Videotutorials für League of Legends
Wednesday, 31. October 2012
Cache für Sinatra
Sunday, 28. October 2012
Ich habe eine ziemlich funktionsfähige Blogsoftware mit Sinatra gebaut. Ein absolutes Pflichtfeature war ein Cache, also dass einmal generierte Seiten irgendwo gespeichert und nachher ohne Neuerstellung genutzt werden können. Caches bei Blogsoftware sind unumgänglich, werden Blogs doch viel öfter gelesen als beschrieben. In meinem Fall ist nicht memcached oder ähnliches der dafür geeignete Ort, sondern die auch für alles andere genutzte SQLite-Datenbank.
Grundlage
Ein Cache ist im einfachsten Fall ein einfacher Key-Value-Speicher. Soll er automatisch nicht unbegrenzt speichern, braucht er irgendein Mittel zur automatischen Cache-Invalidierung, also wird noch ein Time-To-Live-Feld (ttl) eingebaut, das automatisch befüllt wird. Insgesamt:
@db.execute "CREATE TABLE IF NOT EXISTS cache(
key TEXT PRIMARY KEY,
value TEXT,
ttl INTEGER DEFAULT (strftime('%s','now') + 604800)
);"
Die Funktionen zum Befüllen und Holen von Werten:
def cache(key, value)
begin
@db.execute("INSERT OR IGNORE INTO cache(key, value) VALUES(?, ?)", key, value)
@db.execute("UPDATE cache SET value = ?, ttl = (strftime('%s','now') + 604800) WHERE key = ?", value, key)
rescue => error
puts error
end
end
def getCache(key)
begin
return @db.execute("SELECT value FROM cache WHERE key = ? AND ttl > strftime('%s','now') LIMIT 1;", key)[0]['value']
rescue => error
puts error
end
end
In der restlichen Sinatraanwendung kann man nun alle GET-Requests durch den Cache laufen lassen: Nur wenn der keinen Inhalt hat wird der eigentliche Code ausgeführt und dessen Ergebnis dann gecached. Dafür ideal geeignet sind die before() und after() Funktionen von Sinatra, die vor und nach jedem Seitenaufruf ausgeführt werden.
Vor jedem Aufruf wird der Cache geprüft:
before do
@cacheContent = Database.new.getCache(request.path_info)
end
after do
Database.new.cache("request.path_info", body)
end
In den eigentlichen Funktionen muss nun vor der eigentlichen Codeausführung auf den Cache reagiert werden:
get '/' do
if @cacheContent != nil
return @cacheContent
end
...
end
Und, wichtig: Damit body während after() schon gesetzt ist, muss er explizit gesetzt werden:
get '/' do
if @cacheContent != nil
return @cacheContent
end
... # do stuff
body erb :index # instead of erb :index
end
Schon steht ein Cache.
Optimierungen
So wie oben reicht das natürlich noch nicht. Zum einen darf natürlich nicht jeder Request gecached werden, sondern nur GET-Requests:
before do
@cacheContent = nil
if request.request_method == "GET"
@cacheContent = Database.new.getCache(request.path_info)
end
end
after do
if @cacheContent == nil && request.request_method == "GET"
Database.new.cache(request.path_info, body)
end
end
Außerdem soll der Cache invalidiert werden, wenn mit einem POST-Request schreibend der Bloginhalt verändert wurde, sei es durch einen Kommentar oder einen neuen Artikel. Je granularer man hier arbeitet, desto besser wird der Cache funktionieren, aber im Zweifel muss eben der ganze Cache invalidiert werden. Entweder man führt dazu einen Cache-Instanzvariable ein, die dann verändert wird, sodass der Cacheinhalt nicht mehr gefunden wird. Oder man löscht einfach den gesamten Cacheinhalt:
def invalidateCache()
begin
return @db.execute("DELETE FROM cache WHERE key LIKE '/%'")
rescue => error
puts error
end
end
Da der Cache in meinem Fall noch andere Elemente beinhaltet, wird hier das Löschen über /% auf Elemente mit führendem /, wie eben alle request.path_info-Keys aussehen, eingeschränkt.
Auf der Sinatra-Ebene wird das bei jedem POST ausgelöst (alternativ sicherer auf Datenbankebene bei jedem relevanten Write):
after do
if @cacheContent == nil && request.request_method == "GET"
Database.new.cache(request.path_info, body)
else
if request.request_method == "POST"
Database.new.invalidateCache
end
end
end
Ganz reicht das noch nicht. In meinem Blog gibt es zwei Nutzergruppen, die unterschiedliche Seiten präsentiert bekommen: Einfache Besucher und solche mit Schreibrechten, Admins. Derzeit würden noch beide die gleichen Seiten gecached bekommen, je nachdem, welche Gruppe die Seite zuerst aufruft. Um da zu unterscheiden wird am einfachsten der key angepasst:
before do
@cacheContent = nil
if request.request_method == "GET"
@cacheContent = Database.new.getCache("#{request.path_info}#{isAdmin?}")
end
end
after do
if @cacheContent == nil && request.request_method == "GET"
Database.new.cache("#{request.path_info}#{isAdmin?}", body)
else
if request.request_method == "POST"
Database.new.invalidateCache
end
end
end
Das ist dann auch die derzeit finale Version.
Performance
Bringt das was? Benchmarken soll man zwar nie auf dem PC, auf dem der Server läuft, hier aber geht es nur um den Unterschied, daher halte ich das für legitim.
ab -n 1000 -c 5 http://localhost:4567:
Ohne Cache:
Requests per second: 23.58 [#/sec] (mean) Time per request: 212.042 [ms] (mean) Time per request: 42.408 [ms] (mean, across all concurrent requests) Transfer rate: 131.44 [Kbytes/sec] received
Mit Cache:
Requests per second: 124.77 [#/sec] (mean) Time per request: 40.074 [ms] (mean) Time per request: 8.015 [ms] (mean, across all concurrent requests) Transfer rate: 695.50 [Kbytes/sec] received
Grafisch:
Bei einem simulierten Benutzeransturm hilft der Cache definitiv (und mit 500% weit mehr als ich erhofft hatte).
Ohne Last sinkt die Wartezeit auf den Server, bei gefülltem Cache und laut Chrome, von 54ms auf 27ms. Auch nicht schlecht.
Richtig: (0 == 0) == false
Saturday, 27. October 2012
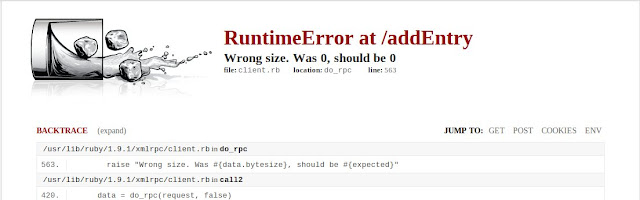
Solche absurden Fehlermeldungen sind also nicht auf Windows beschränkt.
Lamport-Diffie Einmal-Signaturverfahren
Monday, 22. October 2012
Bilder für Dropbox Camera Upload
Saturday, 20. October 2012
Um den Speicherplatz von Dropbox zu erweitern ist die Nutzung des Bilder-Imports für Smartphones eine Möglichkeit. Immer wenn ein Block von 500 MB Bilder angefangen wird bekommt man diese 500 als Bonus-Speicherplatz dazu, bis zu einer Grenze von 3GB (also 2,501GB an Bilder = 3GB mehr Speicherplatz). Ich muss das noch testen, aber angeblich bleibt das auch nach Löschen der Bilder erhalten.
Leider funktioniert das nicht unter Linux und so viele Bilder muss man auch erstmal auf dem Handy haben. Ersteres kann man wohl derzeit nicht lösen, also muss Windows gebootet werden, aber woher die Bilder nehmen? 2500mal auf den Auslöser drücken? Einfacher wäre es ja, die Bilder herunterzuladen und auf dem Handy zu speichern. Dropbox erkennt zwar hervorragend Duplikate (deswegen kann man meinem Test nach nicht einfach ein Bild nehmen und das entsprechend häufig kopieren), aber aus dem Internet heruntergeladene Bilder statt selbst aufgenommenen werden ja hoffentlich nicht als solche erkannt und sollten für das Limit zählen.
Doch beliebig Bilder herunterzuladen ist auch gar nicht so einfach. Software und Webseiten zum Ziehen von Bildern aus der Google-Bildersuche kranken entweder an dem 64-Bilder-Limit oder sind furchtbar langsam. Dann fiel mir ein, dass ich eine passende Software für ein sehr ähnliches Szenario mal mit einem Team gebaut habe: image-sacon, ein Tool zum massenhaften Herunterladen von Bildern von Imagehostern bzw Flickr. Tatsächlich funktioniert die Software, obwohl nicht hübsch und seit dem Ende des Uniprojekts nicht mehr gepflegt, bei mir gerade einwandfrei.

Hab ich schonmal vorgestellt, aber selbst fast völlig vergessen.
Damit werde ich Bilder herunterladen, schiebe die aufs Handy, starte Windows und lasse sie von Dropbox importieren, schließlich hochladen und habe dadurch nach ihrer Löschung hoffentlich 3GB mehr Speicher.
Zusammen mit dem Space-Race ist das dann ein bisschen besser als die 2GB am Anfang.
Speicherverbrauch und Startzeit unter Precise
Friday, 19. October 2012
Diesmal sind es nicht meine Daten. Dieser Artikel über die Startzeiten und Speicherverbrauch von grafischen Oberflächen (via) unter Ubuntu 12.04 in Charts:

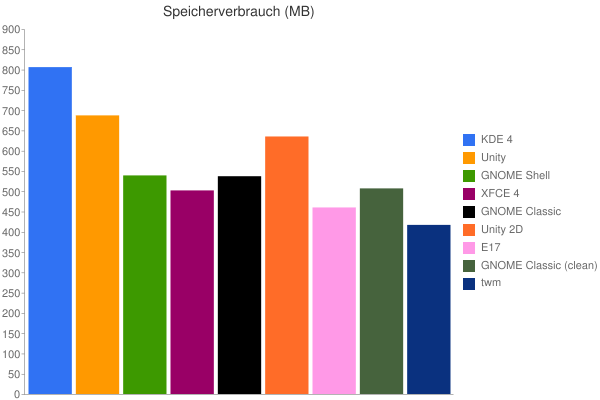
Im Grunde nichts überraschendes: KDE ist wie eh und je träge und groß (im Betrieb sieht das anders aus), Unity steht dem nicht viel nach. Nur dass E17 mit twm nicht im mindesten mithalten kann habe auch ich nicht erwartet. E17 ist inzwischen wirklich als Desktopumgebung einzuordnen.
Stabiler RSS-Feed von Roche & Böhmermann
Sunday, 14. October 2012
League of Legends Dominion Rendervideo
Saturday, 13. October 2012
Ubuntu fordert beim Download zum Spenden auf
Wednesday, 10. October 2012
Und trickst dabei.
Nachdem die Werbung im Unity-Dash doch einige Reaktionen ausgelöst hat, versucht Canoncial sich nun an einer vermeintlich harmloseren Einnahmequelle, die in der Diskussion auch desöfteren vorgeschlagen wurde: Einem einfachen Weg zu spenden. Dass ich das wieder nicht gelungen finde zeigt, in was für einer schweren Position Canonical ist.
Der Spendenaufruf ist nicht einfach prominent auf der Homepage untergebracht oder in Ubuntu selbst integriert, sondern in den Download-Ablauf integriert. Ich zeige das mal:


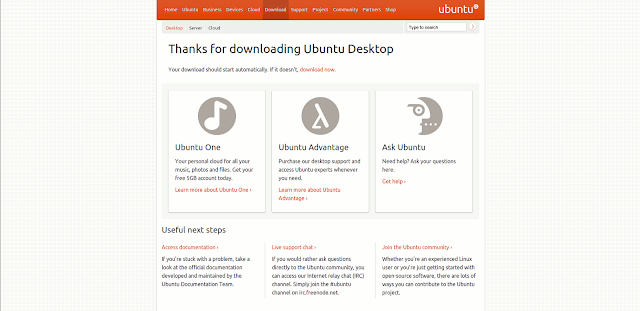
Zwischengeschaltet ist also diese Paypal-Spendenseite, deren Betrag (aber nur über die einzelnen Slider) selbst gewählt werden kann. Und diese Seite muss kritisiert werden. Denn naturgemäß ist sie darauf ausgelegt, den Besucher zum Spenden zu verleiten, aber bedient sich dabei einiger Tricks, die im Ubuntu-Umfeld meiner Meinung nach unangemessen sind.
-
Der Text dieser Seite wirkt erstmal völlig ok. "Pay what you think it's worth" enthält die Möglichkeit, dass man nicht bezahlen muss. Aber es macht es nicht völlig klar, es ist kein "Want to pay us something?". Die Intention der Headline ist "zahle etwas und variiere die Höhe" und nimmt damit den ersten Schritt "zahle überhaupt etwas" vorweg, der bei freier und kostenloser Software eigentlich der wichtigste ist.

-
Dann die beiden Buttons unten. Wobei, eigentlich sind es eben nicht zwei. Nur der Paypal-Link ist als Button gestaltet und ist noch dazu auf der üblichen Position zum Vorwärts-Klicken eines Dialogs, rechts unten. Es ist aus beiden Gründen, Position wie Gestaltung, für jeden Nutzer viel natürlicher, den Paypal-Button zu drücken und damit zu spenden. Der "Not now, take me to the download"-Link ist dagegen wesentlich weniger prominent als Link gestaltet und nicht als Button, ist auf der Position des "Zurück" oder "Abbrechen" links unten. Und er ist nicht umsonst mit einem so langen Linktext versehen. Jeden Nutzer wird es bewusste Aufmerksamkeit kosten, diesen Link statt des Paypal-Buttons zu drücken.

-
Dazu kommt das Spenden-Widget selbst. Beim Humble-Bundle, auf das Jono als Vorbild verweist, gibt man eine Höhe an und verteilt diesen Betrag dann auf die einzelnen Bereiche. Hier ist es anders. Der Nutzer verteilt Geld auf die einzelnen Bereiche und das Widget zeigt dann unten den Gesamtbetrag an, der nicht alleine editierbar ist. Ich vermute, dass so wesentlich schneller höhere Beträge zusammenkommen, weil die Ziele alle unterstützenswert erscheinen und dann die vielen kleinen Einzelspenden sich aufsummieren. Das ist einfach zu testen und genau das wird Canonical gemacht haben. Fies ist, dass der Spendenbetrag unten so aussieht als wäre er in einem editierbaren Textfeld, dabei ist es ein per CSS umgestaltetes <p>-Tag. So wird dem Nutzer Kontrolle vorgegaukelt die er nicht hat.
In die gleiche Kerbe schlägt der Fakt, dass keine Centbeträge bei einzelnen Bereichen möglich sind, wie das beim Humble-Bundle wegen der relativen Verteilung bei editierbaren absoluten Betrag dauernd vorkommt.

-
Dass die Slider bei 2$ beim Laden der Seite stehen, so also 16$ vorgeschlagen werden und trotzdem jeder einzelne Slider fast ganz links ist, dass Maximum liegt bei 125$ pro Slider, ist ein Gestaltungsmittel, um Spendenbeträge möglichst klein erscheinen zu lassen. Und das, obwohl 16$ für ein kostenloses Produkt eine sehr hohe Spende sind.

Es gibt für solche Gestaltungstricks den Begriff "Dark UI Patterns", in diesem Artikel schön erklärt. Diese Spendenseite liegt meiner Meinung nach in einem Graubereich zwischen einer validen Spendenseite mit dem notwendigen Überzeugungsversuch, der scheinbar für die weitere Existenz Canonicals notwendig ist, und einer bewussten Benutzertäuschung. Das könnte man vielen Projekten verzeihen, bei Ubuntu mit dem ganzen Menschlichkeits-Motto finde ich es äußerst unpassend.
Sand
Friday, 5. October 2012
 Ein Namenloser, der sich dann Carl nennt, wacht in der Wüste auf und erinnert sich an nichts. Er wird ausgeraubt und verliert die Orientierung, um dann Helen zu treffen und mit ihr die sich auftürmenden Probleme zu versuchen zu lösen. Gleichzeitig gab es einen Mord in einer Hippie-Kommune, jemand stahl Geld, Agenten suchen nach Atombombenteilen und irgendwie geht es um Minen und noch um einiges mehr... es ist ein ziemliches Chaos.
Ein Namenloser, der sich dann Carl nennt, wacht in der Wüste auf und erinnert sich an nichts. Er wird ausgeraubt und verliert die Orientierung, um dann Helen zu treffen und mit ihr die sich auftürmenden Probleme zu versuchen zu lösen. Gleichzeitig gab es einen Mord in einer Hippie-Kommune, jemand stahl Geld, Agenten suchen nach Atombombenteilen und irgendwie geht es um Minen und noch um einiges mehr... es ist ein ziemliches Chaos.
Wolfgang Herrndorf hat in seinem Blog ein Tagebuch über sein Leben mit Hirntumor geschrieben (das ziemlich interessant und traurig ist). Auch die Arbeit zu Sand wird erwähnt, in der Nachbarschaft von Angst, Panik und Psychose. Man merkt dem Roman das schon an. Zum einen an der Orientierungslosigkeit Carls, einzelnen Situationen wie einem Psychiaterverhör und dem generellen Chaos, das Carl in den Weg geworfen wird und mit dem er nicht fertig wird. Klare Verweise auf die Situation Herrndorfs. Zum anderen an der Sprunghaftigkeit des Romans, dass einige Geschichten nur angefangen, aber nie beendet werden, dass der Hauptplot erst nach einem Drittel des Buches halbwegs deutlich wird und auch dann noch chaotisch bleibt. Der Roman ist seltsam.
Sand hat nicht diese Großartigkeit von Tschick, die ich noch beschreiben werde. Trotzdem ist es lesenswert, wenn man die Wirrungen durchbeißt bleibt eine spannende Geschichte und einige tolle Nebenfiguren, wie den Miner mit der Ziege oder die seltsamen Autoren. Und natürlich einige absurde Dialoge und Sätze, die manchmal aber eher den "was ein seltsames Buch"-Effekt verstärken.

