Kühl - Schattenorganisation
Monday, 15. January 2024
 Agiles Management und ungewollte Bürokratisierung - mit diesem Untertitel hatte mich Schattenorganisation gepackt. Denn ich war entsetzt darüber und ziemlich ratlos, wie starr und insgesamt negativ Scrum im neuen Entwicklerteam der Käuferfirma umgesetzt wurde, während meine Firma die Methodik zuvor so positiv genutzt hatte. "Ungewollte Bürokratisierung" schien mir dabei genau das Problem zu beschreiben.
Agiles Management und ungewollte Bürokratisierung - mit diesem Untertitel hatte mich Schattenorganisation gepackt. Denn ich war entsetzt darüber und ziemlich ratlos, wie starr und insgesamt negativ Scrum im neuen Entwicklerteam der Käuferfirma umgesetzt wurde, während meine Firma die Methodik zuvor so positiv genutzt hatte. "Ungewollte Bürokratisierung" schien mir dabei genau das Problem zu beschreiben.
Schattenorganisation aber spricht zu diesem Thema nur indirekt. Statt Scrum, Kanban oder anderen gängigen Praktiken in Entwicklerteams wird über die mir vorab völlig unbekannte Holokratie berichtet. Das ist eine Organisationsform für gesamte Organisationen, bei der softwareunterstützt haarklein aufgeschrieben wird welche Rollen es gibt und wie sie arbeiten, daraufhin Arbeiter gerne auch mehreren Rollen zugeordnet werden und das ganze in Kreisen von Rollen organisiert wird, bei denen es keinen klaren Chef gibt. Bilden sich Abweichungen zu den niedergeschrieben Arbeitswegen, sollen diese direkt formal aufgeschrieben werden, die Rollenbeschreibungen, welche Rollen es gibt und wer sie besetzt ändere sich dadurch ständig. Nie wirklich groß, war es wohl doch in entsprechenden Kreisen eine Mode und ein paar Firmen, die man kennt, hatten versucht sich so zu organisieren, beispielsweise Medium.
Kühl zerlegt dieses Konzept in seine Einzelteile. Durch seine Einordnung in organisationswissenschaftliche Modelle und seine Aufarbeitung, wie diese Methode am Ende wirklich gelebt wird (nicht, die informelle Ebene bildet sich immer wieder), blieb von der Holokratie am Ende zumindest bei mir kein positives Bild über. Kühl selbst positioniert sich nicht klar zu dem Konzept, dass diese Wahrnehmung nicht unbeabsichtigt ist kann ich nur mutmaßen.
Für Scrum etc gab mir Schattenorganisation keine klare Antworten, aber am Ende doch ein paar Ideen. Wenn Holokratie durch eine maßlose, detaillierte Bürokratisierung Agilität herstellen will, ist das bei Scrum mit seinen Ritualen und festen Rollen gar nicht sehr anders. Die vermeintliche agile Softwareentwicklung nach Scrum wäre also – so ausgestaltet, wie ich es erlebte – in Wirklichkeit eine stark formalisierte, eben bürokratische Methode; und eben nicht die Annäherung an die "natürliche" Entwicklungsform, die FOSS-Projekte und entwicklerbestimmte Teams ohne formalisierenden Manager im Rücken wählen würden. Und wie es dazu kommen konnte, wie auch dieser Gedankengang von Agilität durch Bürokratie bzw Formalisierung funktioniert, dafür gibt der Blick auf die Holokratie dann eben doch ein paar Einblicke.
Schattenorganisation zu lesen war also keine totale Zeitverschwendung. Angesichts meiner Fragen hätte ich aber zu einem anderen Buch greifen sollen. Ich finde es schade, dass Kühl nicht über die eine Erwähnung im Nebensatz hinaus im Buch selbst den Bogen geschlagen hat, war Holokratie doch auf dem Klappentext nichtmal erwähnt und sind Scrum sowie Kanban die Arbeitsweisen, an die das Stichwort agil direkt denken lässt. Aber vielleicht stimmt das außerhalb meiner Nische eben nicht, oder war das relevante Stichwort hier eben Management, nicht alleine agil.
Mein Rückblick aufs Studium, Teil 1: Bachelor Informatik TU Darmstadt
Monday, 27. September 2021
![]() Ich habe viel Zeit an der Uni verbracht, darüber aber hier nur selten geschrieben. Mittlerweile arbeite ich seit ein paar Jahren und das Studium wird mehr und mehr eine ferne Erinnerung. Zeit, ein paar Erfahrungen festzuhalten.
Ich habe viel Zeit an der Uni verbracht, darüber aber hier nur selten geschrieben. Mittlerweile arbeite ich seit ein paar Jahren und das Studium wird mehr und mehr eine ferne Erinnerung. Zeit, ein paar Erfahrungen festzuhalten.
Der Start war ein Informatikstudium an der TU Darmstadt, das ich vor fast genau einer Dekade abgeschlossen habe. Es war nur ein Bachelorstudium, den Master machte ich anderswo. Die Rahmenbedingungen waren gut: Die TU galt als gute Uni. Auch wenn es noch Diplomstudenten gab – einer davon wurde unser D&D-Dungeonmaster – war der Umstieg vom Diplomsystem mittlerweile fertig, es gab auch keine Wahl mehr, das schuf Fakten und Klarheit. Unsicherheit kam von den asozialen Studiengebühren, doch die wurden mir im ersten Semester erlassen und im zweiten dank Ypsilanti ganz abgeschafft. Das Studium selbst war von Seiten der Universität ziemlich toll organisiert, aber es war viel Arbeit und die Zeit insgesamt für mich ziemlich chaotisch.
Der Ablauf des Studiums
Da es keine Zulassungsbeschränkung gab saß ich am Anfang des Studiums mit sehr vielen anderen neuen Studenten in völlig überfüllten Hörsälen. Am schlimmsten war da Mathe 1, da passten die Leute nichtmal mehr auf die Stufen neben den Stühlen. Das blieb natürlich nicht so: Es würde mich sehr wundern, wenn mehr als 50% das Studium abgeschlossen haben, zudem sparten sich bald selbst viele die weitermachten die Vorlesungen.
Die Übungen waren sowieso wichtiger: In ihnen kam der Stoff vor, der dann in den Prüfungen getestet wurde. Geleitet wurden diese Übungen meist von Studenten, als Nebenjob. Alle meine Prüfungen waren schriftlich, mündliche Prüfungen gab es in anderen Kursen, aber sie waren selten und galten als schwierig. Bei allen regulären Vorlesungen gab es am Ende stattdessen eine schriftliche Prüfung. Ohne irgendeinen Tests an Scheine zu kommen war mit dem Diplomsystem so ziemlich abgeschafft worden, ging aber noch in Seminaren – da wurde dann eine Präsentation bewertet. Das war natürlich der große Stressfaktor: Dass man durch Prüfungen und nach dreimaligen Scheitern an einer Prüfung sogar durch das ganze Studium durchfallen konnte. Zum Glück blieb mir der Drittversuch erspart, aber nicht alle Prüfungen konnte ich auf Anhieb bestehen. Auch deswegen war es die oben erwähnte chaotische Zeit.
Die Massenvorlesungen am Anfang deckten die Grundthemen ab. Grundlagen der Informatik (GDI), Formale Grundlagen der Informatik (FGDI), Technische Grundlagen der Informatik (TGDI), Mathe. Davon gab es jeweils drei Kurse, nur TGDI blieb bei zweien. Nach den ersten Semestern kamen dann Kanonikfächer hinzu, "Einführung in X" – Computational Engineering, Computer Microsystems, Foundations of Computing, Human Computer Systems, Data and Knowledge Engineering und Net Centric Systems.
Gegen Ende gab es noch Wahlpflichtfächer, wo man sich aus einer Auswahl von Themen die seinen raussuchen konnte, das war die minimale Spezialisierungsmöglichkeit. Bei mir wurde das Kryptographie, Mensch-Computer-Interaktion (HCI) und Künstliche Intelligenz. Man musste ein Bachelorpraktikum abliefern, aber was da die Optionen waren krieg ich nicht mehr zusammen. War das mit der Bachelorarbeit kombiniert? Denn die galt es ganz zuletzt zu schreiben, wobei man dafür noch einen Kurs besuchen konnte und dann mit Kommilitonen den Fortschritt besprach, was sehr hilfreich war.
Studiumsinhalte
Worum ging es jeweils? Ich werde nicht alles durchgehen, will aber einen Eindruck der wichtigsten Inhalte geben.
In GDI ging es ums Bauen von Software. Am Anfang schlicht ums Programmieren: Wir lernten erst Scheme (jetzt Racket, ein LISP), dann Java, programmierten zusammen ein Spiel und lernten über die Komplexität von Algorithmen (O-Notation). Und das war alles GDI 1. An spätere Inhalte erinnere ich mich weniger gut. Ein kurzer Abschnitt wurde in C programmiert. Aber wir müssen auch Stoff über Wasserfallmodelle, Pflichtenhefte, Designpatterns und UML gehört haben – das meiste davon war anders als die erste Vorlesung im Nachhinein irrelevant, aber gut zu wissen dass es das mal gab. Spezielle Algorithmen wie Quicksort kamen später auch vor, das war schon hilfreicher, auch Datenstrukturen wie Bäume waren ein wichtiges und nützliches Thema.
FGDI war Logik. Meine Anleitungen um einen Zustandsautomaten zu mimieren und zum Markierungsalgorithmus stammen daher, ob das nun FGDI 1 oder 2 war ist mir unklar. Anfangs ging es um Grundlagen wie Prädikatenlogik. Ich habe es gehasst, die Artikel landeten im Blog um mir Inhalte ins Hirn zu prügeln und anderen zu helfen. Ich muss aber zugeben, dass es später hilfreich und notwendig war solche formalen Logikausdrücke lesen zu können. FGDI 3 war etwas anders: Da ging es um die Verifikation von Programmen. Die wurden dafür in einer Spezialsprache geschrieben und ihre Richtigkeit musste dann Annahme für Annahme bewiesen werden. Auf der einen Seite absurd komplett nicht praxistauglich, auf der anderen konnte man sich vorstellen, wie das irgendwann doch praxistauglich werden könnte, es hieß sogar Prozessorhersteller würden das bereits machen (und später las ich, sie hätten das größtenteils aufgegeben).
TGDI hasste ich nicht, aber diese technischen Grundlagen hatte ich nie gehabt. Und-, Oder-, XOR-Schaltungen, Verilog und damit irgendwas anfangen – ich schnappte ein paar Grundlagen auf und kam durch die Prüfung. Im zweiten Kurs ging es dann mehr um Prozessorarchitekturen. Ob wir hier oder in GDI in Assembler programmiert haben krieg ich nicht mehr zusammen, aber das war auf jeden Fall spaßig.
Bei Mathe kann ich kaum noch auch nur die Inhalt benennen. Mathe 1 und 2 war ein wilder Mischmasch von irgendwelchen Mathematikkenntnissen – irgendwas mit Reihen, Ableitungen, Beweisen. Mathe 3 war Computation (und Statistik?), also Mathematik vom Computer lösen lassen, was oft andere Ansätze braucht. Das hatte etwas Berechtigung. Aber Mathematik wie es dort zuvor gemacht wurde war ein pures Aussiebefach und vermittelte wenig, was irgendwie hängenblieb oder ich bisher nochmal gebraucht hätte. Teilweise wiederholten sich Inhalte in den spezialisierteren Fächern, die waren dann relevant und gut sie schonmal gehört zu haben, Gruppen beispielsweise. Aber hätte es kein Siebfach gebraucht hätte man Mathe schlicht weglassen und die Inhalte dort lehren können wo sie benutzt wurden.
Bei den "Einführung in X"-Fächern ging es um ganz verschiedene Themen. Bis jetzt lernten wir ja nur allgemeine Grundlagen. Net Centric Systems z.B. konnte dann über Netzwerke und über das Internet reden. Es ging auch darum grob die Forschungsbereiche der Informatik abbilden. Die Wahlpflichtfächer gingen da dann später etwas tiefer, für die, die Interesse an einem bestimmten Thema hatten.
Besondere Inhalte und Lektionen

Besonders prägend war Grundlagen der Informatik. Wegen dem Fach mit seinen Inhalten waren die meisten Studenten in dem Studiengang, mich eingeschlossen. Tatsächlich lernte man dort dann auch viele Konzepte, die für jeden Programmierer völlig relevant sind: Objektorientierte und funktionale Programmierung, Datentypen, Rekursion, Komplexität, aber auch generell das Entwerfen von und Arbeiten mit Algorithmen sowie das Planen von Programmen.
Trotz diesem praktischen Aspekt des Studiums wurde gepredigt, dass ein Informatiker Konzepte lernt und die dann in jeder beliebigen Programmiersprache anwenden kann. Ich merkte später: Das stimmt nur so halb. Um abstrakte Konzepte wirklich anzuwenden muss man die Sprache beherrschen, das braucht Übung mit ihr. Bevor ich Ruby lernte – eigenständig im Master – konnte ich zum Beispiel faktisch kaum Serveranwendungen bauen, völlig egal ob ich die Konzepte drauf hatte. Aber es stimmt, dass sich viel übertragen lässt, und zwischen ähnlichen Sprachen zu wechseln ist kein großes Problem. Es stimmt aber auch der Vorwurf am Hochschulstudium, dass selbst das Bachelorstudium noch zu abstrakt ist um den Studenten wirklich das Programmieren beizubringen. Das müssen sie aus eigenem Antrieb zusätzlich oder später machen, selbst GDI mit seinem Praxisteil schafft nur wenige Grundlagen. Oder zumindest war das damals so.
Was stimmte: Die Predigt vom Dekan ziemlich am Anfang des Studiums, dass er keinen von uns in gewöhnlichen Studentenjobs sehen will, wir seien alle jetzt schon als Programmierer beschäftigbar. Naja, vielleicht galt das nicht für alle, aber tatsächlich waren die Anfangsinhalte die wichtigsten und Firmen hätte mit den motivierteren Studenten definitiv arbeiten können.
Wieviel weiteres nützliches man aus dem Studium ziehen konnte hing aber auch von den Wahlpflichtfächern ab. Meine Themenwahl sehe ich heute noch mit Wohlwollen.
Künstliche Intelligenz war vor dem aktuellen Boom, neuronale Netze ein veraltetes Nischenthema. Trotzdem oder gerade deswegen war die Vorlesung super – denn KI hat im Kern das Thema, das mich an Informatik anfangs so faszinierte, nämlich wie man mit Algorithmen Probleme lösen kann. Der auf einem Infotag präsentierte Dijkstra-Algorithmus, der ein Wegfindeproblem lösen kann, hatte damals erst den Ausschlag gegeben dieses Studium zu wählen. Ich sehe KI als die komprimierte Essenz der Informatik, entsprechend spannend war die Vorlesung. Wobei ich wenig konkrete Inhalte aus ihr bisher anwenden konnte, wohl aber viele Ansätze.
Kryptographie zu belegen war überraschend lohnenswert, weil IT-Sicherheit in jedem Projekt ein Thema ist und die Grundlagen von damals mich immer noch tragen. Zudem war der Professor Johannes Buchmann, der es einfach drauf hatte die Vorlesung interessant und verständlich zu halten. Ich glaube, das war auch die Vorlesung für die ich RSA in Bash implementierte, was ein bisschen zeigt wie locker man das Thema angehen konnte.
Außerdem war HCI ein prägender Kurs zu Usability. Als Informatiker fand ich das besonders toll, weil es einen Weg vorwärts versprach wie man alles andere anwenden konnte. Nicht nur viel wissen, sondern auch herausfinden können was man überhaupt bauen soll und womit Nutzer umgehen können. Damit wollte ich weitermachen, also wurde das Thema mein Masterstudium – was nicht ganz klappte, aber dazu später mal mehr.
Und schließlich, etwas allgemeiner: Diese übliche Prophezeiung, dass im Studium viele gute Leute zusammenkommen und die dann auch oft besser sind als du, in Darmstadt stimmte das für mich. Auch eine Erfahrung.
Leben als Student in Darmstadt

Nach etwas Eingewöhnungszeit wurde das Studieren zum Alltag. Ich besuchte die Vorlesungen fast immer, nahm an den Übungen teil, und füllte die verbliebene Zeit mit anderen Dingen.
Am Anfang hatte ich keine Zeit über, denn anfangs bin ich von meinem Heimatort nach Darmstadt gependelt, was großer Mist war. Dass ich seitdem mit einer kurzen Ausnahme nie wieder gependelt bin ist kein Zufall. Erstens kriegte ich anfangs vom Studentenleben wenig mit, zweitens fühlte ich mich wegen der unsicheren Heimreise in Darmstadt nicht wohl, drittens schadete es der Motivation an den Vorlesungen und Übungen teilzunehmen und damit dem Studium. Gerade kommt mir der Gedanke: Man konnte beides damals nicht von Zuhause machen, vielleicht ginge zumindest die fachliche Seite mittlerweile trotz der Distanz etwas besser?
Später wohnte ich im Studentenheim, das half sehr. Es gab dort aber die absurde Situation, pfeilschnelles Internet zu haben, aber nur 10 oder 20 GB Traffic, danach wurde die Leitung für den Monat abgeschaltet. Ich hoffe, das ist heute Geschichte – ah, sie sind jetzt bei 120GB, das sind immer noch nur 2 AAA-Spiele. Peinlich. Und es half anfangs nicht gerade beim Sicherheitsgefühl in der neuen Heimat.
Studentenjobs an der Uni dagegen waren eine gute Sache für mich. Eine Weile war ich Mentor für Erstsemester, ihr einer Pflichttermin. Diese Tätigkeit hatte abgesehen der üblichen Anliegen der Menties bezüglich mancher Studieninhalte so gar nichts mit Informatik zu tun, das war eine interessante Erfahrung. Später als Tutor in Übungen lernte ich immerhin noch, wie schwer diese Rolle ist und wieviel man von dem Stoff auch wieder vergessen hat.
In meiner Freizeit verbrachte ich als Informatiker viel Zeit vor dem Rechner, klar. Von Darmstadt habe ich nicht viel mitbekommen, um in Cafes rumzusitzen zum Beispiel hätte mir auch schlicht das Geld gefehlt. Aber so ein bisschen Studentenleben nahm ich doch mit: Mit Jugger eine ungewöhnliche Sportart; Serien bekamen durch das Studentennetzwerk eine neue Bedeutung, Filme ebenso durch den Mathefilmabend (mit schlechten Filmen) und dem Studentenkino im Audimax (mit besseren); auf Vorschlag einer Kommilitonin lernte ich mit ihr Salsa, ich war und bin darin untalentiert, aber es war aus Gründen später eine der wichtigsten Sachen die ich hätte lernen können. Die D&D-Gruppe erwähnte ich oben über den Spielemeister, eine Brettspielgruppe fand sich auch, meine erste. Ein paar Klischees erlebte ich zudem: Den sich nie als nützlich erweisenden Sprachkurs, krude Charaktere in WGs, sogar eine für mich gescheiterte WG, ein paar wenige Studentenfeiern.
Man kann sich ja gerade bei Informatik auf den Standpunkt stellen, dass das Studium nicht lohnt. Einfach alles relevante online lernen, oder eine Ausbildung im Unternehmen machen und so früh wie möglich mit dem Arbeiten anfangen, beides bringe am Ende durch die gesparte Zeit mehr Gehalt. Stimmt monetär vielleicht. Aber wenn nicht gerade eine Pandemie alles sowieso blockiert, dann verpasst man so eben auch dieses Leben. Das zwar bei all der Arbeit, dem geringen Einkommen und dem dauernden Prüfungsstress auch nicht immer toll war, aber im Nachhinein echt keine schlechte Zeit.
Fazit
Man wurde im Informatikstudium mit Stoff bombardiert. Das schaffte viele Grundlagen, um Neues zu verstehen und auch anzuwenden. So brauchte ich beispielsweise diesen Schubs, um die praktische Funktion von Datenbanken zu verstehen und in meine Projekte einbauen zu können. Generell wurde alles was irgendwie praxisrelevant war besonders interessant: Beispielsweise auch der Bayes-Algorithmus wegen meinem Bayes-Spamblockplugin. Aber das funktionierte auch andersrum: Praktisch alles, für das ich einen Zugang finden konnte – was mir nicht komplett unergründlich war – hatte in den Folgejahren nochmal irgendwie eine Relevanz. Selbst manche der Mathematikkenntnisse, sogar die Logikformeln aus den formalen Grundlagen erleichterten später mindestens das Lesen mancher Veröffentlichungen.
Gut, manches war zu speziell oder ist mittlerweile veraltet. Das Wasserfallmodell als Entwicklungsmodell mit Lasten und Pflichtenheft zum Beispiel – klar gibt es das noch, aber es ist aus gutem Grund nicht der Standard. UML-Diagramme hätte man auch weniger machen können, damit Programme zu planen wurde sicher nicht die Zukunft der Programmierung. Wobei: No-Code-Programmierung baut ja irgendwo schon auf den gleichen Ideen auf, dafür gibt es derzeit verstärkt Aufmerksamkeit. Bei den Software-Designpatterns weiß ich nicht mehr, ob meine bis heute anhaltende kritische Haltung vom Dozent vermittelt wurde oder ob ich damals schon ihre Probleme wahrnahm. Aber das Thema zeigt die Gefahr, dass man an der Uni auch Dinge lernen kann, die einem Programmierer in der Praxis eher schaden – wie das übertriebene Anwenden von Designpatterns.
Doch insgesamt: Für jemanden, der später Software bauen wollte, war das Informatikstudium in Darmstadt eine gute Wahl. Dass ich mir ein eigenes Bachelorarbeitsthema aussuchen konnte, direkt einen tollen Betreuer fand und daran dann auch noch bei der Telekom arbeiten konnte war dann noch ein guter Endpunkt eines guten Studiums. Rückblickend muss ich auch loben, wie gut die Uni ausgestattet war (schon der PC-Pool im Keller mit sauber funktionierenden Linux-Computern), wie fähig die Professoren Vorlesungen hielten und wie gut das Studium organisiert war, abgesehen nur vom damals fast unschaffbar überfrachteten dritten Semester.
Müsste ich nochmal von vorne anfangen, würde ich direkt wieder dieses Studium wählen und auch wieder nach Darmstadt gehen. Stattdessen ging es mit einem Master weiter, über den es auch einiges zu erzählen gibt.
Ein bisschen anonym geht eben doch: Wie die Übermedien unnötig Panik verbreiten
Tuesday, 30. October 2018
Weil die Übermedien nicht wissen was ein Angreifermodell ist, verfallen sie in einer Analyse eines Panorama-Interviews in den Panikmodus. Ein Informant sei unzureichend geschützt worden, Panorama sei unfähig. Der Themenkomplex ist in der Nähe meiner Doktorarbeit, daher ein paar Erklärungen hierzu.
Es geht um den Cum-Ex-Skandal, ein wirklich unfassbar dreister Betrug des Kapitals, bei dem der Staat sich über Jahrzehnte willfährig ausnehmen ließ. Der Interviewte ist ein Insider und zukünftiger Kronzeuge. Dementsprechend soll er anonym bleiben: Er fürchtet seine Mittäter und Konsequenzen im Privaten. Panorama hat also sein Gesicht verborgen und seine Stimme verzerrt und ihn so vor der Kamera unkenntlich gemacht.

Die Übermedien meinen das reicht nicht:
Doch dieser Schutz ist unzureichend. Und das wissen Journalisten spätestens seit dem Frühjahr 2014. Auf der Forensiker-Tagung im Mai in Münster wurde nämlich die Methode offenbar, mit der Ermittler durch Analyse der elektrischen Netzfrequenz vermummte und verkleidete Informanten, deren Stimme verzerrt wurde, enttarnen können.
Die Aussage stimmt, und doch ist ihre Folgerung falsch. Warum ist interessant.
Die Netzfrequenzanalyse betrifft erstmal genau solche Interviewszenarios. Die Netzfrequenz ist nicht mehr stabil, ihre Abweichung wird dauernd protokolliert. Sie lässt sich auch aus Aufnahmen wie der Interviewvideoaufnahme ablesen. Wann eine solche Aufnahme gemacht wurde lässt sich damit also bestimmen, man schaut einfach nach wann die Abweichung im Video mit der protokollierten übereinstimmt. Die Uebermedien glauben man würde auch den Ort herauslesen können – ich glaube das stimmt nicht, ich bin mir aber nicht ganz sicher (für diesen Artikel ist es egal).
Wenn man aber den Aufnahmezeitpunkt hat und den Ort bestimmen kann – was ein Geheimdienst ja auch mit anderen Methoden hinkriegt – dann kann ein entsprechend ausgestatteter Akteur den Interviewten identifizieren. Er muss nur Überwachungskameras auswerten und von den paar tausend Leuten, die so wahrscheinlich gefunden werden, über ihre Profile mögliche Träger der Information herauspicken. Einer der so gefundenen ist der Informant. Ein Geheimdienst macht dann was er eben so macht, NSU-Zeugen landen in brennenden Autos, Feinde Putins werden vergiftet, es bleibt sicher immer sehr stilvoll.
Warum also haben die Übermedien nicht recht mit der Anschuldigung, warum hat Panorama hier nicht furchtbar geschlampt? Das liegt schlicht am Angreifermodell und am Schutzziel.
Der Interviewte hier muss nicht umfassend vor Geheimdiensten geschützt werden. Er ist dem System bereits bekannt, er ist ein Kronzeuge, seine Aussage wird bald öffentlich und seine Identität dann bekannt sein. Es geht nur um Schutz vor den Mittätern. Das sind seine Kollegen, seine Nachbarn vielleicht, aber es sind keine Geheimdienste. Wären die hier verwickelt wüssten sie seine Identität über seine Kronzeugenrolle sowieso schon und hätten sich schon eine passende Eliminierungsmethode ausgesucht.
Das ist also praktisch der umgekehrter Fall von "Die US-Regierung wird uns nicht mit Musketen angreifen."
Meine Nachbarn sind nett, intelligent und fähig, aber sie haben nicht die Ressourcen des BND an der Hand. Sie würden in einem solchen Fall keine Überwachungsvideos auswerten und tausende Profile anlegen, sie würden wahrscheinlich die Netzfrequenzanalye nichtmal kennen. Es ist praktisch gegeben, dass dies im Fall dieses Informanten genauso ist. Denn die Mittäter sind ja wohl kaum Geheimdienste, sondern Privatpersonen – eventuell sehr reiche und skrupellose Banker, schlimm genug, aber doch keine KGB-Agenten. Damit fällt die Netzfrequenzanalyse als Angriffsvektor komplett raus. Ohne sie sind Verfremdung von Gesicht und Stimme dann auch ausreichend, um für den kurzen Zeitraum bis zur Kronzeugenaussage die Anonymität des Insiders zu wahren.
Denn interessanterweise stimmt dieser stark klingende Satz eben nicht:
Doch ein bisschen anonym ist problematisch. Das funktioniert genauso wenig wie ein bisschen schwanger.
Ein bisschen schwanger geht nicht, ein bisschen anonym geht durchaus. Das ist nicht ganz intuitiv, aber Stand der Anonymitätsforschung. Denn praktisch immer ist Anonymität eben doch ein Grad und nicht absolut.
Ein Beispiel: Wenn ein geehrter Leser dieses Artikels hierdrunter einen fiesen Kommentar schreibt und einen falschen Namen benutzt ist er wahrscheinlich mir gegenüber anonym. Ich habe kaum Möglichkeiten die civil identity dieses fiktiven Kommentators zu finden, dann zu ihm zu fahren und ihm eins auf die Nase zu hauen. Glücklicherweise ist das auch nie nötig, meine Kommentatoren immer nett.
Jetzt nehmen wir aber mal an der Kommentator schrieb nicht einfach einen fiesen Kommentar, sondern kündigt einen islamistischen Terrorangriff an. Ich habe zwar immer noch keine Methode ihn aufzuspüren. Aber so etwas würde die Polizei und die Geheimdienste alarmieren, und die könnten dann über die Vorratsdatenspeicherung den Kommentatorterroristen ganz schnell identifizieren. Hat er technische Vorkehrungen getroffen geht es vielleicht etwas weniger schnell, aber es gibt im Internet kaum absolute Anonymität.
Das gleiche gilt auch bei anderen Kommunikationswegen. In fast jeder Situation kann man Leute finden, gegen die ein vermummter Kommunikationsteilnehmer anonym ist, aber von dem andere Stellen durchaus die Identität kennen oder kennen könnten.

Das Foto hier taugt dafür als zweites Beispiel. Ich weiß nicht wer das ist. Gegenüber dem Großteil des Internets ist die junge Dame anonym. Aber der Fotograf dürfte wissen wer das ist, ein entsprechend begabter Detektiv kann ihre Identität wohl aufdecken. Und ihre Mutter würde sie wohl auch erkennen.
Deshalb ist bei solch einer Situation wie dem Panorama-Interview der Kontext so wichtig. Er bestimmt das Angreifermodell: Wer wird die Identität aufdecken wollen und welche Fähigkeiten hat er dafür? Dementsprechend sind ganz unterschiedliche Anonymitätsgrade erforderlich. Man kann sich auch überlegen: Wie schlimm wäre es, wenn die Identität bekannt würde? Auch das kann in die Entscheidung reinfließen.
Den Aussagen des Chefredakteus zufolge wurde genau das sorgfältig und richtig gemacht. Die Übermedien hätten seine Aussagen nicht nur zitieren sollen, sondern sie hätten Beachtung verdient gehabt. Denn mit dem richtigen Hintergrundwissen widerlegen sie alleine komplett den dort lancierten Artikel. Aber ich will die Übermedien gar nicht zu stark kritisieren: Anonymität ist ein erstaunlich kompliziertes Thema. Hier fehlte sicher einfach etwas Hintergrundwissen, um falsche Schlussfolgerungen zu vermeiden – obwohl der genannte Autor es besser wissen müsste heißt die Autorenangabe ja nicht, dass alles aus seiner Feder stammt.
Denn ein bisschen anonym geht eben doch. Man ist sogar immer nur ein bisschen anonym, genau wie Sicherheit niemals absolut ist. Und in anderen Kontexten haben gerade das die Übermedien ja durchaus verstanden.
Monitorama PDX 2014 - James Mickens
Saturday, 25. March 2017
The glEnd() of Zelda
Saturday, 2. April 2016
Growing a Language (1998)
Friday, 1. March 2013
Lamport-Diffie Einmal-Signaturverfahren
Monday, 22. October 2012
Spamblock-Bayes: Theoretische Grundlagen
Friday, 22. June 2012
Bayes-Formel
Das Bayes-Theorem wurde entdeckt, verworfen und schließlich wiederentdeckt. Ich glaube, die mathematischen Einwände gegen die Formel finden sich manchmal noch in der Kritik an solchen Filtern wieder, deshalb sei ihr Vorhandensein erwähnt.Die allgemeine Formel lautet:

P(A) ist die Wahrscheinlichkeit für A, P(A|B) ist die Wahrscheinlichkeit für A unter der Bedingung B, also wenn B eingetreten ist.
Wie sieht das nun für Spam aus? So:
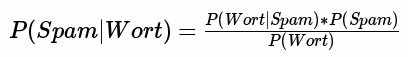
Zu beachten ist, dass wir diese Spamwahrscheinlichkeit für jedes Wort im Kommentar wissen wollen, daher am Ende mehrere Wahrscheinlichkeiten aufaddieren und normalisieren müssen.
Aufdröselung
Es gibt also genau drei Variabeln zu berechnen: Die Inverse Wahrscheinlichkeit, die Wahrscheinlichkeit von Spam und die Wahrscheinlichkeit für das Auftreten solcher Wörter. Das für jedes Wort. Was genau bedeuten die Formeln jeweils?- P(Wort|Spam)
- Dies ist die Wahrscheinlichkeit, dass in einem Spamkommentar dieses Wort vorkommt: Spamkommentare mit diesem Wort / Spamkommentare
- P(Spam)
- Die Gesamtwahrscheinlichkeit, dass ein Kommentar Spam ist: Spamkommentare / Kommentare.
- P(Wort)
- Die Wahrscheinlichkeit, dass dieses Wort überhaupt in einem Kommentar vorkommt: Kommentare mit diesem Wort / Kommentare
Programmiertechnische Konsequenzen
Es ist völlig klar, dass eine Datenbank gebraucht wird und die Bewertung größtenteils aus dem Heraussuchen der richtigen Daten zu den Worten besteht. Zuerst muss ein sogenannter Tokenizer den Kommentar in seine Einzelwörter zerlegen. Im Wesentlichen ist das ein:tokenize(text) {
tokens = split("\W", text )
return unique(tokens)
}
Das Lernen eines Kommentars als Ham oder Spam ist nun nichts anderes, als diese Tokens in diese Datenbank namens "tokens" zu schreiben:
token (text) | ham (number) | spam (number)Ist das Token schon vorhanden, wird der zugehörige Ham- bzw Spamwert um eins erhöht. Gleichzeitig wird der Gesamtzähler Hamkommentare bzw Spamkommentare um eins erhöht.
Diese Datenbank zusammen mit den Gesamtzählern gibt uns nun alle nötigen Werte:
- P(Wort|Spam)
spam = sql_query("Select spam from tokens where token = Wort") spam / (Spamkommentare)- P(Spam)
Spamkommentare / (Spamkommentare + Hamkommentare)
- P(Wort)
ham, spam = sql_query("Select ham, spam from tokens where token = Wort)" (ham + spam) / (Spamkommentare + Hamkommentare)
Formelveränderungen
Schaut man sich nun die Bewertungsfunktion im Bayes-Plugin an wird man feststellen, dass der PHP-Code nicht nur wesentlich unschöner als mein Pseudocode aussieht, sondern auch anders funktioniert. Das liegt daran, dass das Plugin auf b8 aufbaute, und b8 nicht simpel das Bayes-Theorem benutzt, die Wahrscheinlichkeiten addiert und dann durch ihre Anzahl teilt. Diese Änderungen basieren auf Tests und anderen theoretischen Annahmen als den hier gezeigten. Insbesondere die folgenden Änderungen sind enthalten oder denkbar:Law of total probability
Wer Vorkenntnisse hat oder nachrecherchierte, dem könnte aufgefallen sein, dass Wikipedias Bayes-Spamfilterformel anders aussieht:
P(Wort) wird hier gemäß dem Law of total probability umgeformt. Ohne das gerade nachgerechnet zu haben vermute ich, dass die Werte gleich sein sollten und diese Formel nur P(Wort) anders betrachtet.
Häufigkeit von Tokens im Kommentar
Wie oft ein Wort im Kommentar auftaucht sollte die Wahrscheinlichkeit beeinflussen. Dieser Artikel hier ist kein Spam, obwohl nun Viagra auftaucht, aber wäre jedes Wort Viagra, wäre er durchaus Spam. Deshalb beachtet b8 die Häufigkeit eines Tokens.Wichtigkeit
Eine beliebte Spammertaktik ist, Kommentare mit ewig langem Fülltext auszustaffieren und den Spammerinhalt so zu verstecken. Der Gedanke dabei ist, dass die vielen harmlosen Worte den ganzen Kommentar harmlos erscheinen lassen. Die auch von b8 genutzte Taktik dagegen ist die Einführung eines Wichtigkeitsfaktors: Beziehe nur die Tokens in die Schlussrechnung ein, die eine Tendenz zu Spam oder Ham haben, also um einen bestimmten Faktor von der Mitte 0,5 abweichen. Der Gedanke dahinter ist, dass die vielen Füllwörter die Bewertung sonst gegen 0,5 tendieren lassen würden.Optimierungsmöglichkeiten
Ich schrieb oben, dass dieser Artikel die theoretischen Grundlagen zwecks einer späteren Optimierung des Filters deutlich machen soll.Diese Optimierungsmöglichkeiten sehe ich bis jetzt:
Ham-Spam-Faktor
Der Anstoßgeber dieses Eintrags ist diese Diskussion. Grischa schlug vor, über irgendeinen Faktor auszugleichen, dass ein typischer Blog sehr viel mehr Spam als Ham bekommt und daher der Filter zu streng werden würde. Meiner Meinung nach ist das nicht wirklich ein Problem, da diese Verteilung elementar für den Filter ist, und nicht automatisch neuer Spam eingelernt wird, wenn man das nicht will.Wikipedia erwähnt, dass P(Spam) generell 0,8 sei. Vielleicht würde es helfen, diesen Wert festzusetzen statt ihn empirisch zu bestimmen?
Häufigkeit von Tokens
Wie oben beschrieben ist die Häufigkeit von Wörtern innerhalb eines Kommentars ein wichtiger Faktor. Zur Zeit fließt das aber nur indirekt in die Bewertung ein, indem es bei der Bewertung selbst ignoriert wird, beim Einlernen aber beachtet wird. Statt in der Tabelle den Ham- bzw Spamwert um eins zu erhöhen, wird er um die Anzahl der Tokens erhöht. Bei der Bewertung aber wird jedes Token nur einmal beachtet, selbst wenn es mehrmals vorkommt. Das könnte man ändern.Es ist auch ein kritischer Punkt, weil man sich hier leicht mit Anzahl der Tokens und Anzahl der Kommentare verheddern kann. Die Formel müsste genau geprüft werden.
Konstanten
Bei der Übernahme von b8 wurde die Klassifizierungsberechnung blind übernommen. In ihr enthalten sind einige Konstanten, die auf den Testergebnissen beruhen. Es geht um diese Zeile:$ratings[$word] = (0.15 + (($stored_tokens[$word]['ham'] + $stored_tokens[$word]['spam']) * $rating)) / (0.3 + $stored_tokens[$word]['ham'] + $stored_tokens[$word]['spam']);0,15 und 0,3 sind die Konstanten, die hier direkt die Bewertung beeinflussen und entfernt bzw verändert werden könnten.

