Unverstelltes Routing in Flutter: NamedRoutes mit Animationen
Tuesday, 15. November 2022
Wie man in Flutter von einer Seite zur nächsten wechselt ist nicht ganz einfach, obwohl es eigentlich doch ganz simpel ist. Der Navigationsaufruf ist schnell geschrieben. Doch primär definiert man keine Seiten, sondern Widgets, und ob die jetzt alleine angezeigt werden oder nur als Teil eines anderen Widgets hängt einzig von ihrer Verwendung ab – schon das ist verwirrend. Dazu gibt es nicht den einen Weg, das Routing aufzusetzen, sondern viele: Das Flutter-Projekt selbst kennt mit dem Navigator (1.0), dem Router (2.0) und jetzt mit dem go_router (2.0+ ?) direkt drei offizielle Möglichkeiten, wobei sich hinter dem Navigator gleich mehrere Möglichkeiten verbergen und der Router 2.0 komplett vage ist. Dazu kommen die vielen Routing-Plugins auf pub.dev, alle mit ihren eigenen Vor- und Nachteilen.
Dieser Artikel wird nicht alle diese Möglichkeiten vorstellen. Stattdessen zeige ich einen Weg, wie man völlig ohne Plugins strukturiert die Routen anlegen und ihre Übergänge animieren kann. Dazu gehört dieses Git-Repo, in dem der Code komplett nachvollzogen werden kann.
Das Grundlagenbeispiel
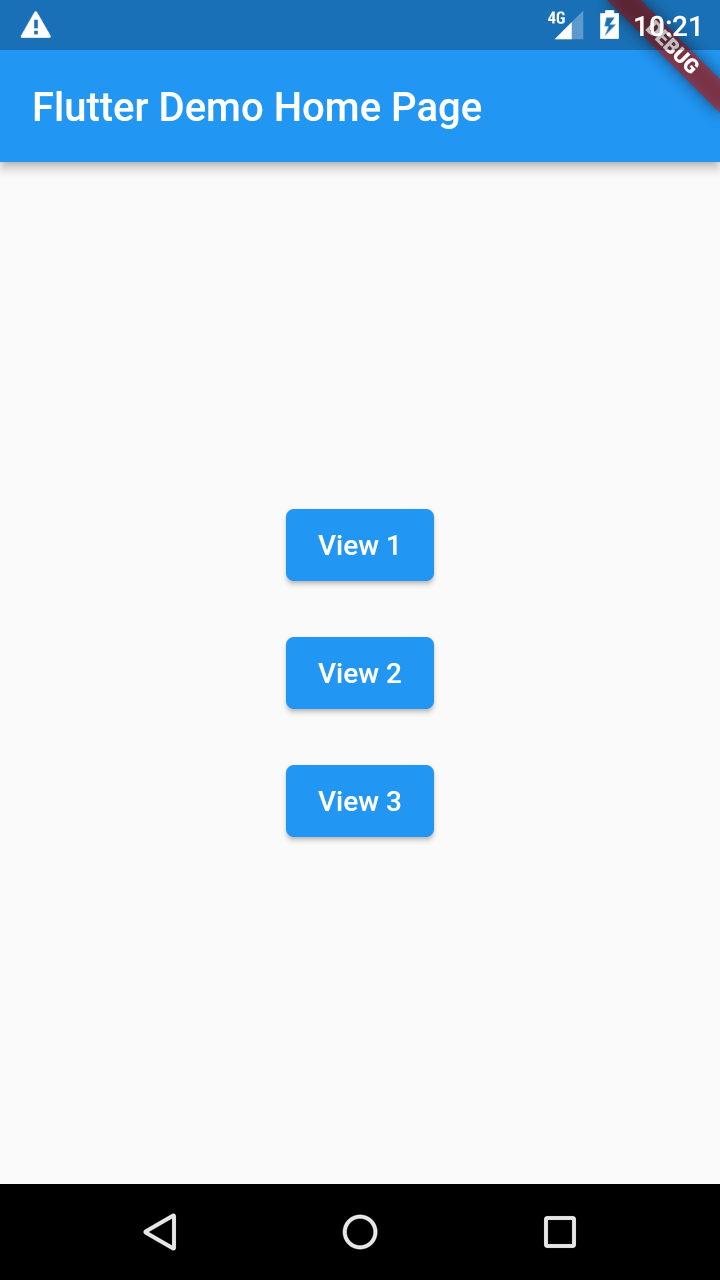
Ich werde hier mit einer einfachen Flutter-Anwendung mit einer main.dart und drei Widgets view[123].dart benutzen. Die drei Widgets sollen jeweils als eigene Seiten aufgerufen werden. Sie sind so definiert:
import 'package:flutter/material.dart';
class View2 extends StatelessWidget {
const View2({super.key});
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(title: const Text('View 2')),
body: const Center(
child: Text('View 2'),
),
);
}
}
Und der Startbildschirm zeigt drei Buttons untereinander in einer Reihe:
class MyHomePage extends StatelessWidget {
final String title;
const MyHomePage({super.key, required this.title});
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(title: Text(title)),
body: Column(
crossAxisAlignment: CrossAxisAlignment.center,
mainAxisAlignment: MainAxisAlignment.center,
children: [
Center(
child: Padding(
padding: const EdgeInsets.all(8.0),
child: ElevatedButton(
onPressed: () => null,
child: const Text('View 1')),
),
),
Padding(
padding: const EdgeInsets.all(8.0),
child: ElevatedButton(
onPressed: () => null,
child: const Text('View 2')),
),
Padding(
padding: const EdgeInsets.all(8.0),
child: ElevatedButton(
onPressed: () => null,
child: const Text('View 3')),
),
],
),
);
}
}
v0.1: Simple NamedRoutes
Diese drei Buttons sollen nun jeweils zu ihrem Widget navigieren.

Schauen wir uns also erstmal an, wie einfache NamedRoutes funktionieren. Den Namen entsprechend bekommt hier eine Route einen Namen und wird darüber aufgerufen, ähnlich einer URL. Man erstellt dafür eine routes.dart mit einem solchen Inhalt:
import 'package:flutter/material.dart';
import 'package:flutter_navigation/view1.dart';
import 'package:flutter_navigation/view2.dart';
import 'package:flutter_navigation/view3.dart';
final routes = {
'/view1': (BuildContext context) => const View1(),
'/view2': (BuildContext context) => const View2(),
'/view3': (BuildContext context) => const View3(),
};
Die muss nun der Flutteranwendung zugewiesen werden:
class MyApp extends StatelessWidget {
const MyApp({super.key});
@override
Widget build(BuildContext context) {
return MaterialApp(
title: 'Flutter Demo',
theme: ThemeData(
primarySwatch: Colors.blue,
),
home: const MyHomePage(title: 'Flutter Demo Home Page'),
routes: routes, // genau hier
);
}
}
Und schon können die Buttons eine Funktion bekommen:
ElevatedButton(
onPressed: () => Navigator.of(context).pushNamed('/view2'),
child: const Text('View 2'),
)
Navigator.of(context) holt sich den Navigator, pushNamed navigiert zum zuvor angelegten Widget. Mit einem Navigator.of(context).pop() würde man wieder zurückkommen, es gibt hier also einen Navigations-Stack.
v0.2: NamedRoutes mit Argumenten
Was aber, wenn bei der Navigation auch Daten an das Widget gegeben werden sollen?
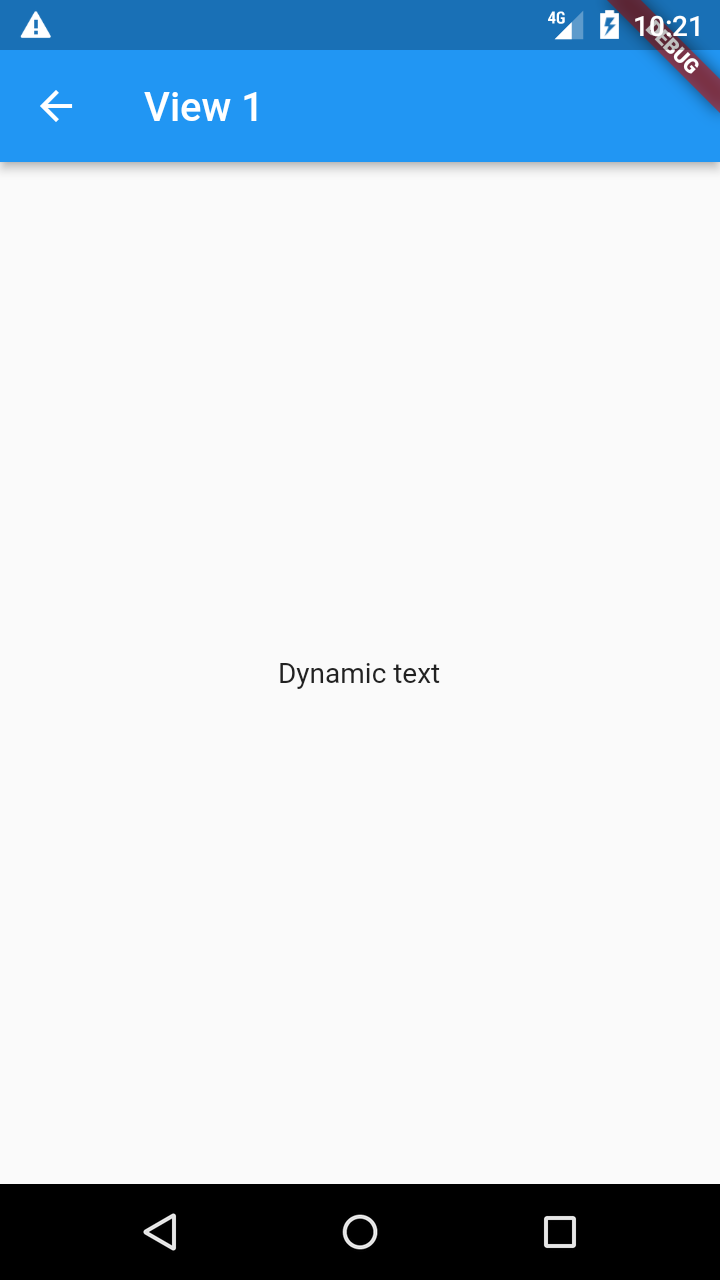
Dafür gibt es Argumente. Um genau zu sein gibt es ein Arguments-Objekt, in das alles beliebige gespeichert werden kann. Zum Beispiel hier eine Map mit einem String, den das Widget dann anzeigen soll:
ElevatedButton(
onPressed: () => Navigator.of(context).pushNamed('/view1',
arguments: {
'content': 'Dynamic text',
}),
Damit das Widget es auch bekommt, müssen wir seine Route in der routes.dart ändern:
'/view1': (BuildContext context) {
final args =
ModalRoute.of(context)!.settings.arguments as Map<String, dynamic>;
return View1(
content: args['content']!,
);
},
Wir machen uns hier zunutze, dass Dart (zumindest seit der Version für Flutter 3) mit den Typen recht flexibel umgehen kann, sodass content nicht manuell in einen String umgewandelt werden muss. Das Widget kann mit dem Parameter direkt arbeiten:
import 'package:flutter/material.dart';
class View1 extends StatelessWidget {
final String content;
const View1({super.key, required this.content});
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: const Text('View 1'),
),
body: Center(
child: Text(content),
),
);
}
}
Das Widget kann nun dynamisch bei jedem Navigationsaufruf mit einem anderen Text befüllt werden.
Schön an diesem Ansatz ist der geringe Aufwand. Es braucht keine eigene Klasse für die Widget-Argumente, weil sie einfach in eine Map gepackt werden. Und da bei der Map der Value-Typ auf dynamic gesetzt wurde kann beliebiges übertragen werden. Eine automatische Codegenerierung wie bei auto_route hier draufzusetzen scheint unnötig.
v0.3: NamedRoutes mit wählbaren Animationen (und Argumenten)
Die Animationen anpassen zu können dagegen wird für manche Anwendungen nötig sein. Ich zeige einen erweiterbaren Ansatz. Er wird mit onGenerateRoute der MaterialApp arbeiten.
Das ist jetzt viel auf einmal:
return MaterialApp(
title: 'Flutter Demo',
theme: ThemeData(
primarySwatch: Colors.blue,
),
home: const MyHomePage(title: 'Flutter Demo Home Page'),
onGenerateRoute: (settings) {
if (routes.containsKey(settings.name)) {
final args = settings.arguments as Map<String, dynamic>?;
return PageRouteBuilder(
settings: settings,
pageBuilder: (context, animation, secondaryAnimation) =>
routes[settings.name]!(context),
transitionsBuilder:
(context, animation, secondaryAnimation, child) {
switch (args?['transition']) {
case Transitions.scale:
return ScaleTransition(scale: animation, child: child);
case Transitions.fade:
return FadeTransition(opacity: animation, child: child);
default:
return SlideTransition(
position: Tween<Offset>(
begin: const Offset(0.0, 1.0),
end: Offset.zero,
).animate(animation),
child: child,
);
}
});
}
// Unknown route
return MaterialPageRoute(builder: (context) => Container());
},
);
Also, was ist hier passiert:
Zuerst wurde der routes:-Parameter entfernt. Wäre er noch da, hätte er Priorität und unser neuer Code in onGenerateRoute würde ignoriert.
Der nächste Kniff ist pageBuilder: (context, animation, secondaryAnimation) => routes[settings.name]!(context). Hiermit wird beim Seitenbau in routes nach einer Route gesucht. So kann die alte routes.dart weiterbenutzt werden, sie muss nichtmal editiert werden. Gut so, denn dadurch behalten wir einen festen Ort für übersichtliche Routendefinitionen.
Es folgt der transitionsBuilder. Der schaut, ob bei dieser Navigation das Argument transition übergeben wurde. Wenn ja und es einen bestimmten Wert hat, wird eine der vordefinierten Übergangsanimationen gesetzt. Dafür wurde ein bislang nicht gezeigtes Enum angelegt:
enum Transitions { scale, fade }
Die Navigation mit Animationsauswahl sähe nun nicht viel anders aus als zuvor:
ElevatedButton(
onPressed: () => Navigator.of(context).pushNamed('/view1',
arguments: {
'content': 'Dynamic text',
'transition': Transitions.scale
}),
child: const Text('View 1')),
),
Das ginge natürlich auch anders – so hatte ich eine Variante mit dem Plugin page_transition entwickelt, die brauchte aber Änderungen an der routes.dart.
Dieser Artikel und Ansatz ist ein Nebenprodukt meiner Analyse von Flutters Routingsituation. Die vielen Lösungen waren chaotisch präsentiert, viele erschienen mir auch unnötig kompliziert. NamedRoutes stachen direkt als klar verständliche Lösung heraus, aber wie sie gut zu benutzen sind, samt Argumenten und Animationen, sah ich nicht erklärt. Ob sie dazu überhaupt taugen? Sie tun es, wie hoffentlich deutlich wurde.
Laut Dokumentation sollen NamedRoutes Nachteile haben – bei Push-Benachrichtigungen würden sie immer ihr Ziel öffnen, selbst wenn es schon offen sei (ist das in der onGenerateRoute wirklich nicht abfangbar?) und bei Webanwendungen als Kompilierziel der Vorwärtsbutton im Browser mit ihnen nicht funktionieren (kein Problem für mich, da ich Flutter für Webanwendungen ungeeignet finde). Wer darüber stolpern würde sollte sich wahrscheinlich als zweitbeste Lösung den go_router ansehen.
Ein Jahr mit Flutter
Monday, 11. October 2021
Gut ein Jahr ist es her, dass ich angefangen habe mit Flutter zu arbeiten. Der Auftrag: Eine nutzerfreundliche Anwendung für Android und iOS mit einer gemeinsamen Codebasis zu bauen. Ich fand das Framework zur Mobilanwendungsentwicklung zu Beginn ziemlich toll. Wie sieht es jetzt aus?
Ich finde Flutter immer noch gut, aber habe inzwischen auch mehr von den Schwachstellen mitbekommen. Eine Liste der positiven und der negativen Erkenntnisse folgt.

Gut: Der Widgetbaum
Bei Flutter baut man die Oberfläche, indem die von der Sprache bereitgestellten Widgets in der Build-Funktion eigener Widgets kombiniert werden. Da hat dann eine Row zwei Columns, in denen jeweils drei Buttons sind, schon hat man ein Grid von Buttons mit zwei Spalten und drei Zeilen. Angelehnt am Material-Design gibt es alle wichtigen Widgets vordefiniert, wenn das nicht reicht können aus ihnen neue gebaut oder mit Plugins fertige eingebunden werden.
Das funktioniert einfach sehr gut. Was in anderen Programmiersprachen in den imperativen Aufrufen unweigerlich zum Chaos wird, bleibt mit diesem Prinzip mit nur wenig benötigter Disziplin gut beherrschbar. Die so entstehenden UI-Files sind viel lesbarer und doch auch mächtiger, als wenn es XML-Dateien wären, aber die Zustandsverwaltung und damit die Logik der App soll eindeutig extern definiert werden. Diese propagierte Trennung funktioniert gut, kann für einfache Screens aber trotzdem ignoriert werden, die Logik wird dann mit in die UI gepackt. Aber das macht man selten. Das ist genau die richtige Mischung aus einem guten Konzept und der benötigten Entwicklerfreiheit.
Gut: Zustandsverwaltung mit GetX
Als ich anfing war GetX bei uns umstritten. Ich hatte mir das und als Alternative Bloc angesehen und dann darauf bestanden, dass wir GetX zumindest auch benutzen. Mittlerweile hat GetX sich voll bewährt.
Mit GetX definiert man im Controller der UI spezielle Variablen. Wenn eine davon sich ändert, ändern sich auch die UI-Stelle an denen die Variable verwendet wird. Zum Beispiel hat man im Controller ein Set, baut in der UI daraus eine Liste, und wenn das Set ein Element mehr bekommt wird auch die UI-Liste länger. Das gelingt GetX auf der einen Seite mit möglichst wenig Deklarationen, aber gleichzeitig ist der Voodoo-Aspekt viel geringer als bei Bloc. Dass es keine unnötigen abstrakten Konzepte wie Cubits hat kommt noch dazu.
GetX hat ein paar Stolperfallen, so erkennt es nicht automatisch wenn sich der Inhalt eines Elements des Sets ändert. Da muss man nachhelfen, aber immerhin geht das. Insgesamt ermöglicht es eine effiziente Anwendungsentwicklung ohne Bullshit.
Gut: Die Pluginauswahl
Mit pub.dev gibt es eine klare und hilfreiche Anlaufstelle für Plugins. Dort gibt es Plugins für alles was wir bisher gebraucht haben. Einen kompletten Kalender, Kryptographie, Loginformular, Benachrichtigungen, das oben erwähnte GetX – noch viel mehr und insgesamt alles wurde abgedeckt, mit oft hochqualitativ wirkenden und konfigurierbaren Plugins.

Diese zentrale Quelle zu haben ist viel besser als die mühsame Library-Suche bei Android und auch besser als bei allen anderen Programmiersprachen bzw Frameworks, die ich kenne.
Gut: Dart
Dart hat mich nicht enttäuscht. Ich erwartete das anfangs: Zu hübsch und trotz der Typisierung Ruby-artig war diese Sprache, das konnte nicht wahr sein. Aber es ist wahr. Dart ist einfach ganz wunderbar.
Nicht so dynamisch wie Ruby zu sein schadet ihr an manchen Stellen, vor allem bei der fehlenden Serialisierbarkeit und dem immer noch äußerst umständlichen Umwandeln von Objekten nach JSON (und wieder zurück) schlägt das zu. Aber das erwartete überraschende Fehlverhalten, die frusterregenden Implementierungsfehler – all das blieb aus. Dart würde ich sogar außerhalb von Flutter verwenden, zumindest wenn Ruby nicht verfügbar wäre; vielleicht sogar wenn Ruby verfügbar wäre.

Schlecht: Respektlose Weiterentwicklung
Das größte Problem Flutters ist die respektlose Weiterentwicklung des Frameworks, daher fange ich damit an. Es fehlt den Google-Entwicklern jeglicher Respekt vor der Zeit der Frameworknutzer, was sich in unverschämten und unnötigen Änderungen und völliger Missachtung der Abwärtskompatibilität niederschlägt.
Flutter ist in diesem Jahr von 1.x auf 2.x geklettert. Die große – aber nicht die einzige – Änderung war Null–Safety, was theoretisch optional bleibt aber faktisch durch Plugins erzwungen wird. Null-Safety bedeutet, dass Variablen nicht mehr null werden können, sind sie nicht entsprechend deklariert worden. int? x darf ich auf null setzen – die ?-Syntax-Deklaration ist neu –, int x nicht. Entsprechend muss all der Code der mit einem vorher definierten int x arbeitet angepasst werden, sodass er niemals x ein null zuweisen kann, oder die Deklaration angepasst und dann der Zustand von x an den Schnittstellen zu anderem null-sicheren Code überprüft werden.
Das vermeidet Abstürze, aber es ist ein Riesenwechsel für bestehende Anwendungen. Gut, es gibt ein Migrationstool – aber es funktioniert nicht. Schon bei unserer vergleichsweise simplen App war es überfordert und quittierte nach Tausend Fehlermeldungen den Dienste. Ich habe die Migration komplett per Hand machen müssen.
Es ist auf der einen Seite verständlich, dass ein junges Framework sich noch ändert. Aber alten Code so unbrauchbar zu machen, Migrationstools beiseite zu stellen die schlicht nicht funktionieren, dafür gibt es keine Entschuldigung.
Und bei dieser einen Änderung bleibt es ja nicht. Im gleichen Atemzug wurden beispielsweise auch einfach mal die bisherigen Buttonklassen deprecated. Und die neuen haben eine völlig andere API, sie werden mit viel kompliziertem Code angepasst. Es ist okay ein neues System für Buttons dem Framework hinzufügen, aber die alten abzuschaffen ist eine völlig unnötige Gängelung.
Hier schlägt das System Google durch: Tausende Entwickler arbeiten am Framework, die kleinen frameworknutzenden Entwicklerstudios verbringen dann ihre Zeit damit den dauernden Änderungen hinterherzurennen. Das ist einerseits monopolsichernd und andererseits ein Strukturproblem der Organisation Google, aber die Ursache zu verstehen hilft in der Praxis wenig.
Schon deswegen würde ich Flutter nicht für ein FOSS-Projekt empfehlen, es ungern selbst in meiner Freizeit nutzen, sogar Firmen gegen die Nutzung raten. Wobei: Android und iOS nativ zu bespielen ist auch nicht besser, wenn eine Mobilanwendung wirklich sein muss ist Flutter immer noch besser als das. Aber was für eine vertane Chance Flutter doch ist, nur durch schlechtes Google-Projektmanagement.
Schlecht: Die Pluginweiterentwicklung
Was für die Sprache gilt, gilt für die Plugins nur noch mehr: Da wird in einem durch fröhlich alter Code kaputtgemacht. Es ist zwar alles auf dem Papier SemVer, doch in der Praxis hält das die wenigsten Entwickler davon ab mit Patch- und Funktionsupdates alten Code invalid zu machen. Migrationsguides sind dann unvollständig und versteckt in Github-Issues, eine Kryptolibrary kann den eigenen Ciphertext nicht mehr lesen, ein Router (ein Modul um die Ansicht zu wechseln) wird so vollständig umgebaut dass jeder Aufruf angepasst werden muss, ohne dass die Dokumentation das auch nur erwähnt. Und spätestens durch Null-Safety wurden die Upgrades nicht-optional, man kann sich ihnen nicht entziehen.
Wenn man es vorher wüsste würde man nur Abhängigkeiten auf Module vernünftiger Entwickler aufbauen. Aber das sieht man im Vorhinein eben nicht immer. Und im Flutterland scheinen die besonders selten zu sein. Vielleicht kommt das aus der früheren Javascript-Herkunft.
Schlecht: Kompilierzeiten und -aufwand
Meine Firma macht die Flutterentwicklung mit Visual Studio Code und hat mir ein nettes Laptop gestellt, mit einem Ryzen 7 3700U und 16GB Ram. Das reichte nicht. Ich brauchte zuerst ein Ramupgrade, um beim Kompilieren (mit Emulator und Browser offen, klar) nicht immer wieder ein einfrierendes System zu haben. Und trotz dem modernen und starken Prozessor (und natürlich einer SSD) dauert das Bauen der Androidanwendung inzwischen einfach lange. Schon eher Minuten als Sekunden. Und dabei ist die von uns gebaute App nicht riesig.
Es gibt zwar wie bei Android Studio ein Hot Reload, aber das bringt bei Änderungen der Controller wenig, denn die bleiben bei ihrem alten Zustand. Das genügt also nur in den seltensten Fällen, daher wird viel kompiliert und dabei gewartet. Ich müsste im Grunde an einer Threadripper-Workstation arbeiten. Das macht bei meiner Dauer-Heimarbeit ja sogar Sinn, nur war die ungeplant und sollte das für die Mobilanwendungsentwicklung auch einfach nicht nötig sein.
Schlecht: Webapps
Flutter kann auch Webapps bauen, aber das Ergebnis sind Javascriptmonster die sich an keine Webkonventionen halten. Nutzer können nichtmal Text kopieren, wird das Standard-Textwidget benutzt. Völlig unverständlich, solche Macken blockieren komplett die Adaption des Frameworks im Webbereich.

Ambivalent: Limitierungen der Mobilplattformen bleiben erhalten
Genug von den klar negativen Eigenschaften. So wie Flutter gute und schlechte Seiten hat, sind manche Eigenschaften des Frameworks weder klar negativ noch positiv.
So umschifft Flutter die tieferen Limitierungen der mobilen Betriebssysteme einfach genau gar nicht. Arbeiten im Hintergrund beispielsweise geht unter Android manchmal, unter iOS praktisch nicht. Aber es das Framework hat keine Infrastruktur, um das doch zuverlässig zu können, nichtmal unter dem eigenen Betriebssystem Android. Anderes Beispiel: Geplante Benachrichtigungen beschränkt iOS auf 64, Android auf mehrere Hundert, Flutter und seine Plugins lässt den Entwickler in diesen Unterschied schlicht reinrennen. Unter Android kann man aus einem Formular Zurück-Swipen und dann in einem Dialog vor verlorengehenden Daten warnen, unter iOS geht das nicht. 2018 hat ein Entwickler das Problem nicht verstanden, seitdem ist es im Kern ungefixt.
Wäre Flutter nicht von Google könnte man dem Framework solche Limitierungen nur schwer anlasten. Aber weil Google mit seiner Größe und Rolle als Androidentwickler die Möglichkeiten hätte hier Lösungen anzubieten, kann ich das dem Framework nicht einfach durchgehen lassen. Es stellt zwar in manchen Bereichen eine brauchbare gemeinsame Basis für die Entwicklung von iOS- wie Androidanwendungen her, das ist der positive Teil. Aber es übertüncht die Unterschiede ungenügend, aber macht es dabei trotzdem schwerer die Stärken von Android zu nutzen, wie dessen eigentlich funktionierende Hintergrundthreads via WorkManager oder Vorgängerlösungen. Und das macht Flutters Vorzüge etwas kaputt.
Ambivalent: Die deklarative Widgetverwaltung
In Flutter werden Widgets einmal deklariert, dabei konfiguriert, später reagieren sie nur noch auf Interaktionen vom Nutzer oder Zustandsänderungen. Das ermöglicht den oben gelobten expliziten Widgetbaum, das ist positiv. Aber Widgets so gar nicht imperativ manipulieren zu können ist manchmal hochproblematisch. Wie schließt man zum Beispiel auf Knopfdruck das geöffnete Overlay eines Autocomplete-Widgets? Nur durch einen Hack, indem man mit dem FocusManager dem Widget den Fokus entzieht.
Andere Dinge gehen manchmal einfach gar nicht. Hier müssten die Entwickler eine bessere Mischung zwischen Konzepttreue und Entwicklerbefähigung finden.
Ambivalent: Performance
Flutter will Anwendungen mit 60 FPS zeichnen, inzwischen sogar mit 120 FPS auf entsprechenden Geräten. Was ist mit 360 FPS bei Webanwendungen? Okay, bleiben wir fair. Aber auch das erklärte 60-FPS-Ziel ist illusorisch, wenn beim ersten Öffnen einer App es an allen Ecken und Enden laggt. Da müssen z.B. noch die Shader kompiliert werden, was gerade unter iOS massiv zu Einschränken führt. Erst die gerade veröffentlichte Version 2.5 schafft da vielleicht Abhilfe.
Es stimmt, dass die gebauten Oberflächen ansonsten meist performant laufen. Deswegen ist der Punkt nicht unter den schlechten Seiten eingeordnet. Aber können das nicht im Grunde alle Frameworks zur mobilen Appentwicklung? Sobald etwas im Hintergrund rennt muss das auch bei Flutter manuell in einen Thread geschoben werden, was nicht immer geht, dazu kommen dann die Shader-Stotter. Vielleicht bewerte ich hier Flutter sogar zu positiv.
Ambivalent: Die Testumgebung
Und schließlich ist da noch die Testumgebung. Flutter kann Unit-, Widget- und nun auch Integrationstests. Bei Unittests sollen einzelne Bestandteile des Codes getestet werden, mit Widgettests der gewünschte Aufbau der UI kontrolliert, mit Integrationtests der Ablauf der kompletten App. Das ist alles eingebaut und Tests zu schreiben ist mit dem System keine Qual, immerhin.
Aber andererseits sind die Testumgebungen für Unit- und Widgetttests lächerlich beschränkt. Unittests können im Grunde nichts machen außer lokal Dart-Code ausführen, aber nicht mit dem System interagieren, keine HTTP-Requests senden. Soll eine API-konsumierende Funktion getestet werden darf man die API dann mocken. Es gibt zwar Leute, die das für die richtige Art halten Unit-Tests zu schreiben. Aber ich halte das für eine irrige Position, denn es führt zu einen riesigen Aufwand und verhindert, dass Tests echte Fehlerfälle erkennen.
Bei bei den Integrationtests gibt es diese Beschränkungen zwar nicht, aber dafür gibt es sie erst seit kurzem. Integrationtests funktionieren erst seit einem Umbau des Systems, der erst jetzt fertig wurde. Davor waren sie undokumentierterweise einfach kaputt, ich zumindest kriegte sie partout nicht zum Laufen. Und das ging wohl vielen so. Sie müssen auch immer noch auf simulierten oder echten Geräten laufen, was in einer CI-Infrastruktur aufwendig und damit im Zweifel teuer ist.
Flutter ermöglicht das Testen des Codes. Vielleicht macht es das besser als andere Frameworks in dem Bereich. Aber es ist viel komplizierter als ideal.
Fazit: Die rosa Brille ist weg
Ich mag Flutter immer noch. Man muss sich vor Augen halten, wie hochproblematisch die native Anwendungsentwicklung sein kann, schon wirken die Probleme des Frameworks weniger gewichtig. Dart ist sogar toll. Insgesamt schafft mein kleines Team tolle Arbeit und auch ich fühle mich mit Flutter produktiv. Meine Nutzertests bestätigen den positiven Eindruck des Ergebnis, das war dann sogar großartig.
Aber es ist dann eben doch ein Google-Framework, seine hässlichen Seiten passen genau dazu. Serendipity versucht wahrscheinlich seit fast 20 Jahren mit einem Mini-Team Abwärtskompatibilität beizubehalten, bei Flutter kriegt ein Milliardenunternehmen es nicht mein erstes aktive Jahr hin.
Auch die Stärken passen: Cross-Plattformanwendungen mit wenig Aufwand und einem so guten Konzept bauen zu können passt zu der technischen Leistungsfähigkeit dieses Unternehmens. Die sieht man am Anfang, daher damals mein erster sehr positiver Eindruck. Die Schwächen sieht man dann später, daher mein jetzt etwas durchwachsenerer.
Ich hoffe, meine Bewertung kann dem einen oder anderen Leser bei seiner Entscheidung helfen, ob er Flutter verwenden sollte oder nicht. Ich möchte wirklich nicht zu stark von abraten – die beworbenen Stärken sind ja da. Nur sollte man sich der Schwächen des Frameworks ebenfalls bewusst sein.
YouTube-Videos einbinden, ohne dass die Seite lahm wird (+Serendipity-Plugin)
Friday, 4. June 2021
Wenn mehrere YouTube-Videos auf einer Seite landen wird diese ziemlich schwer. Zumindest, wenn man den Einbindungscode nutzt den YouTube selbst vorschlägt. Da das hier im Blog schnell mal passiert, so wie jetzt, da mehrere Artikel mit Videos auf der Hauptseite sind, habe ich mich nach Alternativen umgesehen.
Normalerweise sieht das Iframe so aus:
<iframe width="560" height="315" src="https://www.youtube.com/embed/XhG-4zdVx0I" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
Auf den ersten Blick harmlos. Das Problem ist all das Javascript, das in diesem Iframe dann bezogen wird. Was sofort geschieht, da nach dem Laden die Iframe-Zielseite sofort den Player initialisiert.
Auf dev.to schlug Arthur vor, stattdessen ein alternatives Iframe zu nutzen:
<iframe
width="560"
height="315"
src="https://www.youtube.com/embed/XhG-4zdVx0I"
srcdoc="<style>*{padding:0;margin:0;overflow:hidden}html,body{height:100%}img,span{position:absolute;width:100%;top:0;bottom:0;margin:auto}span{height:1.5em;text-align:center;font:48px/1.5 sans-serif;color:white;text-shadow:0 0 0.5em black}</style><a href=https://www.youtube.com/embed/XhG-4zdVx0I ?autoplay=1><img src=https://img.youtube.com/vi/XhG-4zdVx0I/hqdefault.jpg><span>▶</span></a>"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen
></iframe>
Das ist schon von mir leicht verändert und der Artikel beschreibt verschiedene Zwischenschritte auf dem Weg zu dieser Lösung. Schaut euch das ruhig im Originalartikel an.
Aber die Kernidee ist, dass in dem Iframe der Videoplayer erst nach einem Klick auf das Vorschaubild geladen werden wird. Statt einem halben MB an Code ein kleines Bildchen zu laden geht beim ersten Laden der Seite wesentlich schneller. Und da das Video nach einem Klick wie zuvor sofort startet, dank dem autoplay=1, wird dem Seitenbesucher der Unterschied kaum auffallen. Denn das ist das Ergebnis:
Einfluss auf die Seitenperformance
Ich stolperte über diese Baustelle, als ich die neue Version Googles Pagespeed testete. Beim Prüfen dieses Blogs hier erschrak ich über das miserable Ergebnis:

Gut, die Mobilvariante des Tools ist häufig sehr hart, aber so schlecht hatte ich meinen Blog nicht gesehen. Ein Blick auf die Problemliste zeigte dann deutlich, dass Youtube-Videos die Ursache sind:
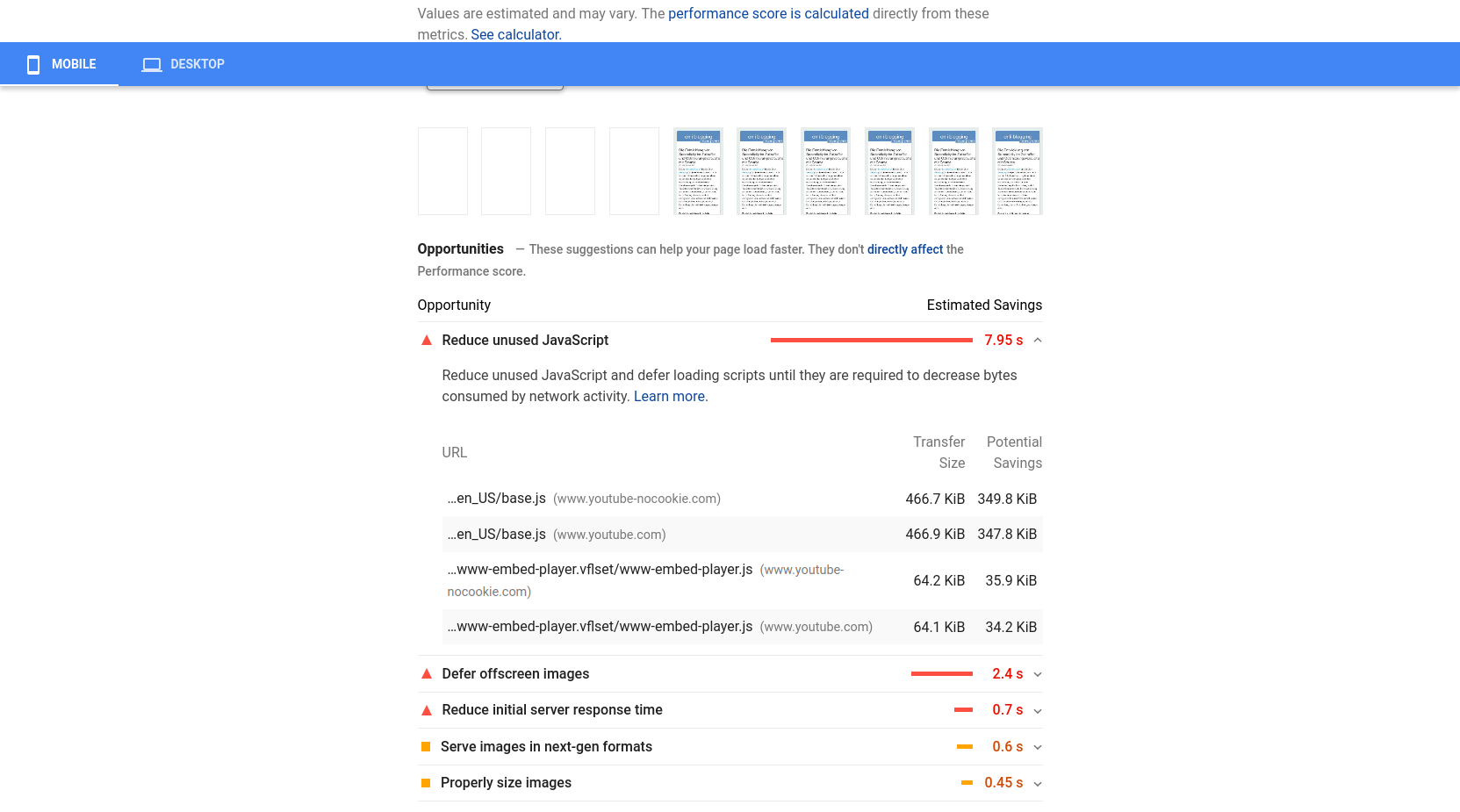
Was schlicht daran liegt, dass derzeit mehrere Artikel mit Videos von Youtube hier auf der Startseite sind.
So sieht das Ergebnis jetzt aus, da alle diese Videos mit den neuen Iframes ersetzt sind:

Viel besser! Sogar für Telefone wird die Geschwindigkeit der Seite als hervorragend bewertet. Wie es bei einem einfachen Blog ja auch sein soll.
Serendipity-Plugin
Ich wollte die regulären Iframes nicht per Hand ersetzen. Und generell wollte ich den originalen Code beibehalten. Ich gehe davon aus, dass die Kompatibilität mit dem derzeitigen Einbindungscode fast für ewig erhalten bleiben wird. Während bei dem angepassten Iframe Annahmen drin sind die sich ändern könnten, vor allem der Pfad zum Vorschaubild.
Deswegen habe ich ein Plugin geschrieben, das die normalen Iframes umwandelt. Der Blogger schreibt also ganz normal seinen Artikel, bezieht den normalen Einbettungscode von Youtube, und das Plugin serendipity_event_lazyoutube wandelt dann automatisch diesen Code von Youtubes lahmen Standard-Iframe zu der hier gezeigten schnellen Alternative um, die den Videoplayer erst nach einem Klick auf das Vorschaubild lädt.
Außerdem kann man damit, angelehnt an oEmbeds, den Einbettungscode vom Plugin erstellen lassen – falls einem das Bewahren des Original-Iframes im Artikelquellcode nicht so wichtig ist. Statt dafür nur einen Link zu setzen geht das mit [Youtube-Link], also [https://www.youtube.com/watch?v=XhG-4zdVx0I] für das Video von oben.
Nur damit der zu erstellende Code einfacher zu erzeugen ist habe ich oben auch das Iframe angepasst. Im Original ist da noch an zwei Stellen der Titel des Videos drin. Aber um den abzufragen müssen wir mit der Youtube-API arbeiten oder den Artikelschreiber das eintragen lassen, beides wollte ich vermeiden.
Das Plugin ist ganz frisch und es fehlt mindestens noch der Versuch, gewählte Anfangszeiten zu unterstützen. Deshalb liegt es bisher nur in einem eigenen Github-Repo. Hier im Blog ist es aber schon aktiv und Tester wären mir hochwillkommen.
7GUIs in Flutter (2/7)
Friday, 13. November 2020
Die sieben Aufgaben von 7GUIs sollen typische Problemstellungen bei der Anwendungsentwicklung widerspiegeln. Dann können die gebauten Lösungen dafür benutzt werden, verschiedene Programmiersprachen und Toolkits miteinander zu vergleichen.
Ich dachte, das ist eine gute Gelegenheit hier nochmal Flutter zu zeigen. Die Vorstellung letzten Monat zeigte relativ wenig von den damit baubaren Oberflächen.
Flutter ist ja deklarativ aufgebaut, das heißt die Oberfläche baut sich immer wieder neu und reagiert dann auf die neuen Variablenwerte. Man kann dafür StatefulWidgets benutzen, die Variablen im Widget-Stateobjekt speichern und dann immer mit setState anzeigen, dass die Oberfläche sich doch bitte neubauen soll. Ich werde stattdessen mit GetX der Oberfläche einen Controller zur Seite stellen, in dem die Variablen leben und der dafür sorgt, dass auch Widgets ohne reguläres Zustandsobjekt interaktiv sein können. Aber seht selbst:
1. Counter
Die erste Aufgabe ist ein Klickzähler. Doch einen Counter zu erstellen ist keine Herausforderung, das ist das Standardbeispiel auf der Flutterhomepage und bei Modulen wie GetX, die das Statemanagement übernehmen wollen. Entsprechend habe ich hier nur das GetX-Beispiel genommen und die Oberfläche angepasst.
So sieht es aus:

Die Oberfläche ist eine Row, in der ein Textfeld und ein Button sind.
Das ist der Code:
import 'package:flutter/material.dart';
import 'package:get/get.dart';
void main() {
runApp(MyApp());
}
class MyApp extends StatelessWidget {
// This widget is the root of your application.
@override
Widget build(BuildContext context) {
return MaterialApp(
title: 'Counter',
theme: ThemeData(
visualDensity: VisualDensity.adaptivePlatformDensity,
),
home: MyHomePage(),
);
}
}
class MyHomePage extends StatelessWidget {
// Instantiate your class using Get.put() to make it available for all "child" routes there.
final Controller c = Get.put(Controller());
@override
Widget build(context) => Scaffold(
appBar: AppBar(title: Text('Counter')),
body: Center(
child: Row(
mainAxisAlignment: MainAxisAlignment.spaceAround,
children: [
// Use Obx(()=> to update Text() whenever count is changed.
Obx(() => Text("Clicks: ${c.count}")),
RaisedButton(child: Text("Count"), onPressed: () => c.increment()),
],
)));
}
class Controller extends GetxController {
var count = 0.obs;
increment() => count++;
}
Das Textfeld zeigt, da mit Obx umschlossen, immer den aktuellen Wert der Zählvariable im Controller an. Ein Druck auf den Button erhöht diesen Wert.
Außer der Zählvariable im Controller und der Funktion increment() hat die App keine weitere Funktionalität.
So funktioniert das dann in Bewegung:
Beachte auch, dass die Elemente wie die einer typischen Android-Anwendung aussehen. Das liegt schlicht daran, dass hier eine MaterialApp gestartet wird.
2. Temperaturconverter
Die zweite Aufgabe ist eine Oberfläche zum Unwandeln von Celsius zu Fahrenheit und umgekehrt.
So sieht meine Lösung aus:
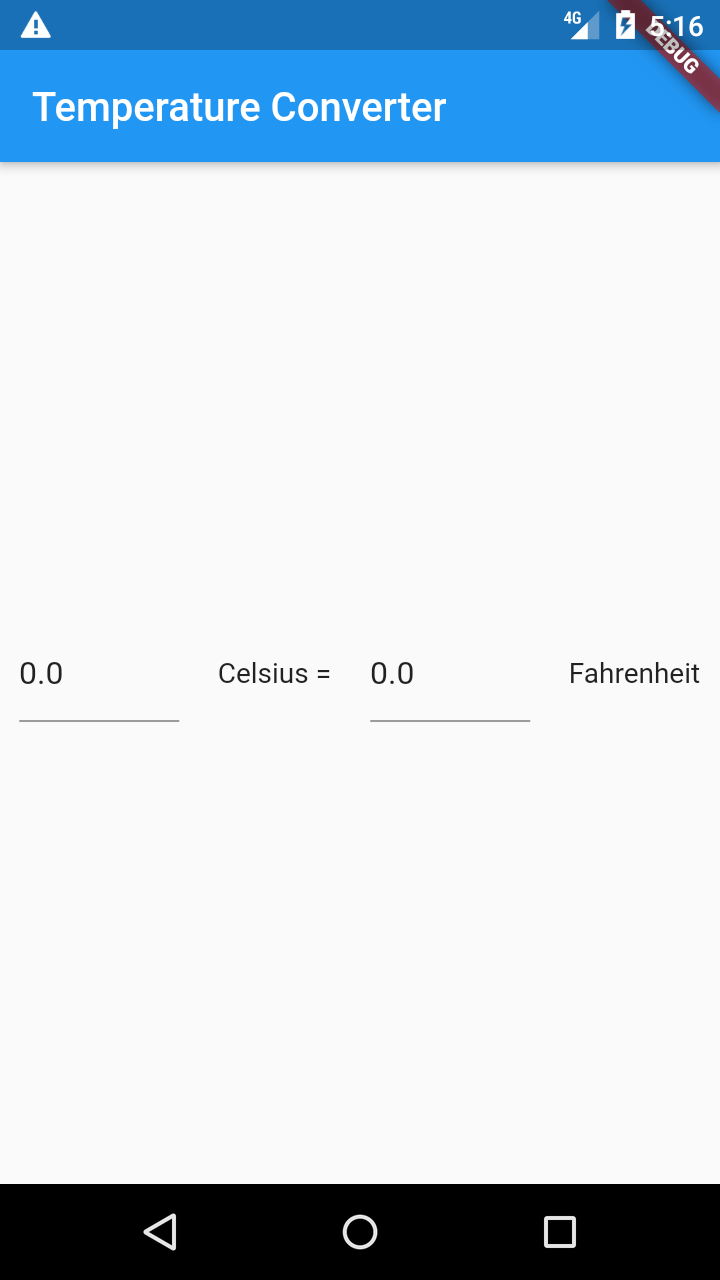
Das ist eine einzelne Row, in der nacheinander je ein Texteingabefeld und ein Textanzeigefeld aufgereiht sind. Und ja, 0.0 bei beiden Feldern war nicht der richtige Defaultwert, wäre aber einfach änderbar.
Der Code:
import 'package:flutter/material.dart';
import 'package:get/get.dart';
// ... main() und MyApp sind weggekürzt
class MyHomePage extends StatelessWidget {
final Controller c = Get.put(Controller());
@override
Widget build(context) => Scaffold(
appBar: AppBar(title: Text('Temperature Converter')),
body: Center(
child: Row(
mainAxisAlignment: MainAxisAlignment.spaceAround,
children: [
SizedBox(
width: 80,
child: Obx(() => TextFormField(
// to force Obx reload when value changes
key: Key("C" + c.celsius.string),
keyboardType: TextInputType.number,
initialValue: c.celsius.value.toStringAsFixed(1),
onChanged: (value) =>
c.fahrenheit.value = c.ctof(double.tryParse(value)),
))),
Text("Celsius ="),
SizedBox(
width: 80,
child: Obx(() => TextFormField(
key: Key("F" + c.fahrenheit.string),
keyboardType: TextInputType.number,
initialValue: c.fahrenheit.value.toStringAsFixed(1),
onChanged: (value) =>
c.celsius.value = c.ftoc(double.tryParse(value)),
))),
Text("Fahrenheit"),
],
),
));
}
class Controller extends GetxController {
var celsius = 0.0.obs;
var fahrenheit = 0.0.obs;
double ctof(double c) {
return c * (9 / 5) + 32;
}
double ftoc(double f) {
return (f - 32) * (5 / 9);
}
}
Hier passiert jetzt schon ein bisschen mehr. Der GetX-Controller hat zwei Variablen, celsius und fahrenheit, und zwei Funktionen zum Umwandeln der Werte. In der UI wird immer, wenn im Texteingabefeld etwas eingeben wird, mittels onChanged im Controller der Wert des anderen Texteingabefeld geändert. Weil die Eingabefelder wieder mit Obx umschlossen sind baut dann Flutter direkt die Oberfläche neu, mit dem neuen Celsius/Fahrenheit-Wert als initialValue der Eingabefelder. Einen key zu setzen hilft flutter bzw Obx dabei, zu erkennen wann die Oberfläche neu gebaut werden muss.
So sieht es in Bewegung aus:
Ich habe den Code auch auf Github hochgeladen, so kann jeder ihn direkt importieren und abändern. Es gibt noch fünf weitere Aufgaben, die immer komplizierter werden. Vielleicht mache eine Serie hierdraus, dann folgen sie später.
Flutter: Ein tolles Framework für mobile Apps
Monday, 19. October 2020
Flutter ist ein Framework zur Anwendungsentwicklung. Fokus sind Android und iOS-Apps, aber man kann stattdessen auch für das Web oder mittlerweile sogar den Desktop entwickeln. Es ist ein Google-Projekt, was aber nicht wirklich ein Nachteil ist wenn man mit Android sowieso für eine Google-Plattform entwickelt.
Das Framework ist schon wegen der Konzepte eine ziemliche Umstellung zur gewöhnlichen Android-Entwicklung, zusätzlich schreibt man die Anwendung dann auch noch in einer neuen Sprache, Dart. Doch Dart entpuppt sich als großer Vorteil, dazu unten mehr.
Flutter-Code und Konzepte
Flutter mag insgesamt eine große Umstellung sein, doch der Einstieg ist super simpel. Alles ist ein Widget, jede Oberfläche ist ein Widgetbaum, im Baum kombiniert man die Widgets frei. Zum Beispiel ist das hier das mitgelieferte Hello-World-Beispiel:
import 'package:flutter/widgets.dart';
void main() =>
runApp(
const Center(
child:
Text('Hello, world!',
key: Key('title'),
textDirection: TextDirection.ltr
)
)
);
So sieht das aus:

Auch als Anfänger ist das problemlos lesbar, die Elemente machen genau genau was man erwartet. main() ist der Startpunkt der Anwendung, runApp startet die App, das Center-Widget zentriert, Text zeigt Text an. Würde man den Code in eine Material-App packen, würde die App auch direkt aussehen wie eine typische Android-Anwendung.
Aber es ist purer Code, während man bei der Entwicklung mit Android-Studio Oberflächen mit XML-Layouts zusammenbauen konnte. Die Trennung nicht zu haben birgt die Gefahr, UI-Code und Programmlogik zu verschmelzen – was ja aber auch bei regulären Androidanwendungen nur zu schnell passiert. Flutter, und mehr noch die Community drumrum, kompensiert diesen Nachteil über mit einem exzessiven Fokus auf Zustandsmanagement.
Zustandmanagement
Zustandsmanagement ist die Verwaltung des States, das sind einfach die lokalen und globalen Variablen, die Einfluss auf die Oberfläche haben. Flutter versucht generell eine deklarative UI-Entwicklung vorzugeben: Die UI wird immer wieder neu gezeichnet, und wenn der Zustand sich verändert hat sieht die Oberfläche entsprechend anders aus.
Zuerst aber gibt es StatelessWidgets, die keinen eigenen Zustand haben. Holen sie sich die Variablen nicht von außen sehen sie immer gleich aus.
class GreenFrog extends StatelessWidget {
const GreenFrog({ Key key }) : super(key: key);
@override
Widget build(BuildContext context) {
return Container(color: const Color(0xFF2DBD3A));
}
}
Das hier wäre einfach ein grünes Fenster.
Dann gibt es StatefulWidgets, die ihre eigenen änderbaren Variablen haben können.
class YellowBird extends StatefulWidget {
const YellowBird({ Key key }) : super(key: key);
@override
_YellowBirdState createState() => _YellowBirdState();
}
class _YellowBirdState extends State<YellowBird> {
@override
Widget build(BuildContext context) {
return Container(color: const Color(0xFFFFE306));
}
}
Das zeigt jetzt auch nur einen farbigen Bereich an. Aber der State-Klasse könnte man jetzt Variablen hinzufügen. Die Doku zeigt dieses Beispiel:
class Bird extends StatefulWidget {
const Bird({
Key key,
this.color = const Color(0xFFFFE306),
this.child,
}) : super(key: key);
final Color color;
final Widget child;
_BirdState createState() => _BirdState();
}
class _BirdState extends State<Bird> {
double _size = 1.0;
void grow() {
setState(() { _size += 0.1; });
}
@override
Widget build(BuildContext context) {
return Container(
color: widget.color,
transform: Matrix4.diagonal3Values(_size, _size, 1.0),
child: widget.child,
);
}
}
Das ist also ein Widget mit einer festen Größe, das eine Funktion mitbringt um zu wachsen. setState(() { }); muss immer dann aufgerufen werden, wenn die Oberfläche die Zustandsvariablen neu evaluieren soll.
GetX

Es gibt Unmengen Lösungsansätze für die Zustandsverwaltung. Zum einen weil sie wichtig ist, denn mit ihr steuert man ja direkt das Verhalten der App. Aber auch, weil da die Einflüsse der Entwicklergruppen kollidieren: Da kommt das übliche mentale Chaos aus dem Javascript-Land angeschwemmt, vermischt mit Enterprise-Architekturen – passt ja zu einem Google-Framework. GetX ist anders. Es ist ein pragmatisches Werkzeugset, das nur unter anderem Statemanagment löst. Mit dem Flutter-Modul kann man jeder Oberfläche einen Controller zur Seite stellen, und mit dem Obx-Widget die Oberfläche immer neu zeichnen lassen wenn sich eine der Variablen ändert. Im Flutter-Kontext ist das Magie, das Resultat ist einfach sauberer Code. So ist das Counter-Beispiel aus der Readme elegant und verständlich:
Du hast einen Controller, in der die Variable und eine optionale Manipulierfunktion definiert wird:
class Controller extends GetxController{
var count = 0.obs;
increment() => count++;
}
Und dazu das Widget, bei dem ein Druck auf den Button die Variable erhöht, wodurch direkt die Anzeige aktualisiert wird:
class Home extends StatelessWidget {
// Instantiate your class using Get.put() to make it available for all "child" routes there.
final Controller c = Get.put(Controller());
@override
Widget build(context) => Scaffold(
// Use Obx(()=> to update Text() whenever count is changed.
appBar: AppBar(title: Obx(() => Text("Clicks: ${c.count}"))),
// Replace the 8 lines Navigator.push by a simple Get.to(). You don't need context
body: Center(child: RaisedButton(
child: Text("Go to Other"), onPressed: () => Get.to(Other()))),
floatingActionButton:
FloatingActionButton(child: Icon(Icons.add), onPressed: c.increment));
}
class Other extends StatelessWidget {
// You can ask Get to find a Controller that is being used by another page and redirect you to it.
final Controller c = Get.find();
@override
Widget build(context){
// Access the updated count variable
return Scaffold(body: Center(child: Text("${c.count}")));
}
}
Das Beispiel zeigt noch zusätzlich die Navigationslösung, die man nicht nutzen muss. Trotzdem: Klarer geht es nicht.
GetX hat Nachteile. So sind die Details nicht ganz so simpel wie es zuerst scheint - wie zum Beispiel umsetzen, dass auf eine Objektvariable eines Listenelements reagiert wird, wenn doch List.obs nur auf das Vergrößern und Verkleinern der Liste reagiert? Vor allem aber ist es ein junges Projekt, bei dem noch zu viele Commits hereinkommen, von zu wenigen Entwicklern, das Ding ist noch im Flux. Trotzdem ist es ein supermächtiges Werkzeug und erleichtert die Arbeit mit Flutter deutlich.
Paketverwaltung
Richtig nett an Flutter ist auch das darum aufgebaute Entwickleruniversum. Man findet Erklärvideos und -artikel. Am wichtigsten aber sind die Pakete. Auf https://pub.dev/ gibt es eine Suche, Module (für Flutter wie Dart) werden dort sauber vorgestellt, gewonnene Likes dienen als Orientierungshilfe. Bräuchte meine App beispielsweise eine animierbare Navigationszeile unten, ich könnte sie mit convex_bottom_bar direkt von dort beziehen. Eintragen in die pubspec.yaml, flutter pub get ausführen, den Code einbauen, fertig. Eine solche Paketübersicht habe ich bei der direkten Androidentwicklung mit Java schmerzlich vermisst.
Dart
Dass Flutter direkt eine neue Programmiersprache erfordert ist erstmal total abschreckend. Doch Dart macht das ganz schnell wieder wett, denn die Sprache ist gelungen. Dart ist eine wilde Mischung, für mich fühlt es sich aber vor allem nach Ruby an. Was toll ist. Es fehlen allerdings die Blöcke. Dafür hat es async-Funktionen direkt mit dabei, samt await und Future. Wikipedia zählt Smalltalk und Erlang als weitere Einflüsse. Bestimmt ist da auch Python mit drin, Java und Javascript.
Dart hat mich bisher noch in keiner Situation enttäuscht. Die Sprache hat für mich als Ruby-Programmierer immer eine gute Lösung parat gehabt und mich seltenst negativ überrascht.

Die folgenden Beispiele kann man auch alle auf der Webseite ausprobieren.
Hallo-Welt:
main() {
print("Hello, World!");
}
Zahlen:
int i = 1 + 2; print(i); // => 3
Strings:
final s = "abc" + "def"; print(s); // => abcdef
Es gibt Listen und Maps (Hashes):
var testliste = [1, 2, 3];
print(testliste[1]); // => 2
var testmap = {1: 'a', 2: 'b', 3: 'c'};
print(testmap[2]); // => b
Und map und fold:
var testliste = [1, 2, 3]; var result = testliste.map((element) => [element]); print(result); // => [[1], [2], [3]] var folded = result.fold(0, (prev, element) => prev + element.first); print(folded); // => 6
Dr ganze Bereich um async war ungewohnt und ist nicht einfach, aber das simple Beispiel ist klar:
Future<void> fetchUserOrder() {
// Imagine that this function is fetching user info from another service or database.
return Future.delayed(Duration(seconds: 2), () => print('Das hier folgt 2 Sekunden später'));
}
void main() {
fetchUserOrder();
print('Das ist die erste Ausgabe.');
}
Und natürlich Objekte mit Funktionen:
class Sword {
int damage = 5;
use() => print("$this dealt $damage damage.");
}
main() {
var sword = Sword();
sword.use(); // => Instance of 'Sword' dealt 5 damage.
}
Dazu kommt noch viel mehr: Generic, Mixins, Named Parameters, Lambda hatte ich erwähnt, die Standardklassen haben hilfreiche Funktionen definiert, chaining mittels .. – also das Aneinanderreihen von Funktionen an ein Objekt, obwohl die Funktionen eigentlich void zurückgeben. Dart ist wirklich erstaunlich angenehm.
Und die Flutter-Programme, die mit Dart gebaut werden, laufen nicht etwa in einem Wrapper, sondern werden kompiliert und dann nativ auf dem Gerät ausgeführt. Dart kann auch nach Javascript transpilieren, was dann die Web-Unterstützung von Flutter erlaubt, aber das ist gefährlich – die so erstellten Webseiten sind bestimmt Javascript-Monster. Für einzelne Spezialfälle könnte aber auch das eine gute Lösung sein.
Fazit: Beachtenswert
Flutter verspricht, mobile Anwendungen viel schneller entwickelbar zu machen als wenn man sie mit den Bordmitteln schreibt. Wenn man das Framework bereits beherrscht mag das stimmen. Ist man neu, ist es mit der Fixierung auf indirekte Interaktivität nicht so einfach zu beherrschen und dieser Lernprozess dann auch nicht schnell. Aber: Dann ist es mächtig, und ich habe definitiv den Eindruck, dass man hiermit bessere Oberflächen und somit auch Apps bauen kann. Dass die dann auf beiden großen mobilen Betriebssystemen laufen können kommt noch dazu.
Dart ist dann die Krönung. Erwartet hatte ich ein alternatives Javascript – etwas, womit man arbeiten kann, aber woran man eher keine Freude hat. Stattdessen ist es nahe genug an Ruby und so ausgereift, dass ich fast frei meinen Programmcode schreiben kann. Sicher, mit der Zeit werden sich die Schwachstellen offenbaren, und eine so junge Sprache kann nicht an die Modulvielfalt von Ruby herankommen. Eine positive Überraschung war sie aber allemal.
Wenn Flutter die entsprechende Entwicklung stabilisiert (noch ist es alpha) könnte ich mir das glatt auch für Linuxanwendungen vorstellen. Die Entwicklung mit wxWidgets, GTK und Qt ist deutlich komplizierter. Derzeit greifen Entwickler dann stattdessen oft zu Electron und anderen Javascript-Desktopwrappern. Flutter mit Dart könnte die bessere Lösung sein. Ich bin gespannt, ob sich das bewahrheitet. Derzeit hat sich die Alpha an snap gekoppelt, was komplett inakzeptabel ist solange es die einzige Lösung bleibt. Aber Flutter-Appimages oder schlicht Binaries? Könnten eine tolle Sache sein.
Wer jetzt für Android entwickeln will, für den ist Flutter mit Dart auch jetzt schon einen Versuch wert.
Dark Mode mit CSS
Monday, 15. June 2020
Selten, dass ich ein Feature umsetze das unter Linux nicht richtig funktioniert. Aber der dunkle Systemmodus der anderen Betriebssysteme ist eine gute Idee. Besonders, wenn Webseiten den Systemzustand erkennen und sich ebenfalls abdunkeln können.
Ergebnis
Ich habe das auf pc-kombo umgesetzt. So sah die Seite vorher immer aus:

So sieht sie jetzt bei aktiviertem Dark Mode aus:
Nicht schlecht, oder?
Aktivieren
Im Firefox setzt man in about:config ui.systemUsesDarkTheme auf 1. In Chromium gibt es in den Einstellungen der Entwicklerwerkzeuge die Option Emulate CSS media feature prefers-color-scheme. Unter Windows würde ich erwarten, dass die Browser automatisch die Systemeinstellungen aufgreifen.
Die Webseite reagiert mit einem Mediaquery:
@media (prefers-color-scheme: dark) {
…
}
Außerhalb des CSS bleibt alles gleich.
Die Änderungen und ein paar Tricks
Am Ende der CSS-Datei angehängt überschrieb ich nun die CSS-Anweisungen, die der Webseite vorher ein helles Aussehen gaben. Manche davon kamen von mir, andere vom genutzten CSS-Framework Spectre. Ich stolperte dabei über ein paar nette Tricks.
Farben
Klar: Wenn vorher ein weißer Hintergrund gesetzt war musste der abgeändert werden. Normalerweise ist der Standardhintergrund hell und die Schrift dunkel:
body {
background-color: #fbfbfb;
color: #3b4351;
}
Nun ist das umgedreht:
body {
color: #dcdfe5;
background-color: #37383a;
}
Aber es ist nicht einfach weiß auf schwarz, so wie es ja auch vorher nicht einfach schwarz auf weiß war. Stattdessen ist es ein helles grau auf einem dunkleren grau. Der Kontrast ist hoch genug, und anders als bei einer rein schwarz-weißen Seite kann immer noch mit Farben gearbeitet werden. So ist pc-kombo weiterhin auch blau.
Es gab noch ein paar Farbanweisungen mehr zu setzen, aber es waren nicht viele und sie folgten dem gleichen Prinzip. Grau oder blau, abgedunkelte Versionen der vorher bereits genutzten Farben. An ein paar Stellen bewahrte ich auch die vorher genutzten blau-lilanen Hintergründe.
Bilder abdunkeln
Viele Produktbilder haben einen hellen Hintergrund und sind nicht von mir bearbeitbar, aber auch meine Bilder will ich nicht alle bearbeiten. Zum Glück kann CSS hier helfen:
img {
opacity: .75;
transition: opacity .5s ease-in-out;
}
img:hover {
opacity: 1;
}
Indem die Sichtbarkeit verringert wird werden die Bilder weniger hell, denn sie sind ja jetzt auf einem dunklen Hintergrund. Die Idee stammt aus diesem Artikel.
Bildern Hintergrund geben
Andererseits waren Bilder mit einem transparentem Hintergrund und dunklem Bildinhalt nun schwer sichtbar, das Amazon-Logo zum Beispiel. Solche Bilder bekommen mit CSS einen hellen Hintergrund zugewiesen (der wegen dem obigen Schritt nicht zu hell wird), durch etwas Padding wirken sie nicht abgeschnitten, und ein kaum sichtbarer schwarzer Rahmen verbessert nochmal die Abgrenzung:
#priceDetails img, #recommendation img:not([src=""]) {
padding: 0.2em;
background: white;
border: 2px solid black;
}
Das not([src=""]) verhindert, dass vorher unsichtbare leere Bilder jetzt durch Rahmen und Padding sichtbar werden.
Logo und Charts invertieren
Das Logo von PC-Kombo war nun dunkelgrau auf dunkelgrau, also nicht sichtbar. Und bei den Charts waren die schwarzen Linien und Bezeichnungen unsichtbar geworden. Hier hilft ein CSS-Filter:
.navbar-brand img, .apexcharts-canvas {
filter: invert();
opacity: 1;
}
Die invertierten dunklen Farben sind jetzt gut sichtbar, die hellen bleiben sichtbar.
Inputs einfärben
Da die inputs noch hell waren, mussten auch die angepasst werden. Mein CSS bezieht sich hier speziell auf Spectre:
.form-input, .input-group .input-group-addon {
border: .05rem solid #5e6b80;
}
.form-input, .input-group .input-group-addon {
background: #21325a;
color: #b7becb;
}
.form-input:focus, .form-input:not(:placeholder-shown):invalid:focus {
background: #0F1930;
}
.form-select:not([multiple]):not([size]) {
background: #21325a url("data:image/svg+xml;charset=utf8,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%204%205'%3E%3Cpath%20fill='%23667189'%20d='M2%200L0%202h4zm0%205L0%203h4z'/%3E%3C/svg%3E") no-repeat right .35rem center/.4rem .5rem
}
Grundsätzlich müssten sie aber auch geändert werden, wenn kein CSS-Framework ihnen bereits einen hellen Hintergrund und Grenzlinien gegeben hätte. Zumindest, solange auf Linux nicht auch diese Elemente automatisch abgedunkelt werden.
Bei der Nummerneingabe waren die Hoch-Runter-Buttons weiterhin hell und ließen sich nicht abändern. Also blendete ich sie aus:
input[type=number] {
-moz-appearance: textfield;
appearance: textfield;
margin: 0;
}
input[type=number]::-webkit-inner-spin-button {
-webkit-appearance: none;
}
Die Buttons sind zwar eigentlich nett, aber das ganze Design zu zerstören sind sie nicht wert.
Einfacher als gedacht, aber Linux muss nachziehen
Ich war überrascht über den geringen Aufwand. Klar, es ist Designarbeit und jede Seite ist anders. Aber dank tollen Funktionen von CSS wie dem Farbfilter waren ansonsten problematische Ecken einfach zu lösen. Wenn das CSS einer Seite halbwegs organisiert ist oder Farben gar zentral definiert sind ist das Abdunkeln machbar.
Allerdings ärgerlich, dass Linux keinen definierten Mechanismus hat um den Dunkelmodus zu aktivieren. Es müsste eine Datei ~/.config/darkmode geben, die von Anwendungen und QT/GTK-Designs berücksichtigt wird. Klar kann man auch so ein dunkles Design auswählen, aber das weiß der Browserinhalt dann ja nicht.
Hier im Blog könnte ich jetzt ebenfalls relativ schnell ein dunkles Design anbieten, aber ich glaube ich warte damit bis Linux für den Dunkelmodus einen ordentlichen Mechanismus hat, oder bis die Browser die Einstellung regulär konfigurierbar machen.
Victor: SVGs mit Ruby erstellen
Friday, 15. May 2020
Vom Code aus Bilder erstellen – da landet man dann schnell bei SVG. Um unter Ruby ein SVG zu erstellen kann victor benutzt werden. Das Readme zeigt direkt wie es geht. Dieser Code:
require 'victor'
svg = Victor::SVG.new width: 140, height: 100, style: { background: '#ddd' }
svg.build do
rect x: 10, y: 10, width: 120, height: 80, rx: 10, fill: '#666'
circle cx: 50, cy: 50, r: 30, fill: 'yellow'
circle cx: 58, cy: 32, r: 4, fill: 'black'
polygon points: %w[45,50 80,30 80,70], fill: '#666'
3.times do |i|
x = 80 + i*18
circle cx: x, cy: 50, r: 4, fill: 'yellow'
end
end
svg.save 'pacman'
erstellt diese Grafik:

Cool: Der Code hinter dem gem ist ziemlich minimal, das ist fast nur eine intelligent gestrickte kleine API, die genau richtig den Funken Komplexität versteckt, wegen dem man SVGs anonsten nicht per Hand schreiben will. Samt hilfreichen Beispielen wird es ein praktisches Werkzeug.
Ich finde es toll, wie SVG immer wieder in Projekte von mir reinrutscht. Nicht, weil es bei mir besonders beliebt wäre, sondern schlicht weil es immer wieder gut ein Problem löst.

