ab.

Der Code schaut zum Beispiel oft, ob in $serendipity ein gesuchter Key gesetzt ist, oder switcht sogar über diesen Wert:
switch($serendipity['POST']['adminAction']) {
…
}
Wenn $serendipity['POST']['adminAction'] nie gesetzt wurde, wirft das jetzt eine Warnung. Vorher war das Ergebnis einer solchen Abfrage einfach null und machte entsprechend nichts. Wir können das reparieren, mit isset oder dem ??-Operator:
switch($serendipity['POST']['adminAction'] ?? '') {
…
}
Aber will man die Warnungen nicht verstecken muss das eben durch den gesamten Code hindurch gemacht werden.
Der aktuelle Stand
Warnungen zu unterdrücken halte ich wirklich für keine gute Option. Tatsächlich wurden durch dieses neue Verhalten jetzt schon einige Bugs sichtbar, als ich die Warnungen nachverfolgend durch den Code ging. Es ist zwar unangenehm bei altem Code wie diesem – tatsächlich ist Serendipity kein toller Kandidat für die Portierung auf PHP 8 – aber die Änderungen sind grundsätzlich gut. Serendipity sollte da mitgehen.
Ich habe einen ersten Pull-Request vorbereitet. Den will ich so nicht mergen, er ist zu groß geworden, aber ich werde ihn aufsplitten (der erste Folge-PR ist hier). Mit diesen Codeänderungen kann der Blog mit Standardplugins schon wieder fehlerlos dargestellt werden, auch alle Hauptseiten im Backend werfen keine Fehler mehr. Mit etwas mehr Arbeit wird wahrscheinlich bald der Rest des Kerns wieder gehen.
Anstehende Entwicklungen und Entscheidungen
Es würde wohl in ein Serendipity 3.0 münden. Die von PHP 8.0 diktierten Änderungen werden s9y teilweise zu inkompatiblen Änderungen zwingen. Zum Beispiel bei der Redeklarierung von Konstanten, was nun ebenfalls einen Fehler wirft, aber für das Fallback bei den Sprachdateien genutzt wird.
Aber ich könnte mich täuschen. Vielleicht lassen sich solche Änderungen durch Ideen anderer Entwickler vermeiden. Vielleicht sollte man temporär an dieser Stelle doch die Fehlermeldungen unterdrücken, wo wir da doch wirklich wissen, dass davon kein Bug versteckt wird. s9y versucht ja auch sonst immer, inkompatible Änderungen zu vermeiden. Ich hoffe, die jeweilige Änderung in den PRs mit den anderen zu besprechen.
Dann bleiben aber immer noch die alten Themes und Plugins.
Bei den Themes ist es möglich, dass die genutzte Template-Engine Smarty eine neue Version herausbringt, die besser auf PHP 8.0 ausgerichtet ist und die Warnungen bei undeklarierten Variablen vermeidet. Wenn nicht, werde ich die empfohlenen Designs reparieren (und natürlich auch dieses hier im Blog genutzte), wäre dann aber sehr dafür die alten Themes ohne eigenen Maintainer aufzugeben.
Bei den Plugins ist die Situation ähnlich. Auch die werden wahrscheinlich fast alle repariert werden müssen. Die wichtigsten werde ich bei meiner Arbeit an Serendipity selbst mitreparieren, wenn mir niemand zuvorkommt. Man könnte es beim Rest mit automatisierten Tools wie rector versuchen. Und nachbessern falls Nutzer Probleme melden. Dabei sollten wir aber die Plugins markieren, die bereits repariert sind, damit ein etwaig unbedarfter Nutzer nicht unwissentlich ein eventuell inkompatibles Plugin installiert.
Wie gesagt, das ist nur meine unabgesprochene Einschätzung. Durchaus möglich, dass ich gute Alternativen übersehe und mein Ansatz arbeitsintensiver ist als nötig. Aber so oder so schadet es nicht, wieder durch den Code zu gehen und den von Hand geradezubiegen. Das werde ich in nächster Zeit immer mal wieder machen, dabei auf Github PRs vorbereiten und einsenden.
Das positivste: Der für PHP 8.0 angepasste Code lief problemlos mit PHP 7.4, sicher auch mit 7.3. Die Änderungen dürften also nicht zu einem harten Bruch führen. Wenn das Projekt den hier beschriebenen Weg weitergeht sollte die nächste Serendipity-Version mit allen aktuellen PHP-Versionen zugleich funktionieren.
Serendipitys Social-Buttons mit Zähler aktualisiert
Thursday, 4. February 2021
Hier im Blog läuft das Plugin serendipity_event_social/Share Buttons, das unter den Einträgen per shariff umgesetzte datenschutzfreundliche 2-Klick-Buttons anzeigt. Mit denen kann man den Blogartikel in sozialen Netzwerken wie Twitter und Facebook teilen, aber ohne dass allein durch das Laden dieser Seite deren Code geladen wird. Das verhindert Überwachung.

Die Buttons funktionierten weiterhin, aber der Zähler war hier im Blog kaputt. Shariff hat auch ein Backend, das ich für alle Pluginnutzer auf meinem uberspace laufen lasse. Das Backend holt die Zahlen. Aber hier im Blog hatte ich es auf die falsche URL gestellt, das / am Ende fehlte. Das ist nun korrigiert.
Die Gelegenheit habe ich genutzt, um auch das Backend zu aktualisieren - es lief noch eine ältere Version. Wohl dadurch war die Facebook-API deaktiviert worden, sie ist jetzt wieder an. Das Backend-Update war wohl generell notwendig. Wenn also auch bei euch im Blog der Zähler nicht funktionierte wäre nun ein neuer Test eine gute Idee.
Beim Serendipity-Plugin musste nichts geändert werden, nur die richtige URL habe ich jetzt dokumentiert.
Ich war mir sicher, über das Plugin hier im Blog bereits geschrieben zu haben. Aber ich finde keinen Artikel dazu, nur dass ich vor 9 Jahren schonmal mit shariff experimentiert hatte. Deshalb sei hier noch erwähnt, dass das Plugin mehr macht als nur die Buttons anzuzeigen: Es baut auch das HTML, um das erste genutzte Bild oder eine gesetzte Alternative bei diesen Kästen einzusetzen, die Seiten wie Twitter bauen wenn bei ihnen ein Artikel verlinkt wird. Was ich für ein nettes Feature halte.
Und damit wäre die Vorstellung nachgeholt.
Zusätzliche Serendipity-Plugins: Entrystats, Simplepodcast, Simplestaticpage und Schema.org
Monday, 31. August 2020
Diese vier Plugins sind in unterschiedlichen Entwicklungsstadien. Allen vier gemein ist, dass ich beim Aufräumen über sie gestolpert bin und sie nicht in Spartacus sind. Ich habe sie jetzt auf Github hochgeladen. Es folgt eine Kurzvorstellung und die Frage: Was soll mit ihnen geschehen?
Entrystats
Unfertig. Es sollte eine Alternative zum Statistik-Plugin werden, das nur Artikelaufrufe zählt, dafür nur eine Zeile pro Artikel anlegt und daher nicht die Datenbank aufbläht. Ich kam wohl nicht weit, das SQL wird nur mit MySQL funktionieren. Statistiken führe ich hier nicht (mehr), aber den Ansatz eines solchen simplen Zählers finde ich immer noch interessant.
Besteht Interesse hierdran? Oder haben wir genug bessere Statistiklösungen, bzw benutzt der Großteil wie ich gar keine?
Github: serendipity_event_entrystats
Simplepodcast
Das Podcastplugin war sogar schon auf Github. Ich entwickelte es vor etwa anderthalb Jahren während der Serendipity-Entwicklungswoche, weil ein einfacher zu bedienendes Podcastplugin mit Podlove-Player gewünscht wurde. Das Plugin liefert das, samt angepasstem RSS-Feed, aber ich dachte damals es fehlt der Feinschliff um es in Spartacus zu packen.
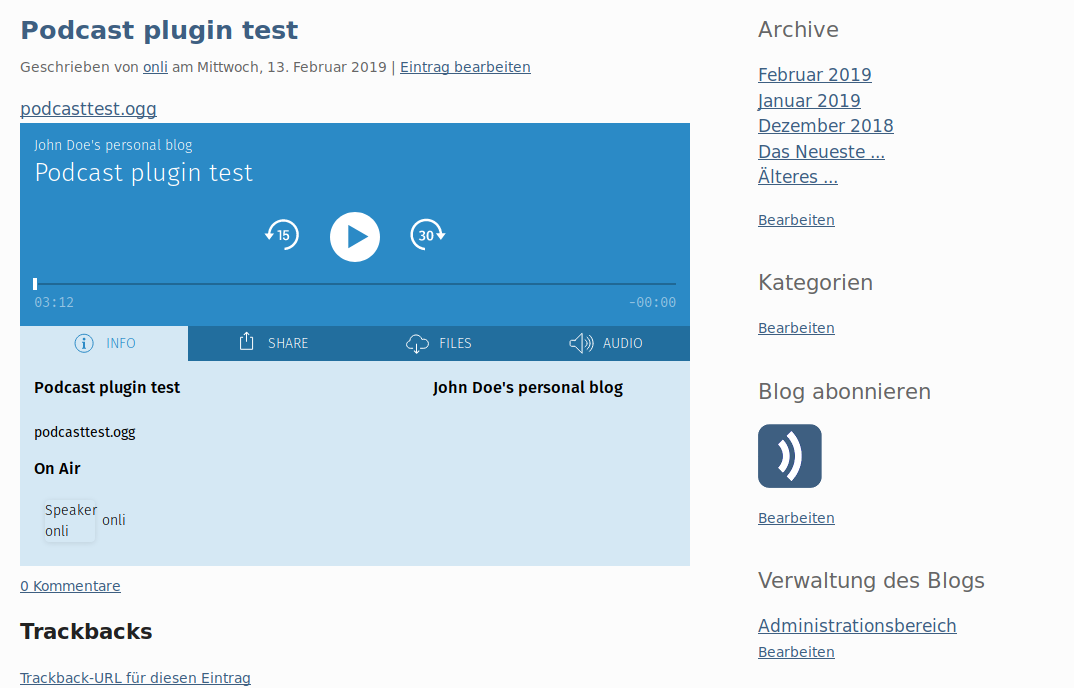
Hier bräuchte es einen Serendipity-Blogger mit Podcasterfahrung, der das Plugin nutzt und mitentscheidet ob noch was fehlt und wenn ja, welche Funktionen gebraucht werden. Oder sie direkt einbaut natürlich.
Github: simplepodcast
Simplestaticpage
Das Staticpage-Plugin ist vom Code her schwierig zu warten und auch die Benutzung ist nicht ideal. Ich weiß, dass ich mich zweimal schon an einer Lösung probiert habe: Einmal wollte ich ein neues Plugin schreiben, das die alten Datenbankeinträge übernimmt; Ein andermal eine eigenständige einfache Alternative bauen. Ich verlor wohl das Interesse und weckte den Kommentaren zufolge auch keines (an anderer Stelle möglicherweise schon).
Das ist Kernfunktionalität, gleichzeitig ist unklar ob die Blogsoftware Serendipity so ein CMS-Feature braucht. Um das in Richtung Es braucht solch ein Plugin aufzulösen bräuchte es einen Entwickler, der mit einem solchen Plugin Seiten in seinem Blog einrichten will und das Ganze mit einem Auge auf Benutzerfreundlichkeit umsetzt.
Github: serendipity_event_simple_staticpage
Schema.org
Das Schema.org-Plugin ist relativ neu und auch hier im Blog in Benutzung. Es funktioniert meines Wissens einwandfrei. So hat es in den Eintrag der Pluginvorstellung diesen Code eingebaut:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "BlogPosting",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://www.onli-blogging.de/1937/Schema.org-Plugin-fuer-Serendipity.html"
},
"headline": "Schema.org-Plugin für Serendipity",
"image": "/uploads/Screenshot_2020-06-05_Rich_Results_Test_-_Google_Search_Console.serendipityThumb.png",
"datePublished": "2020-06-05T10:02:00+0000",
"dateModified": "2020-06-08T09:51:09+0000",
"author": {
"@type": "Person",
"name": "onli"
},
"publisher": {
"@type": "Organization",
"name": "onli",
"logo": {
"@type": "ImageObject",
"width": 100,
"height": 100,
"url": "https://www.onli-blogging.de/favicon_100.png"
}
}
}
</script>
Allerdings greift Google dieses Markup nicht auf. Zumindest den Webmastertools zufolge hat es keinen Effekt. Jetzt ist die Frage: Geben wir also dieses Plugin auf, oder fügen wir es trotzdem Spartacus hinzu?
Github: serendipity_event_schema
Sollte jemand Lust haben eines der Plugins weiterzuentwickeln: Sehr gerne, deswegen sind sie auf Github. Sollte starkes Interesse an einem der Plugins bestehen könnte auch ich nochmal Zeit hineinstecken, wobei es meist mehr bringt wenn es jemand entwickelt der die Funktionen auch nutzen will. Beim Schema.org-Plugin will ich das, da weiß ich nur nicht ob es nach Spartacus soll – seht ihr darin einen Nutzen?
Schema.org-Plugin für Serendipity
Friday, 5. June 2020
Schema.org ist ein Format, mit dem man maschinenverständlich Inhalte auf Webseiten beschreiben kann. Beispielsweise nutze ich es auf pc-kombo, um bei den Komponentenseiten anzugeben über welche Komponente sie genau reden und um Reviews zu markieren. Google unterstützt schema.org stark und greift einige der Beschreibungen in den Suchergebnislisten auf, es gibt dafür eine Liste. Neben so praktischen Dingen wie Produktdaten und Reviews gibt es auch schlicht Artikel. Und ein Untertyp sind Blogartikel.
Damit Blogeinträge zu erweitern ist die vernünftige Alternative zu Googles AMP-Wahnsinn. Möglicherweise – zu der Einschränkung unten mehr – kann Google und auch jede andere Suchmaschine so Artikel besser darstellen, z.B. mit Artikelbild in ein oberes Artikelkarussell einbauen.
Thomas hat in seiner Linkliste einen Artikel von Lukas Murdock verlinkt, der zeigte wie Lukas Schema-Markup in seinem Blog hinzugefügt hat. Mir wurde klar: Das kann auch Serendipity automatisieren.
Bisher habe ich (in ursprung) schema.org direkt ins HTML gepackt. Das ist einer der drei möglichen Wege. Es ist dann also das Theme, das entsprechendes HTML generieren muss, das wäre schwierig gewesen. Aber das alternative JSON-LD kann in einem Rutsch bei der Artikelgenerierung erstellt werden. Diesen Vorteil hatte ich bisher nicht erkannt.
Ich habe das in ein Plugin gepackt:
serendipity_event_schema_0.1.tar.gz
Bei mir funktioniert es. Funktionieren bedeutet: Es produziert valides Schema-Markup, das den Artikel akkurat beschreibt. Z.B. für diesen Artikel:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "BlogPosting",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://www.onli-blogging.de/1937/Schema.org-Plugin-fuer-Serendipity.html"
},
"headline": "Schema.org-Plugin für Serendipity",
"image": "/uploads/Screenshot_2020-06-05_Rich_Results_Test_-_Google_Search_Console.serendipityThumb.png",
"datePublished": "2020-06-05T10:02:00+0000",
"dateModified": "2020-06-05T10:27:00+0000",
"author": {
"@type": "Person",
"name": "onli"
},
"publisher": {
"@type": "Organization",
"name": "onli-blogging",
"logo": {
"@type": "ImageObject",
"width": 100,
"height": 100,
"url": "https://www.onli-blogging.de/favicon_100.png"
}
}
}
</script>
Aber es gibt zwei Einschränkungen:
- Google gibt vor, dass ein Publisher angegeben werden muss, zusätzlich zum Autor, was bei privaten Blog natürlich Unsinn ist. Das Plugin kann diesen Abschnitt daher auch nicht komplett vorausfüllen, wir haben die notwendigen Daten nicht. Es schlägt vor, eine nach dem Autor benannte Organisation anzugeben, auch der Blogname würde passen. In der Pluginkonfiguration muss dieser Code angepasst werden, insbesondere der Link zum notwendigen Logo.
- Das Markup sollte mit dem Rich-Result-Tester überprüft werden. Der aber unterstützt Blogartikel nicht. Eine Erfolgsmeldung sieht daher so aus:
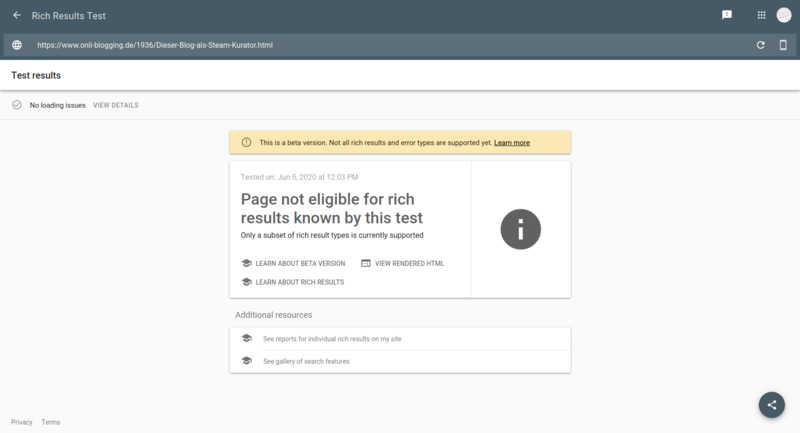
Was natürlich nicht bedeutet, dass die Daten auch sinnvoll sind, was ohne Vorschau schwierig zu erkennen ist.
Es könnte also sein, dass Google zugunsten von AMP Bogartikelauszeichnungen weitestgehend ignoriert. Das sollte ein Test in unseren Blogs zeigen. Wenn es funktioniert müsste nach einer Weile Googles Searchconsole die Rich results oder ähnliches als Suchergebnisanzeige auflisten.
Nach einer Testphase – und wenn niemand über ein Plugin stolpert, das diese Aufgabe bereits erledigte, ich hatte mir nämlich eingebildet wir hätten schon ein Plugin für Schema.org gehabt – werde ich das Plugin in Spartacus hochladen.

