./Games präsentiert Linuxspiele
Wednesday, 26. September 2018
Steam Proton funktioniert
Monday, 24. September 2018
Schau hier:

Das ist ein Screenshot von Skyrim, gespielt unter Linux. Das ging auch vorher schon, aber es war selten einfach. Diese Installation dagegen lief perfekt: Herunterladen, auf Play drücken. Steams Proton funktioniert wie angekündigt.
Ich hatte noch gar nicht verstanden, dass es auch auf meinem System schon aktivierbar ist. Das geht so:
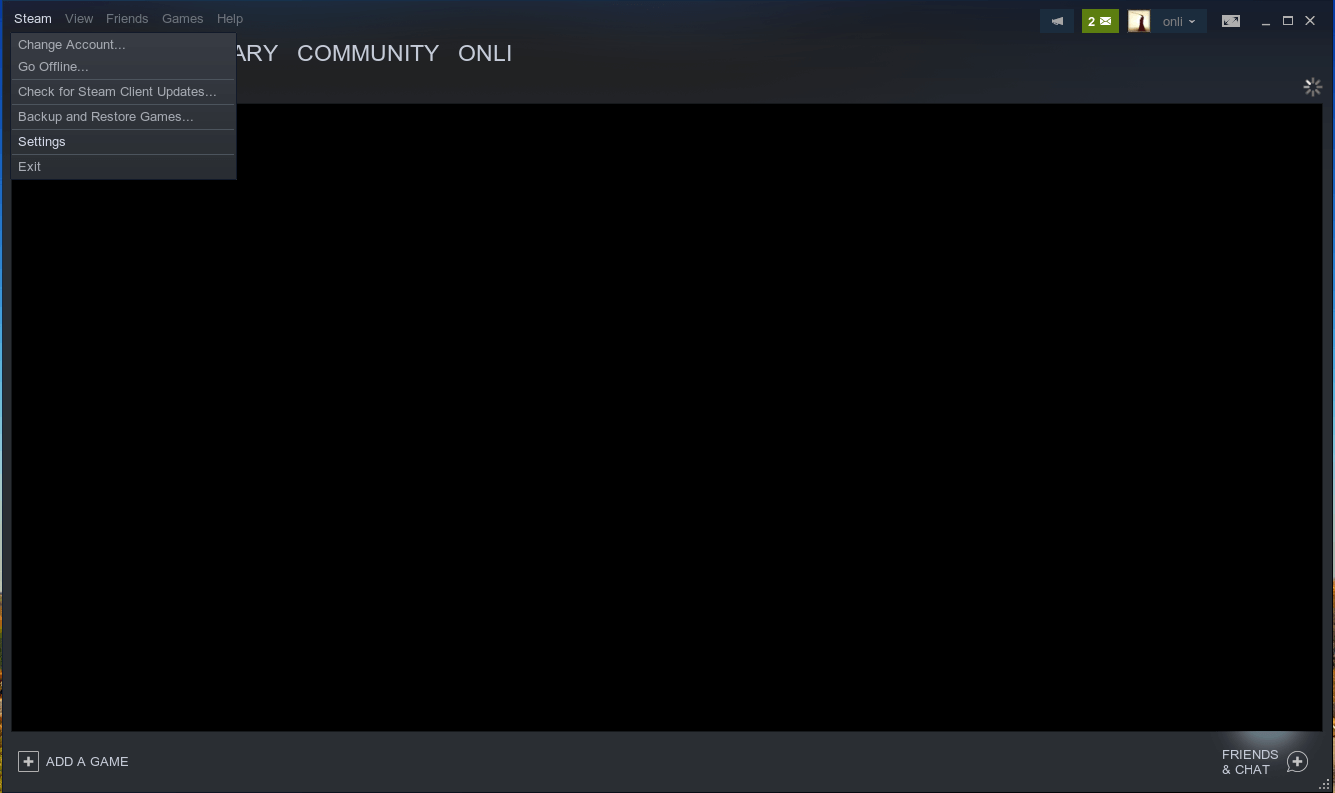
Erst Steam -> Settings auswählen. In den Einstellungen gibt es unten einen Eintrag namens Steam Play.
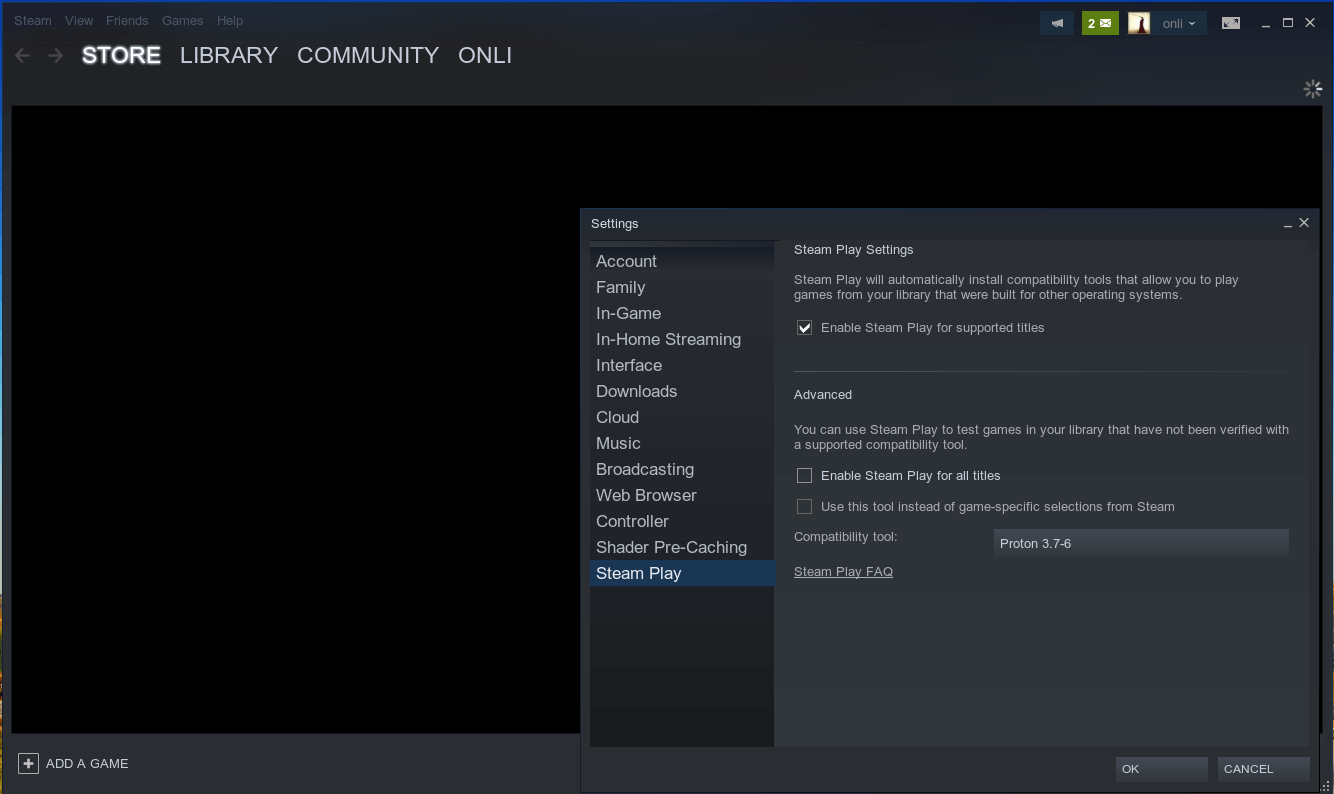
Dort kann Proton für alle Titel aktiviert werden, anstatt dass nur die Titel auf der Whitelist in der Linux-Library auftauchen.
Skyrim funktioniert, mich hat das sehr gefreut. Styx: Master of Shadows ging leider nicht, aber Proton wird sicher noch weiter verbessert werden. Auch schade: Bei Skyrim ist der Workshop kaputt, dem Steam-Forum zufolge ist das generell so. Die Mods über den Nexus zu besorgen war mir zu aufwändig, daher habe ich Skyrim dann gar nicht viel gespielt. Trotzdem, alleine dass dieses Windows-Spiel direkt startete ist ein tolles Zeichen.
Wer nicht alles selbst testen will, findet unter https://spcr.netlify.com/ eine Liste von Spielen samt ihrem Proton-Kompatibilitätsstatus. Ich werde jetzt Dishonored testen, laut der Seite soll es gut funktionieren. Das wäre ein Windows-Spiel, das ich schon eine ganze Weile spielen wollte.

Serendipity 2.1.4 und 2.2.1-alpha1 veröffentlicht
Thursday, 20. September 2018
La Défense, Paris
Thursday, 20. September 2018

Marc Ribot - "Bella Ciao" (feat. Tom Waits)
Tuesday, 18. September 2018
Wie man mit AMQP Progammbestandteile unter Ruby/Sinatra auslagern kann
Thursday, 13. September 2018
Bevor ich wie beschrieben die problematische Datenbankabfrage beim PC-Hardwareempfehler pc-kombo entdeckte hatte ich ja schon einige andere Verbesserungen probiert. Die anspruchsvollste war das Auslagern der Preisaktualisierung auf einen zweiten Server.
Ausgangssituation
Der Hardwareempfehler ist eine Ruby/Rails-Anwendung. Der reguläre Teil davon kümmert sich um das Berechnen der Empfehlungen, und natürlich um das Bauen des HTMLs der Webseite. Eine normale Web-App. Etwas ungewöhnlich ist der Threadpool. Er wird beim Start der Webanwendung erstellt.
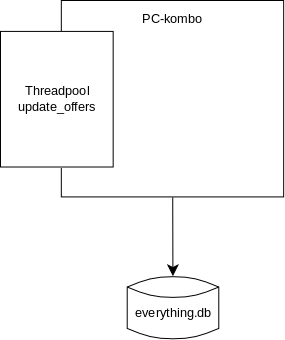
In diesem Threadpool lief der Code, der regelmäßig die APIs der eingebundenen Shops abfragt um die Preise zu aktualisieren. Das ist superwichtig für die Software, denn nur mit aktuellen Preisen können die besten PC-Builds für das Wunschbudget zusammengestellt werden.
Aber hier lag auch ein Problem: Dieses Preisaktualisieren ist keine leichtgewichtige Operation. Denn sie beinhaltet das Herunterladen, Entpacken und Durchsuchen richtig großer XML- und CSV-Dateien. Das ist besonders problematisch in einer Sprache wie Ruby, in der trotz der Threads wegen des GIL kein echter Parallelismus möglich ist. Und der Threadpool läuft ja im gleichen Prozess wie der Servercode. Das war also eine durchaus wahrscheinliche Ursache für das gelegentliche Langsamsein der Anwendung.
Diese Aufgabe sollte also ausgelagert werden.
Die Lösung: Microservices und AMQP
Anstatt die Preisaktualisierung nur in einen anderen Prozess zu verfrachten wollte ich sie auf einen eigenen Server packen. Dort sollte ein Daemon laufen, der die Preise aktualisiert und die neuen Preise zum Hauptserver sendet. So ist sichergestellt, dass der Hauptserver nur die minimale Last hat, die fertig aktualisierten Preise anzuwenden. Doch das war vor allem aufgrund von SQLite einfacher gesagt als getan. Denn das ist die genutzte und inzwischen auch schwer auswechselbare Datenbank. Der zweite Server kann also keine Verbindung zum Datenbankserver aufbauen und direkt die neuen Preise eintragen, denn es gibt beim dateibasierenden SQLite keinen Datenbankserver.
Meine erste Idee war das Replizieren der Datenbank. Es gibt da mit rqlite eine interessant aussehende Lösung, mit der man eine oder auch mehrere SQLite-Datenbanken auf mehrere Server replizieren kann. Und Änderungen werden synchronisiert. Dann hätte der zweite Server die Datenbank aktualisiert und die Änderungen wären automatisch aktualisiert worden. Doch fehlt rqlite ausgerechnet ein Ruby-Client.
So landete ich als zweites bei Bedrock. Auch diese Software repliziert SQLite-Datenbanken. Und es umgeht ziemlich genial das Client-Problem, indem es den MySQL-Client für seine Zwecke umfunktioniert, und den hat wohl jede Sprache. Doch leider war Bedrock nicht zum Laufen zu kriegen. Es hängt von gcc-6 ab, was schon alleine ein schlechtes Zeichen ist. Und dann lief es einmal kompiliert trotzdem nicht. Zudem ist unklar, ob Bedrock mit bestehenden SQLite-Datenbanken initialisiert werden kann, oder ob die Daten nachträglich eingepflegt werden müssten. Dann hilft es auch nicht, dass es wie ein ziemlich sympathisches Projekt wirkt.
Also zurück zum Kernproblem: Im Grunde sollen nur Informationen von einem Server zum anderen transportiert werden. Dafür gibt es auch andere Lösungen. So ist Sinatra wunderbar geeignet eine REST-API zu betreiben, sodass dann der zweite Server die neuen Preise POSTen könnte. Doch läuft man dann in das typische Problem beim Umbau eines Monolith in eine Microservice-Architekturen: Was tun, wenn die Ziel-API mal down ist? Wie kann auf Fehler und Netzwerkprobleme reagiert werden?
Nun sind Microservices schon fast wieder aus der Mode und es gibt für so etwas natürlich fertige Lösung. Die meines Wissens beste: Setze eine Queue zwischen die Server, welche Daten Zwischenspeichern kann. Und genau das ist AMQP mit einem Broker wie RabbitMQ.
Neue Architektur
Wir landen also hier:
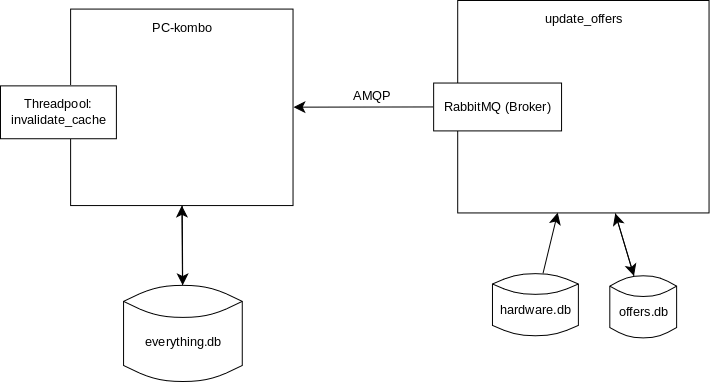
Au dem zweiten Server werden die Preise aktualisiert. Um nicht unnötig Daten zu senden werden diese auch lokal gespeichert, nur Änderungen werden an den Hauptserver gemeldet. Diese Änderungen werden an den auf dem gleichen Server laufenden RabbitMQ-Broker gepusht, über AMQP. Der Hauptserver macht ebenfalls eine AMQP-Verbindung zu diesem Broker auf. Und erhält dann über diese Verbindung über eine Queue die Preisaktualisierungen zugespielt.
Wir haben immer noch den Threadpool, aber der wird nur noch zum regelmäßigen Löschen des Datenbank-Cache genutzt und aktiviert so die Nutzung der neuen Preise.
Das tolle daran ist das Zwischenspeichern auf dem Broker. Ist pc-kombo oder die Verbindung zum Hauptserver down gehen keine Preisaktualisierungen verloren. Sie werden gesichert und dann später und geordnet gesendet, sobald die Verbindung wieder da ist. Das hat sich nun schon mehrfach als sehr praktisch erwiesen.
Der Code dafür ist relativ simpel. Genutzt wird der eine bekannte AMQP-Client für Ruby, bunny. Auf dem zweiten Server senden wir die Aktualisierung:
conn = Bunny.new("amqp://user:password@localhost:5672")
conn.start
ch = conn.create_channel
@q = ch.queue('offers', :exclusive => false)
@x = ch.default_exchange
# Notify master of new offer or offer to be deleted, but only if it is necessary
# For this to work offers.db has to be in sync on the two servers
def notifyMaster(offer)
changes = updateDB(offer)
if changes
@x.publish(offer.to_msgpack, routing_key: @q.name)
end
end
Zusätzlich und nicht zu sehen ist der Threadpool, der wieder genutzt wird um regelmäßig die Preise des Hardwaresortiments zu aktualisieren, woraufhin jedes mal notifyMaster aufgerufen wird. Sinatra läuft hier aber nicht.
Auf dem Hauptserver bauen wir in Sinatras configure ebenfalls eine Verbindung zum Broker auf, nur dass wir nichts senden, sondern empfangen:
configure do
if settings.production?
conn = Bunny.new("amqp://user:password@server2-ip:5672")
conn.logger.level = Logger::INFO
conn.start
ch = conn.create_channel
q = ch.queue("offers")
q.subscribe do |delivery_info, metadata, payload|
offer = MessagePack.unpack(payload)
Database.instance.updateOffer(offer)
end
end
end
MessagePack hat übrigens die Eigenheit, Hashes mit Symbolen in Hashes mit Strings zu verwandeln. Aus einem gesendeten offer[:abc] wird auf dem Hauptserver offer["abc"]. Darauf musste ich erstmal kommen. Ansonsten erschien es mit aber absolut logisch, für diesen Datentransport ein platzsparenderes binäres Format statt JSON zu nutzen, was wohl sonst meine übliche Wahl gewesen wäre. Ich hatte es zwischendurch auch mit protobuf probiert, kam mit der Logik dessen Ruby-Clients aber gar nicht zurecht.
Insgesamt funktioniert die neue Architektur. Und auch wenn die Preisaktualisierung schließlich nicht die Hauptursache des Performanceproblems war, hilft diese Auslagerung doch sicher dabei, die Performance nicht doch gelegentlich einbrechen zu lassen. Und auf dem zweiten Server kann ich nun besseres Monitoring einbauen, sodass ich mir der laufenden Preisaktualisierung sicher sein kann. Den ziemlich intransparenten Threadpool einzusehen war vorher nämlich schwierig.
Fazit: Nett, aber nicht ganz so ohne
Ich finde, das ist ein schönes Beispiel für den Einbau eines Microservices in einen bestehenden Monolith, bzw. die Auslagerung eines kritischen Programmbestandteils auf einen zweiten Servers. Es war allerdings auch eine größere Operation. Viele Probleme waren zu lösen: Welcher Code muss auf den zweiten Server dupliziert werden, um dort überhaupt Preise aktualisieren zu können? Ich wollte ja nicht alles neu schreiben. Letzten Endes liegt dort jetzt der gesamte Programmcode, nur wird er von einem neuen Ruby-Skript anders genutzt als vorher. Ähnliches Problem: Welche Daten müssen dupliziert werden? So war mir schnell klar, dass Benchmarkdaten nicht, dafür aber alle Hardwaredaten gebraucht werden. Dass es aber auch sinnvoll ist, die vorhandenen Preisdaten zu spiegeln um nur Änderungen zu senden (was das Datenaufkommen und damit die Last auf dem Hauptserver reduziert) wurde mir erst etwas später klar.
Von RabbitMQ habe ich einen gemischten Eindruck. Die Software funktioniert sehr solide, das Dashboard ist hervorragend gemacht. Doch war die Konfiguration gar nicht so einfach. RabbitMQ unterstützt verschiedene Arten von Queues, und mir war nicht ganz klar welche die passendste ist. Letzten Endes passte wohl der Standard. Hauptproblem der Software ist meinem Eindruck nach die Dokumentation: Sie erklärt zwar haarklein alles, schau dir nur die Installationsanleitung an! Aber sie erklärte nie genau das, was ich wissen wollte. Sie ist zu abstrakt und deckte nicht meine Fragen und Probleme ab, wie das richtige Nutzersetup um das Dashboard für einen Remotezugriff zu aktivieren, oder wie Letsencrypt-Zertifikate dieses absichern können.
Auch bunny entpuppte sich als Herausforderung. Der Client hat eine gute API und scheint angemessen ressourcenschonend zu funktionieren. Aber gelegentlich ist mir auf dem Hauptserver die Verbindung abgerissen und konnte nicht automatisch wiederhergestellt werden. Und ich finde es archaisch, zur Besprechung solcher Bugs auf Mailinglisten verwiesen zu werden. Dort konnte mir dann auch nur geraten werden, die automatische Verbindungsreparatur zu deaktivieren und sie manuell neu herzustellen, was keine tolle Lösung ist. Allerdings scheint die Verbindung stabiler zu funktionieren, seit das kernauslastende Performanceproblem gelöst ist. Vielleicht triggerte die Serverlast eine Race-Condition im Code von bunny. Das wäre natürlich ein schwer zu findender Bug.
Insgesamt war es eine lehrreiche Aktion, die glücklicherweise auch noch funktioniert hat.
Pocket-Topstories in Firefox aktivieren
Tuesday, 11. September 2018
Wenn ein fehlender Index den Server lahmlegt
Monday, 10. September 2018
In letzter Zeit hatte ich bei meinem PC-Hardwareempfehler pc-kombo mit Performanceproblemen zu kämpfen. Auf meinem Rechner lief die Anwendung lokal gut. Aber wenn mehrere Besucher auf dem Server waren brach desöfteren die Performance ein. Und zwar aller Seiten, die irgendwie auf die SQLite-Datenbank zugriffen oder kompliziertere Berechnungen durchführten.
Bis hierhin hatte ich schon einige Stellen der Serveranwendung optimiert. Die Preisaktualisierung – für die große XML-Dateien geparst werden müssen, was die Serverperformance beeinträchtigen konnte – wurde auf einen zweiten Server ausgelagert, das war die größte Aktion. Geschickter und ebenfalls mit großem Effekt: Ein Cache verhindert das unnötige Neuberechnen des besten PCs für einen bestimmten Preispunkt, solange sich die Komponentenpreise nicht geändert haben. Übersetzungen werden nun genauso im Arbeitsspeicher zwischengespeichert, was die Customize-Funktion beschleunigt. Die Berechnung der Durchschnittsgröße eines Gehäuses wird nur noch durchgeführt, wenn die Detailseite eines Gehäuses mit dem Größenvisualisierer angezeigt wird, und so weiter. All das half, doch es war nicht die Ursache des Grundproblems. Dafür wurde das nun sichtbar.
Schuld an den Performanceeinbrüchen war wohl eine einzelne Datenbankabfrage.
Der Debugweg
Nach all den vorherigen Verbesserungen stach eine Seite als noch besonders langsam heraus: Die Detailansicht einer Komponente, z.B. die des Prozessors i7-8700K. Auf dem lokalen Rechner mit Testdaten war diese Seite allerdings schnell. Ich entschloss mich, trotzdem erstmal dort zu debuggen, da der langsamste Abschnitt auf meinem Rechner ja auf dem Server noch problematischer sein und die längere Verzögerung verursachen könnte.
Zum Performance-Debuggen benutze ich ruby-prof mit ruby-prof-flamegraph. Über die Gemseite finden sich gute Erklärungen. Bei mir sieht der gekürzte Code so aus:
get '/:country/product/:type/:ean' do |country, type, ean|
if settings.development?
require 'ruby-prof'
require 'ruby-prof-flamegraph'
begin
RubyProf.start
rescue RuntimeError => re
RubyProf.stop
RubyProf.start
end
end
html = doStuff()
if settings.development?
result = RubyProf.stop
printer = RubyProf::FlameGraphPrinter.new(result)
File.open("profiling/profile_data", 'w+') { |file| printer.print(file) }
end
html
end
Die Datei profiling/profile_data kann ich dann mit flamegraph.pl visualisieren:
flamegraph.pl --countname=ms --width=1920 < profile_data > product.svg
Und das sah so aus:

Mit 73% ging der größte Teil der Rechenzeit also in Hardware#priceHistory verloren. Auf meinem Rechner war das weniger als eine Sekunde. Aber auf dem Server hatte das Laden der Seite vorher – unter Last – ~8 Sekunden gedauert. Dort würde diese Funktion wohl ebenfalls den größten Teil der Rechenzeit ausmachen, vermutete ich.
Was macht priceHistory? In Grunde führt es diesen SQL-Query aus:
SELECT * FROM pmdb.priceHistory WHERE ean = ? AND (vendor = ? OR vendor = ?) ORDER BY date ASC
Ein ziemlich simples Select. Doch der Query-Plan sah nicht gut aus:
EXPLAIN QUERY PLAN SELECT * FROM priceHistory WHERE ean = "05032037108652" AND (vendor = "vendor1" OR vendor = "vendor2") ORDER BY date ASC; 0|0|0|SCAN TABLE priceHistory 0|0|0|USE TEMP B-TREE FOR ORDER BY
SCAN TABLE priceHistory ist der problematische Teil hier. Diese Erklärung bedeutet, dass zum Erfüllen dieser Abfrage die gesamte Tabelle gelesen werden muss. Aber wie groß kann eine solche Tabelle mit etwas Preishistorie schon sein?
du -sh /home/pc-kombo/www.pc-kombo.de/productMeta.db 823M /home/pc-kombo/www.pc-kombo.de/productMeta.db
Upps. Nicht alles davon sind die Preisdaten. Aber der größte Teil.
Um also die Detailseite anzuzeigen musste der Server jedes mal eine 800MB große Tabelle auslesen. Das führte dazu, dass ein Prozessorkern für ein paar Sekunden komplett ausgelastet war (was in Sprachen wie Ruby ohne echten Parallelismus besonders problematisch ist), und auch die Festplatte wurde dadurch natürlich komplett in Beschlag genommen. Kein Wunder, dass dann auch die anderen Seitenaufrufe langsam wurden.
Hier hilft normalerweise ein Index:
CREATE INDEX priceHistory_ean_vendor ON priceHistory(ean, vendor);
Und tatsächlich:
EXPLAIN QUERY PLAN SELECT * FROM priceHistory WHERE ean = "05032037108652" AND (vendor = "vendor1" OR vendor = "vendor2") ORDER BY date ASC; 0|0|0|EXECUTE LIST SUBQUERY 1 0|0|0|USE TEMP B-TREE FOR ORDER BY
Der Index wird direkt genutzt. Und so viel bringt das in Praxis:

Alleine durch diesen einen Index ist die Preishistorie nun nicht mehr der größte Zeitfaktor in der Berechnung, sondern mit 16% einer von mehreren. Und htop bestätigt das, denn bei dem Seitenaufruf schießt die Prozessorlast des einen Kerns nun nicht mehr auf 100%, sondern bleibt irgendwo unter 10%. Dementsprechend werden auch die anderen Seiten nicht mehr ausgebremst.
Die eigentliche Ursache
Es ist fast immer problematisch, wenn ein Provisorium länger genutzt wird als geplant. Genau das ist hier passiert. Als ich die Preishistorie entwickelte wollte ich die Preise nur für wenige Wochen in der Datenbank speichern. Die eigentliche Lösung sollte eine Zeitseriendatenbank wie rrdtool sein. Solche Datenbanken können die Datenmenge begrenzen, in dem für längere zurückliegende Zeiträume Datenpunkte entfernt werden. Statt den Preis einer Grafikkarte von vor zehn Jahren alle 5 Minuten parat zu haben, speichert rrdtool dann eben nur den Durchschnittspreis einer zehn Jahre zurückliegenden Kalenderwoche. Und bestimmt wäre bei der richtigen Lösung dann auch der Index gesetzt gewesen.
Stattdessen blieb das Provisorium bestehen, bis die Datenmenge so sehr anstieg, dass der fehlende Index – dessen Fehlen beim Entwickeln mit den wenigen Datenpunkten ja noch kein Problem war – den Server ausbremsen konnte.

