Rhythmbox Remember the Rhythm ohne Autoplay
Tuesday, 11. December 2012
Javascript Canvas skalieren
Monday, 3. December 2012
Javascript Tooltips
Saturday, 17. November 2012
Diese Javascript-Tooltips (Demo) machen auf mich einen guten Eindruck. Formatierbar mit HTML, ist es nicht zu schwer sie so zu erweitern, dass sie bei einem Klick auf das Element offen bleiben - denn darum geht es mir, Tooltips mit klickbaren Links.
Nutzen würde ich sie derzeit so:
dot.onmouseover=function(e) {
tooltip.show(tooltipText, e, false);
};
dot.onmouseout=function() {
tooltip.hide(false);
};
dot.onclick=function(e) {
tooltip.hide(false);
tooltip.show(tooltipText, e, true);
document.querySelector("#ttclose").onclick = function() {
tooltip.hide(true);
}
}
Und hier der von mir abgeänderte Code (rein experimentell und noch mit Formatierungsfehlern):
var tooltip=function(){
var id = 'tt';
var top = 3;
var left = 3;
var maxw = 300;
var speed = 10;
var timer = 20;
var endalpha = 95;
var alpha = 0;
var tt,c,h;
var x;
var perma = false;
var ie = document.all ? true : false;
return {
show:function(tooltipText, e, permanent){
if(tt == null){
tt = document.createElement('div');
tt.setAttribute('id',id);
c = document.createElement('div');
c.setAttribute('id',id + 'cont');
tt.appendChild(c);
document.body.appendChild(tt);
tt.style.opacity = 0;
tt.style.filter = 'alpha(opacity=0)';
}
tt.style.display = 'block';
c.innerHTML = tooltipText;
tt.style.width = e ? e + 'px' : 'auto';
if(!e && ie){
tt.style.width = tt.offsetWidth;
}
if(tt.offsetWidth > maxw){tt.style.width = maxw + 'px'}
h = parseInt(tt.offsetHeight) + top;
clearInterval(tt.timer);
tt.timer = setInterval(function(){tooltip.fade(1)},timer);
perma = permanent
if (permanent && tt.querySelector("#"+id + "close") == null) {
x = document.createElement('div');
x.innerHTML = "x";
x.setAttribute('id',id + "close");
tt.insertBefore(x,c);
}
this.pos(e);
},
pos:function(e){
var u = ie ? event.clientY + document.documentElement.scrollTop : e.pageY;
var l = ie ? event.clientX + document.documentElement.scrollLeft : e.pageX;
tt.style.top = (u - h) + 'px';
tt.style.left = (l + left) + 'px';
},
fade:function(d){
var a = alpha;
if((a != endalpha && d == 1) || (a != 0 && d == -1)){
var i = speed;
if(endalpha - a < speed && d == 1){
i = endalpha - a;
} else if(alpha < speed && d == -1){
i = a;
}
alpha = a + (i * d);
tt.style.opacity = alpha * .01;
tt.style.filter = 'alpha(opacity=' + alpha + ')';
}else{
clearInterval(tt.timer);
if(d == -1){tt.style.display = 'none'}
}
},
hide:function(permanent){
if (perma) {
if (permanent) {
clearInterval(tt.timer);
tt.timer = setInterval(function(){tooltip.fade(-1)},timer);
}
} else {
clearInterval(tt.timer);
tt.timer = setInterval(function(){tooltip.fade(-1)},timer);
}
}
};
}();
Stylesheet:
#tt {
position: absolute;
display: block;
}
#ttclose {
border-top-left-radius: 3px;
border-top-right-radius: 3px;
background: #666;
color: #fff;
}
#ttclose span {
cursor: pointer;
display: flex;
display: -moz-flex;
display: -webkit-flex;
justify-content: flex-end;
-moz-justify-content: flex-end;
-webkit-justify-content: flex-end;
margin-right: 0.5em;
}
#ttcont {
display: block;
padding: 2px 12px 3px 7px;
margin-left: 5px;
background: #666;
color: #fff;
text-align: left;
border-bottom-left-radius: 3px;
border-bottom-right-radius: 3px;
}
#ttcont a {
color: white;
}
#ttcont ul {
margin: 0;
padding-left: 1em;
}
#ttcont h5 {
margin-top: 0.1em;
margin-bottom: 0.3em;
}
Ergebnis:

CSS: Aus einer Checkbox einen Slider-Button machen
Monday, 12. November 2012
![]() Aus einer einfachen Checkbox mit zwei Bildern einen Slider-Button (bei dem Begriff herrscht Verwirrung: Ist das nun ein Slider-Button? Oder ein Toggle-Switch? Ein Umschalter eben) machen, das ist hier das Ziel. Es soll ohne Javascript funktionieren, und erst recht ohne jQuery, daher fielen die [http://www.larentis.eu/bootstrap_toggle_buttons/ Bootstrap toggle buttons] weg. Und deswegen geht es auch rein um die Optik, den Umschalter wirklich ziehbar zu machen hielt ich für unangemessen aufwändig bis unmöglich.
Aus einer einfachen Checkbox mit zwei Bildern einen Slider-Button (bei dem Begriff herrscht Verwirrung: Ist das nun ein Slider-Button? Oder ein Toggle-Switch? Ein Umschalter eben) machen, das ist hier das Ziel. Es soll ohne Javascript funktionieren, und erst recht ohne jQuery, daher fielen die [http://www.larentis.eu/bootstrap_toggle_buttons/ Bootstrap toggle buttons] weg. Und deswegen geht es auch rein um die Optik, den Umschalter wirklich ziehbar zu machen hielt ich für unangemessen aufwändig bis unmöglich.
[http://www.onli-blogging.de/uploads/slider.html Demo]
Thema Optik: Es werden [/uploads/on.jpg zwei] [/uploads/off.jpg Grafiken] benutzt, beide stammen von [http://www.chrisnorstrom.com/2012/11/invention-multiple-choice-windowed-slider-ui/ Chris Norström].
Die HTML-Struktur ist eine normale Checkbox in einem Formular, nur dass hinten ein span angehängt wird.
<form>
<label>
<input type="checkbox" checked/>
<span></span>
</label>
</form>
Warum mit dem leeren span den sonst minimalen Code verschandeln? Firefox ist schuld. Im Folgenden wird mit :before das Bild des Buttons über die Checkbox gelegt. Das könnte man auch direkt mit dem input-Element machen, in Webkit-Browsern geht das auch, aber Firefox versteht die Spezifikation anders und lässt daher keinen Pseuso-Inhalt mittels :before zu. Daher das span als Behelfsziel. Man könnte auch mit dem Label arbeiten.
Da das span in dem label der checkbox ist, zählen Klicke auf das span als Klicks für die checkbox.
Deswegen geben wir dem span erstmal display: inline-block mit und setzen Breite und Höhe.
input[type="checkbox"] + span {
width: 84px;
height: 26px;
display: inline-block;
}
Wie gesagt, nun wird mit :before das Bild hineingelegt:
input[type="checkbox"] + span:before {
content:"";
display: inline-block;
width: 100%;
height: 100%;
background: url("/uploads/off.jpg") no-repeat 0 0;
background-size: 100% 100%;
}
Und der gedrückte Schalter, wenn die checkbox aktiviert ist:
input[type="checkbox"]:checked + span:before {
content:"";
display: inline-block;
width: 100%;
height: 100%;
background: url("/uploads/on.jpg") no-repeat 0 0;
background-size: 100% 100%;
}
Die Checkbox kann man dann ausblenden:
input[type="checkbox"] {
display: none;
}
Das schöne an der Lösung: Das skaliert mit. Ändert man Breite und Höhe des span, wird das Bild passend skaliert. Deswegen ist das Button-Bild auch als Hintergrundbild eingebunden statt als Pseudo-Content.
Cache für Sinatra
Sunday, 28. October 2012
Ich habe eine ziemlich funktionsfähige Blogsoftware mit Sinatra gebaut. Ein absolutes Pflichtfeature war ein Cache, also dass einmal generierte Seiten irgendwo gespeichert und nachher ohne Neuerstellung genutzt werden können. Caches bei Blogsoftware sind unumgänglich, werden Blogs doch viel öfter gelesen als beschrieben. In meinem Fall ist nicht memcached oder ähnliches der dafür geeignete Ort, sondern die auch für alles andere genutzte SQLite-Datenbank.
Grundlage
Ein Cache ist im einfachsten Fall ein einfacher Key-Value-Speicher. Soll er automatisch nicht unbegrenzt speichern, braucht er irgendein Mittel zur automatischen Cache-Invalidierung, also wird noch ein Time-To-Live-Feld (ttl) eingebaut, das automatisch befüllt wird. Insgesamt:
@db.execute "CREATE TABLE IF NOT EXISTS cache(
key TEXT PRIMARY KEY,
value TEXT,
ttl INTEGER DEFAULT (strftime('%s','now') + 604800)
);"
Die Funktionen zum Befüllen und Holen von Werten:
def cache(key, value)
begin
@db.execute("INSERT OR IGNORE INTO cache(key, value) VALUES(?, ?)", key, value)
@db.execute("UPDATE cache SET value = ?, ttl = (strftime('%s','now') + 604800) WHERE key = ?", value, key)
rescue => error
puts error
end
end
def getCache(key)
begin
return @db.execute("SELECT value FROM cache WHERE key = ? AND ttl > strftime('%s','now') LIMIT 1;", key)[0]['value']
rescue => error
puts error
end
end
In der restlichen Sinatraanwendung kann man nun alle GET-Requests durch den Cache laufen lassen: Nur wenn der keinen Inhalt hat wird der eigentliche Code ausgeführt und dessen Ergebnis dann gecached. Dafür ideal geeignet sind die before() und after() Funktionen von Sinatra, die vor und nach jedem Seitenaufruf ausgeführt werden.
Vor jedem Aufruf wird der Cache geprüft:
before do
@cacheContent = Database.new.getCache(request.path_info)
end
after do
Database.new.cache("request.path_info", body)
end
In den eigentlichen Funktionen muss nun vor der eigentlichen Codeausführung auf den Cache reagiert werden:
get '/' do
if @cacheContent != nil
return @cacheContent
end
...
end
Und, wichtig: Damit body während after() schon gesetzt ist, muss er explizit gesetzt werden:
get '/' do
if @cacheContent != nil
return @cacheContent
end
... # do stuff
body erb :index # instead of erb :index
end
Schon steht ein Cache.
Optimierungen
So wie oben reicht das natürlich noch nicht. Zum einen darf natürlich nicht jeder Request gecached werden, sondern nur GET-Requests:
before do
@cacheContent = nil
if request.request_method == "GET"
@cacheContent = Database.new.getCache(request.path_info)
end
end
after do
if @cacheContent == nil && request.request_method == "GET"
Database.new.cache(request.path_info, body)
end
end
Außerdem soll der Cache invalidiert werden, wenn mit einem POST-Request schreibend der Bloginhalt verändert wurde, sei es durch einen Kommentar oder einen neuen Artikel. Je granularer man hier arbeitet, desto besser wird der Cache funktionieren, aber im Zweifel muss eben der ganze Cache invalidiert werden. Entweder man führt dazu einen Cache-Instanzvariable ein, die dann verändert wird, sodass der Cacheinhalt nicht mehr gefunden wird. Oder man löscht einfach den gesamten Cacheinhalt:
def invalidateCache()
begin
return @db.execute("DELETE FROM cache WHERE key LIKE '/%'")
rescue => error
puts error
end
end
Da der Cache in meinem Fall noch andere Elemente beinhaltet, wird hier das Löschen über /% auf Elemente mit führendem /, wie eben alle request.path_info-Keys aussehen, eingeschränkt.
Auf der Sinatra-Ebene wird das bei jedem POST ausgelöst (alternativ sicherer auf Datenbankebene bei jedem relevanten Write):
after do
if @cacheContent == nil && request.request_method == "GET"
Database.new.cache(request.path_info, body)
else
if request.request_method == "POST"
Database.new.invalidateCache
end
end
end
Ganz reicht das noch nicht. In meinem Blog gibt es zwei Nutzergruppen, die unterschiedliche Seiten präsentiert bekommen: Einfache Besucher und solche mit Schreibrechten, Admins. Derzeit würden noch beide die gleichen Seiten gecached bekommen, je nachdem, welche Gruppe die Seite zuerst aufruft. Um da zu unterscheiden wird am einfachsten der key angepasst:
before do
@cacheContent = nil
if request.request_method == "GET"
@cacheContent = Database.new.getCache("#{request.path_info}#{isAdmin?}")
end
end
after do
if @cacheContent == nil && request.request_method == "GET"
Database.new.cache("#{request.path_info}#{isAdmin?}", body)
else
if request.request_method == "POST"
Database.new.invalidateCache
end
end
end
Das ist dann auch die derzeit finale Version.
Performance
Bringt das was? Benchmarken soll man zwar nie auf dem PC, auf dem der Server läuft, hier aber geht es nur um den Unterschied, daher halte ich das für legitim.
ab -n 1000 -c 5 http://localhost:4567:
Ohne Cache:
Requests per second: 23.58 [#/sec] (mean) Time per request: 212.042 [ms] (mean) Time per request: 42.408 [ms] (mean, across all concurrent requests) Transfer rate: 131.44 [Kbytes/sec] received
Mit Cache:
Requests per second: 124.77 [#/sec] (mean) Time per request: 40.074 [ms] (mean) Time per request: 8.015 [ms] (mean, across all concurrent requests) Transfer rate: 695.50 [Kbytes/sec] received
Grafisch:
Bei einem simulierten Benutzeransturm hilft der Cache definitiv (und mit 500% weit mehr als ich erhofft hatte).
Ohne Last sinkt die Wartezeit auf den Server, bei gefülltem Cache und laut Chrome, von 54ms auf 27ms. Auch nicht schlecht.
Richtig: (0 == 0) == false
Saturday, 27. October 2012
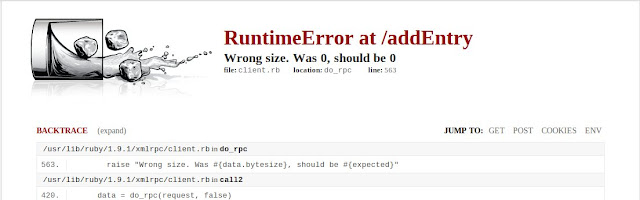
Solche absurden Fehlermeldungen sind also nicht auf Windows beschränkt.
Bash: Convert to UTF-8
Saturday, 19. May 2012
Bash: Assoziative Arrays
Friday, 18. May 2012
JS: Submit einer Form per Enter sinnvoll verhindern
Tuesday, 24. April 2012
visibleIf.js
Sunday, 22. April 2012
Was das Smartifizieren bringt
Friday, 2. March 2012
Es wird öfter geschrieben, dass Serendipity sauberen Code hätte und ein gutes Stück Software sei. Letztes bestreite ich keinesfalls. Aber über den sauberen Code kann man streiten: es ist halt ursprünglich ein PHP4-Programm, und das sieht man.
Im Backend sieht es besonders übel aus. Gerne wurde da mit ?> gearbeitet und daraufhin der HTML-Code direkt ausgegeben - und dabei die Einrückung aufgegeben. Dadurch wird der Code richtig schwer lesbar. Ein gutes Beispiel ist dieser Abschnitt der plugins.inc.php:
if ($serendipity['GET']['only_group'] == 'UPGRADE') {
serendipity_plugin_api::hook_event('backend_pluginlisting_header_upgrade', $pluggroups);
}
?>
<table cellspacing="0" cellpadding="0" border="0" width="100%">
<?php
$available_groups = array_keys($pluggroups);
foreach($pluggroups AS $pluggroup => $groupstack) {
if (empty($pluggroup)) {
?>
<tr>
<td colspan="2" class="serendipity_pluginlist_header">
<form action="serendipity_admin.php" method="get">
<?php echo serendipity_setFormToken(); ?>
<input type="hidden" name="serendipity[adminModule]" value="plugins" />
<input type="hidden" name="serendipity[adminAction]" value="addnew" />
<input type="hidden" name="serendipity[type]" value="<?php echo htmlspecialchars($serendipity['GET']['type']); ?>" />
<?php echo FILTERS; ?>: <select name="serendipity[only_group]">
<?php foreach((array)$available_groups AS $available_group) {
?>
<option value="<?php echo $available_group; ?>"
<?php echo ($serendipity['GET']['only_group'] == $available_group ? 'selected="selected"' : ''); ?>>
<?php echo serendipity_groupname($available_group); ?>
<?php } ?>
<option value="ALL" <?php echo ($serendipity['GET']['only_group'] == 'ALL' ? 'selected="selected"' : ''); ?>>
<?php echo ALL_CATEGORIES; ?>
<option value="UPGRADE" <?php echo ($serendipity['GET']['only_group'] == 'UPGRADE' ? 'selected="selected"' : ''); ?>>
<?php echo WORD_NEW; ?>
</select>
<input class="serendipityPrettyButton input_button" type="submit" value="<?php echo GO; ?>" />
</form>
</td>
</tr>
<?php
if (!empty($serendipity['GET']['only_group'])) {
continue;
}
} elseif (!empty($serendipity['GET']['only_group']) && $pluggroup != $serendipity['GET']['only_group']) {
continue;
} else {
?>
<td colspan="2" class="serendipity_pluginlist_section"><strong><?php echo serendipity_groupname($pluggroup); ?></strong></td>
</tr>
<?php
}
?>
<tr>
<td><strong>Plugin</strong></td>
<td width="100" align="center"><strong>Action</strong></td>
</tr>
<?php
foreach ($groupstack as $plug) {
Die gleiche Stelle in der smartifizierten Version:
if ($serendipity['GET']['only_group'] == 'UPGRADE') {
serendipity_plugin_api::hook_event('backend_pluginlisting_header_upgrade', $pluggroups);
}
$available_groups = array_keys($pluggroups);
$data['available_groups'] = $available_groups;
$groupnames = array();
foreach($available_groups as $available_group) {
$groupnames[$available_name] = serendipity_groupname($available_group);
}
$data['groupnames'] = $groupnames;
$data['pluggroups'] = $pluggroups;
$data['formToken'] = $formToken;
$data['only_group'] = $serendipity['GET']['only_group'];
$requirement_failures = array();
foreach($pluggroups AS $pluggroup => $groupstack) {
foreach ($groupstack as $plug) {
Man spart zwar nicht insgesamt an Zeilen:
wc -l include/admin/plugins.inc.php
583 include/admin/plugins.inc.php
wc -l /var/www/include/admin/plugins.inc.php /var/www/include/admin/tpl/plugins.inc.tpl
448 /var/www/include/admin/plugins.inc.php
209 /var/www/include/admin/tpl/plugins.inc.tpl
657 insgesamt
Es wurden zusammengerechnet sogar mehr. Aber man bekommt weniger und besser lesbaren Code auf der Logikebene, und sowieso: Eine Trennung zwischen Logikebene und Sicht.
Eine sehr kleine Datei fehlt noch, bis jetzt bin ich mit dem Ergebnis unserer Arbeit schon sehr zufrieden.

Gettext - export TEXTDOMAIN
Sunday, 12. February 2012
Kategorien
Blog abonnieren

