Rubys FastGettext ist tatsächlich schnell
Thursday, 19. December 2019
Ich war mal wieder am Performance-Debuggen von pc-kombo. Die Seite soll schneller laden, wenn der Cache noch nicht befüllt ist, was doch immer wieder Besucher trifft. Dabei stolperte ich über diesen Abschnitt des Flamegraphs:
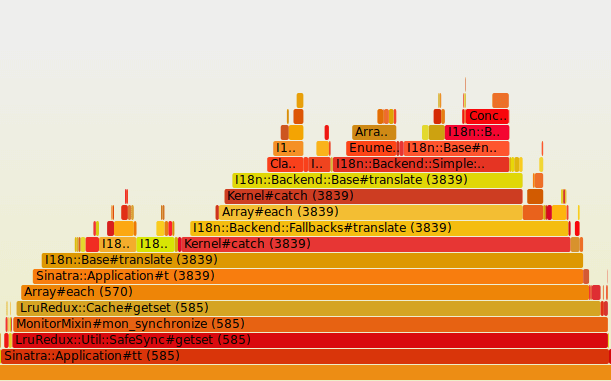
tt ist der Übersetzungshelfer, lru-redux der genutzte Cache, Grundlage das Gem i18n. Und dieser Abschnitt machte einen gewichtigen Teil des Seitenladevorgangs aus.
Also habe ich das alte Übersetzungssystem auf FastGettext umgestellt. Der Code in Sinatra sieht in etwa so aus:
helpers do
include FastGettext::Translation
def t(token, opts = {})
_(token.to_s) % opts
end
end
configure do
FastGettext.add_text_domain('pckombo', path: 'locales', type: :yaml)
end
before do
FastGettext.text_domain = 'pckombo'
if request.env['HTTP_ACCEPT_LANGUAGE']
languages = HTTP::Accept::Languages.parse(request.env['HTTP_ACCEPT_LANGUAGE'])
languages.each do |language|
case language.locale
when /en[_]*/
FastGettext.locale = "us"
break
when /de[_]*/
FastGettext.locale = "de"
break
when /fr[_]*/
FastGettext.locale = "fr"
break
when /es[_]*/
FastGettext.locale = "es"
break
end
end
end
end
Die alten yaml-Übersetzungen konnten weiterverwendet werden. So beginnt z.B. die locales/de.yml:
de:
cpu: Prozessor
Es ist also fast eine einfach so einsetzbare Alternative mit minimalen Codeänderungen.
Das Ergebnis:

Die Übersetzungen beim ersten Laden brauchen nun einen Bruchteil der Zeit. Das beste daran: Das wird nicht nur den speziellen Seitenaufruf beschleunigen den ich da betrachtet hatte, sondern generell der gesamten Webseite helfen.
Wer Übersetzungen in Ruby umsetzen muss, für den ist FastGettext ist definitiv einen Blick wert.
Categories setzen mit Rubys RSS-Modul
Wednesday, 18. December 2019
Robocop (2014)
Monday, 9. December 2019
Die Geschichte des Remakes ähnelt sehr der Geschichte der Vorlage, soweit ich mich an sie erinnere. Ein guter Polizist wird schwer verletzt. Anstatt ihn sterben zu lassen wird er in einen Robocop verwandelt, noch ein Cyborg, aber einem Großteil seiner Menschlichkeit beraubt. Was natürlich keine gute Sache ist und entsprechend schiefgeht - wobei hier mit weniger direktem Kampf um Kontrolle über ihn als vielmehr Robocop als Mittel zum Zweck.

Da gibt es dann wenige Überraschungen. Aber dafür ordentliche Actionszenen, eine geradlinige Story, keine schlechten Schauspieler. Mir gefiel, wie offensichtlich die Parallele zwischen dem Bestreben nach Robotern als Sicherheitskräfte und der schon bestehenden Praxis des Mordens per Roboter gezogen wird, zu Fox News als Propagandamaschine und dem US-Nationalismus als Faschismus.
An ein paar Stellen stolpert die Story, z.B. wenn der eigentlich als positive Figur positionierte Doktor ohne besonderen Zwang seine Prinzipien verrät und Robocop manipuliert. Wie der dann dieser Manipulation auf einmal entgehen kann, wunderbarerweise. Und wie der Oberbösewicht am Ende sich bewusst blöd verhält. Eben alles ein bisschen sehr einfach.
Fraglich auch was das Remake über das Original hinaus liefert. Und das war ja wohl schon kein besonders guter Film. Aber ich erwartete einen sehr schlechten Film, und so schlecht war das gar nicht. Eher ein kompetenter Actionfilm ohne besondere Größe mit einer mittlerweile nicht mehr originellen Story.
Arrival
Saturday, 30. November 2019
Jack Reacher
Friday, 29. November 2019
Begley: Memories of a Marriage
Wednesday, 27. November 2019
Zukunftspläne für pc-kombo: 4 Aufgaben, 3 Seiten, mehr FOSS
Thursday, 7. November 2019
Damit der Hardwareempfehler seine PC-Builds zusammenstellen kann muss pc-kombo vier Aufgaben auf einmal erledigen:
- Er muss sich eine Liste aller möglichen Komponenten zusammenstellen.
- Dann muss er herausfinden, was wieviel kostet.
- Um dann aus diesen Komponenten zu wählen zu können muss er wissen, welche Hardware wie schnell ist.
- Schließlich kann er zusammenpassende Builds zusammenstellen, also per Algorithmus optimieren und dabei bedenken, welche Hardware zusammenpasst (welche Prozessor in welches Motherboard, welche Grafikkarte in welches Gehäuse, welches Netzteil stark genug ist etc).
Ich sitze derzeit daran, das weiter aufzusplitten. Natürlich ist es jetzt schon in einer gewissen Weise aufeteilt: Die Webanwendung holt ja nicht bei jeder Anfrage alle Komponenten aus Crawlern und die Preise von den APIs, sondern erledigt vieles vorher im Hintergrund (die Preiserfassung gar per Micoservice). Aber letzten Endes ist es doch eine Seite, eine Interface, ineinander greifende Arbeitsschritte. Stattdessen möchte ich am Ende drei spezialisierte Seiten haben – eine namensgemäße Kombination von Anwendungen erschaffen.
Eine PC-Hardwaredatenbank
Sie soll alle Prozessoren, alle Grafikkarten, alle Motherboards usw umfassen, samt ihren Spezifikationen, Reviews und was sonst noch anfällt. Der Clou: Das soll offen werden. AGPL-lizenzierter Code, API-Zugriff auf die Datensammlung. Denn als ich pc-kombo startete war das Sammeln der Hardware eine unvermutete Mammutaufgabe, wofür es keinen guten Grund gibt. Das sind keine Geschäftsgeheimnisse, keine geheimhaltungswürdige Informationen. Und doch gibt es da eine kleine Industrie drumrum, die solche Daten sammelt und zu Mondpreisen verkauft.
Mit dieser Datensammlung und der API wäre nicht nur pc-kombo gedient, sondern viele andere Projekte könnten davon profitieren. Für pc-kombo und mich wäre es aber besonders praktisch: Ein zentraler Ort für die Hardwaredatensammlung. Wo ich nochmal Zeit und Arbeit darein investieren kann, die Datensammlung besser und einfacher zu gestalten. Gleichzeitig immer im Blick halten kann, auf jeden Fall auch das zu sammeln war das Empfehlungssystem mindestens braucht.
Für die Einzelansicht einer Grafikkarte habe ich bereits einen Entwurf:
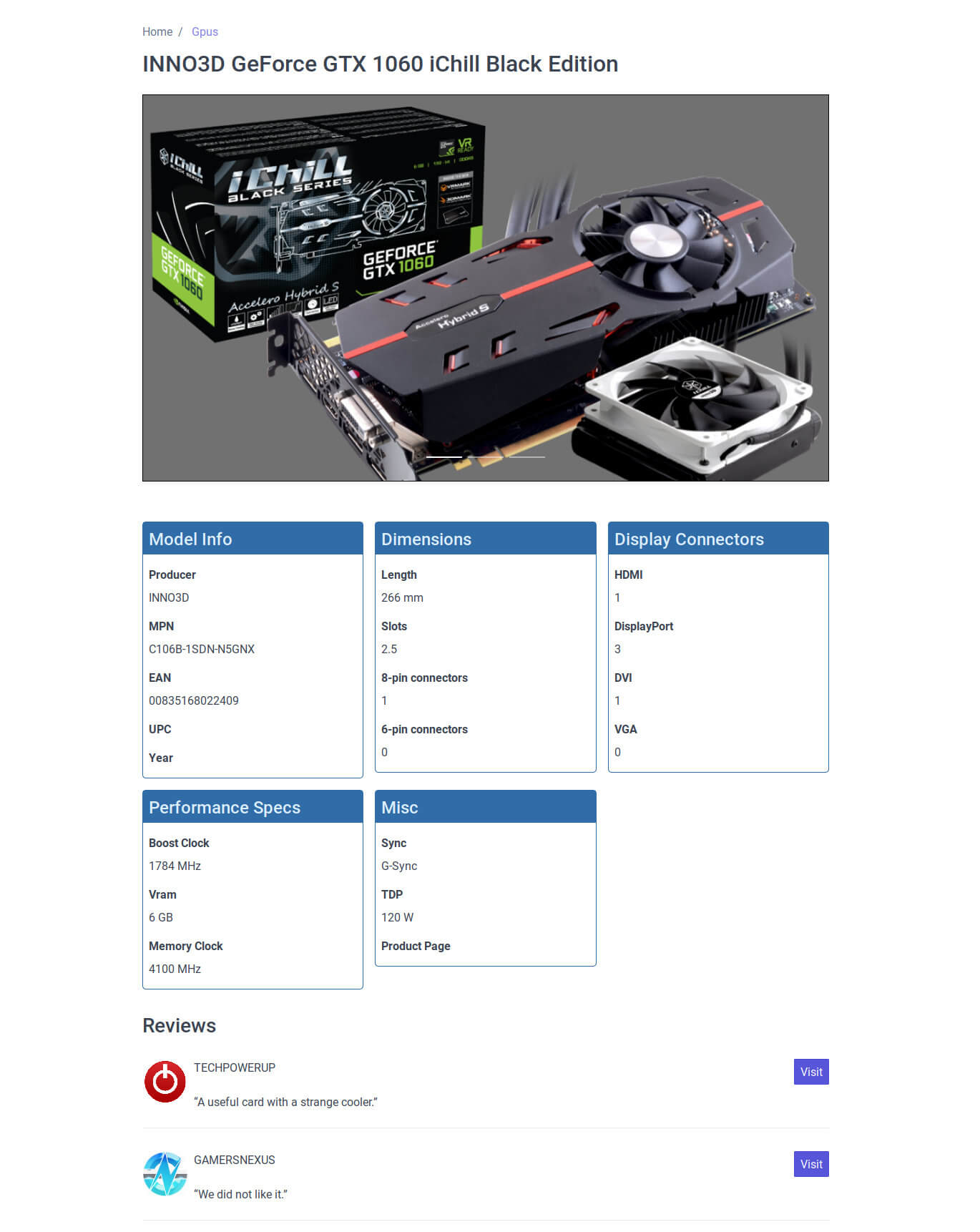
Nebenbei: Statische Seiten zu generieren entstammt als Ansatzpunkt natürlich dieser Projektidee.
Falls jemand als Mitentwickler einsteigen will, gerne! Einfach in Kontakt treten. Softwaretechnisch wird das ein statischer Seitengenerator in Ruby; Das, sowie HTML, CSS und vielleicht Javascript muss geschrieben werden, und mit dem angedachten Backend und der Datensammlung gibt es nochmal eine ganz andere Aufgabe zu bewältigen.
Eine Metabenchmarkseite
Der Metabenchmark verdient mehr Aufmerksamkeit. So oft wollen Leute wissen, wie gut Prozessoren und Grafikkarten im Vergleich mit anderen sind, welche Spiele und Anwendungen sie wie gut bewältigen. Und viel zu oft schauen sie dabei auf die falschen Daten: Künstliche Vergleiche von Spezifikationen oder Ergebnisse artifizieller Benchmarks, die über die Praxis fast nichts aussagen. Echte Benchmarks der Zielanwendungen sind der viel bessere Weg, Prozessen und Grafikkarten zu vergleichen.
Gleichzeitig ist das nicht einfach. Verschiedene Benchmarks mit teils disjunkten Teilnehmerlisten vergleichbar zu machen ist komplizierter, als ich anfangs dachte. Doch mittlerweile meine ich, das Problem algorithmisch so gut gelöst zu haben wie möglich. Wenn es mal offensichtlich falsche Ergebnisse gibt, dann liegt das mittlerweile immer an fehlenden Daten. Was sehr selten geworden ist.
Und doch beobachte ich für den Benchmark wenig Popularität, außer ich stoße Leute drauf. Deswegen soll der Metabenchmark seine eigene Seite bekommen, mit einer besseren Oberfläche, und so besser sichtbar werden. Und ebenfalls eine API bekommen, sodass andere Projekte ihn benutzen können. Wobei er selbst seine Prozessoren und Grafikkarten aus der API der Hardwaredatenbank ziehen würde.
Und wie gehabt: Ein PC-Builder
An pc-kombo würde sich laut diesem Plan erstmal gar nicht viel ändern. Die Daten der anderen Seiten benutzt er ja jetzt schon und bräuchte sie auch weiterhin. Aber mit einem kleineren Kern, besserer Automatisierung und reduzierten Ansprüchen an die Datenbank kann ich vielleicht ein paar der Verbesserungen umsetzen, zu denen ich bisher nicht kam.
Im Grunde will ich nehmen, was pc-kombo sowieso schon macht, es besser kapseln, automatisieren und zugänglich machen. Dabei mir und anderen helfen, daher sind die APIs geplant und eine freie Lizenz für die Datenbank. Es muss sich natürlich erst noch zeigen, ob ich das wirklich gebaut kriege und dann auch so wird, wie ich mir das derzeit vorstelle.
Großartig: Die neue Steam-Library
Thursday, 31. October 2019
Meine Spielesammlung ist ganz schön groß geworden! Und nicht nur mir geht es so, verglichen mit vielen anderen Sammlungen sind meine 314 Steamspiele sogar eine richtig kleine Sammlung. Was sicher vor allem daran liegt, dass ich nur relativ selten Geld in die Hand nehme um Spiele zu kaufen. Steam reagierte auf diese großen Sammlungen jetzt und hat eine neue Libraryansicht veröffentlicht (via).
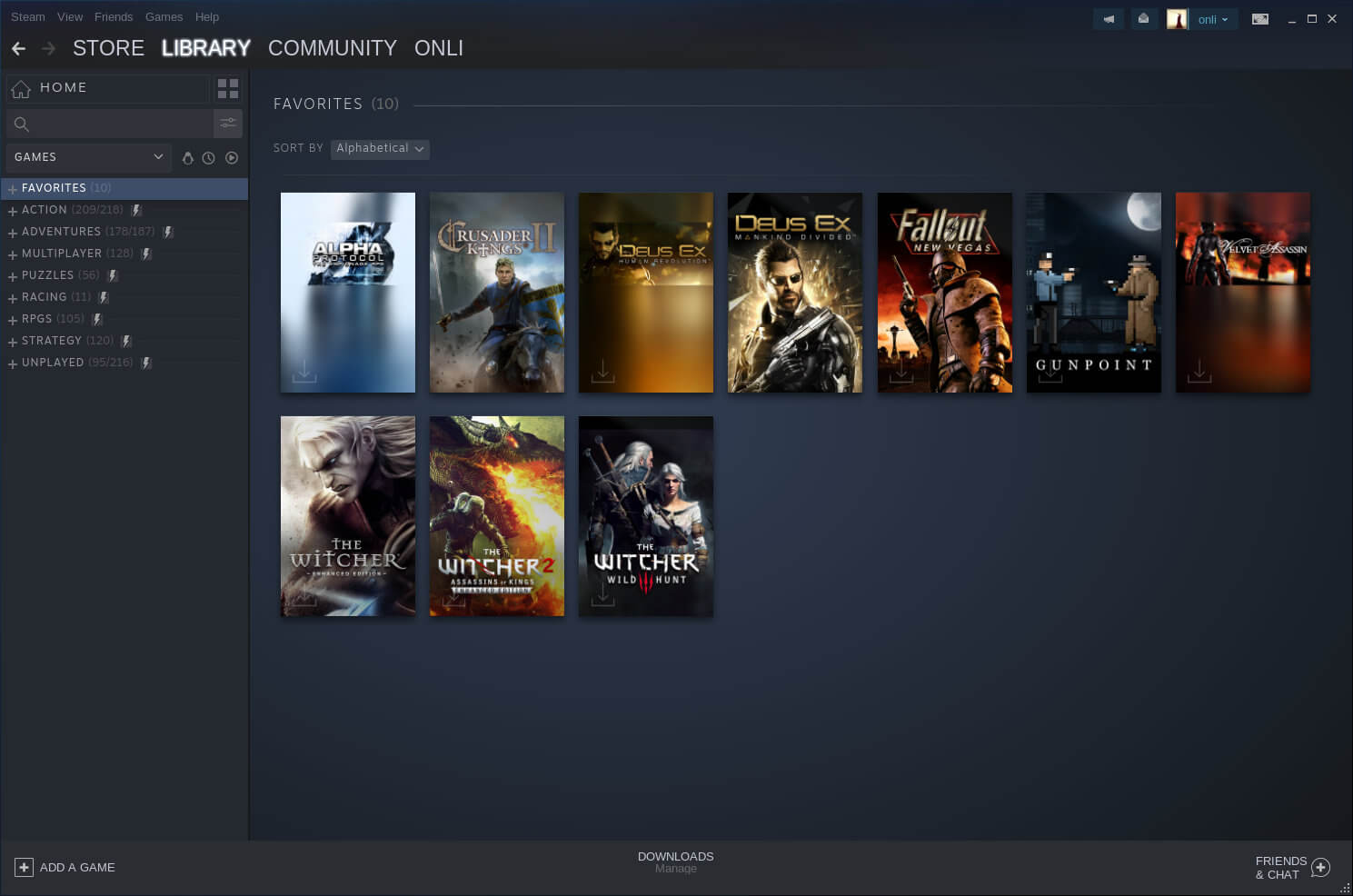
Und die ist wirklich toll geworden, denn sie erfüllt zwei erklärte Grundziele:
- Die Spiele in der Sammlung sehen jetzt besser aus. Valve verweist selbst darauf, dass Spielesammlungen in Regalen Vorbild waren. Dementsprechend sind die Spiele mit ihrem Cover gelistet und sehen einfach gut aus. Ein bisschen so, wie GOG das schon länger macht.
- Man kann die Spiele filtern und eigenen Kategorien zuweisen, eigene Regale erschaffen. Offensichtlich dabei: Favoriten. Weniger offensichtlich: Dynamische Filter! Zum Beispiel kann eine Auswahl alle Actionspiele umfassen, oder auch alle Actionspiele mit dem Tag Puzzle. Und trotz der dynamischen Auswahl kann man dann noch nachbessern, wenn zum Beispiel wie bei mir die ursprüngliche Version von Deus Ex: Human Revolution sowie Wasteland 2 nicht als RPG erkannt werden.
Auch die Einzelspielansicht wurde überarbeitet, die empfinde ich als weniger gelungen. Viel Platz geht für Aktivitäten von Entwicklern und der Community (Workshop etc) drauf, was bei vielen Spielen einfach leer ist. Immerhin sieht die Ansicht bei Spielen mit aktiver Community (wie bei Cities: Skylines) oder eigener Spielhistorie besser aus.
Was ich mir noch wünschen würde: Eine direkte Anzeige der protondb-Bewertung. Aber auch ohne diese Funktion ist die neue Libraryansicht echt nett geworden. Ein guter Anlass, einen Blick darauf zu richten was man schon alles in der eigenen Spielesammlung besitzt.
Rezo zu Seehofer
Friday, 25. October 2019
GNOME zieht gegen den Patenttroll und sammelt Spenden
Tuesday, 22. October 2019
 Letzten Monat wurde die GNOME Foundation von einem Patenttroll verklagt, der via eines offensichtlich invaliden Patents Geld für Shotwell verlangte, GNOMEs Bildverwaltungsprogramm. Wahrscheinlich kein geschickter Schachzug. Und tatsächlich wehrt sich GNOME: Die Forderungen werden verneint, das Vergleichsangebot zurückgewiesen, das Patent angegriffen.
Letzten Monat wurde die GNOME Foundation von einem Patenttroll verklagt, der via eines offensichtlich invaliden Patents Geld für Shotwell verlangte, GNOMEs Bildverwaltungsprogramm. Wahrscheinlich kein geschickter Schachzug. Und tatsächlich wehrt sich GNOME: Die Forderungen werden verneint, das Vergleichsangebot zurückgewiesen, das Patent angegriffen.
Sie schreiben es auch in der Ankündigung, aber es ist gleichzeitig der richtige und der harte Weg. Es ist kurzfristig riskanter und teurer, als sich erpressen zu lassen. Aber es sendet ein Signal an andere Patenttrolle, sogar über GNOME hinaus, das freie Software kein geeignetes Angriffsziel ist. Zu kämpfen schützt auch ganz konkret andere Projekte vor diesem Angreifer, indem seine Ressourcen gebunden werden, das Patent möglicherweise invalidiert wird. In früheren Fällen sind Betreiber solcher Patenttrolle auch schon ins Gefängnis gewandert.
Eine gute Aktion von GNOME also, völlig egal wie man zur Desktopumgebung selbst steht. Sie sammeln hier Spenden, um die Kosten tragen zu können. Ich habe mich daran gerade beteiligt. Jeder, der mit freier Software zu tun hat, sollte das wenn möglich ebenfalls machen. Und sei es nur aus Eigeninteresse.

