Umfrage zu Pipes
Friday, 20. December 2019
![]() Ein paar von euch hatten ja Pipes ausprobiert. Ich bin derzeit sehr am Überlegen, wie sich die Seite im nächsten Jahr entwickeln soll. Ich habe ein paar Ideen, will aber gar nicht zu sehr beeinflussen, denn: Ich habe zum Ideensammeln eine Umfrage angelegt. Wer ein bisschen Interesse an der Seite hat sei hiermit herzlich gebeten, die (sehr kurze!) Umfrage auszufüllen oder mir auf sonstigem Wege seinen Eindruck oder seine Ideen zukommen zu lassen.
Ein paar von euch hatten ja Pipes ausprobiert. Ich bin derzeit sehr am Überlegen, wie sich die Seite im nächsten Jahr entwickeln soll. Ich habe ein paar Ideen, will aber gar nicht zu sehr beeinflussen, denn: Ich habe zum Ideensammeln eine Umfrage angelegt. Wer ein bisschen Interesse an der Seite hat sei hiermit herzlich gebeten, die (sehr kurze!) Umfrage auszufüllen oder mir auf sonstigem Wege seinen Eindruck oder seine Ideen zukommen zu lassen.
Später schreibe ich dazu bestimmt noch etwas mehr.
Zukunftspläne für pc-kombo: 4 Aufgaben, 3 Seiten, mehr FOSS
Thursday, 7. November 2019
Damit der Hardwareempfehler seine PC-Builds zusammenstellen kann muss pc-kombo vier Aufgaben auf einmal erledigen:
- Er muss sich eine Liste aller möglichen Komponenten zusammenstellen.
- Dann muss er herausfinden, was wieviel kostet.
- Um dann aus diesen Komponenten zu wählen zu können muss er wissen, welche Hardware wie schnell ist.
- Schließlich kann er zusammenpassende Builds zusammenstellen, also per Algorithmus optimieren und dabei bedenken, welche Hardware zusammenpasst (welche Prozessor in welches Motherboard, welche Grafikkarte in welches Gehäuse, welches Netzteil stark genug ist etc).
Ich sitze derzeit daran, das weiter aufzusplitten. Natürlich ist es jetzt schon in einer gewissen Weise aufeteilt: Die Webanwendung holt ja nicht bei jeder Anfrage alle Komponenten aus Crawlern und die Preise von den APIs, sondern erledigt vieles vorher im Hintergrund (die Preiserfassung gar per Micoservice). Aber letzten Endes ist es doch eine Seite, eine Interface, ineinander greifende Arbeitsschritte. Stattdessen möchte ich am Ende drei spezialisierte Seiten haben – eine namensgemäße Kombination von Anwendungen erschaffen.
Eine PC-Hardwaredatenbank
Sie soll alle Prozessoren, alle Grafikkarten, alle Motherboards usw umfassen, samt ihren Spezifikationen, Reviews und was sonst noch anfällt. Der Clou: Das soll offen werden. AGPL-lizenzierter Code, API-Zugriff auf die Datensammlung. Denn als ich pc-kombo startete war das Sammeln der Hardware eine unvermutete Mammutaufgabe, wofür es keinen guten Grund gibt. Das sind keine Geschäftsgeheimnisse, keine geheimhaltungswürdige Informationen. Und doch gibt es da eine kleine Industrie drumrum, die solche Daten sammelt und zu Mondpreisen verkauft.
Mit dieser Datensammlung und der API wäre nicht nur pc-kombo gedient, sondern viele andere Projekte könnten davon profitieren. Für pc-kombo und mich wäre es aber besonders praktisch: Ein zentraler Ort für die Hardwaredatensammlung. Wo ich nochmal Zeit und Arbeit darein investieren kann, die Datensammlung besser und einfacher zu gestalten. Gleichzeitig immer im Blick halten kann, auf jeden Fall auch das zu sammeln war das Empfehlungssystem mindestens braucht.
Für die Einzelansicht einer Grafikkarte habe ich bereits einen Entwurf:
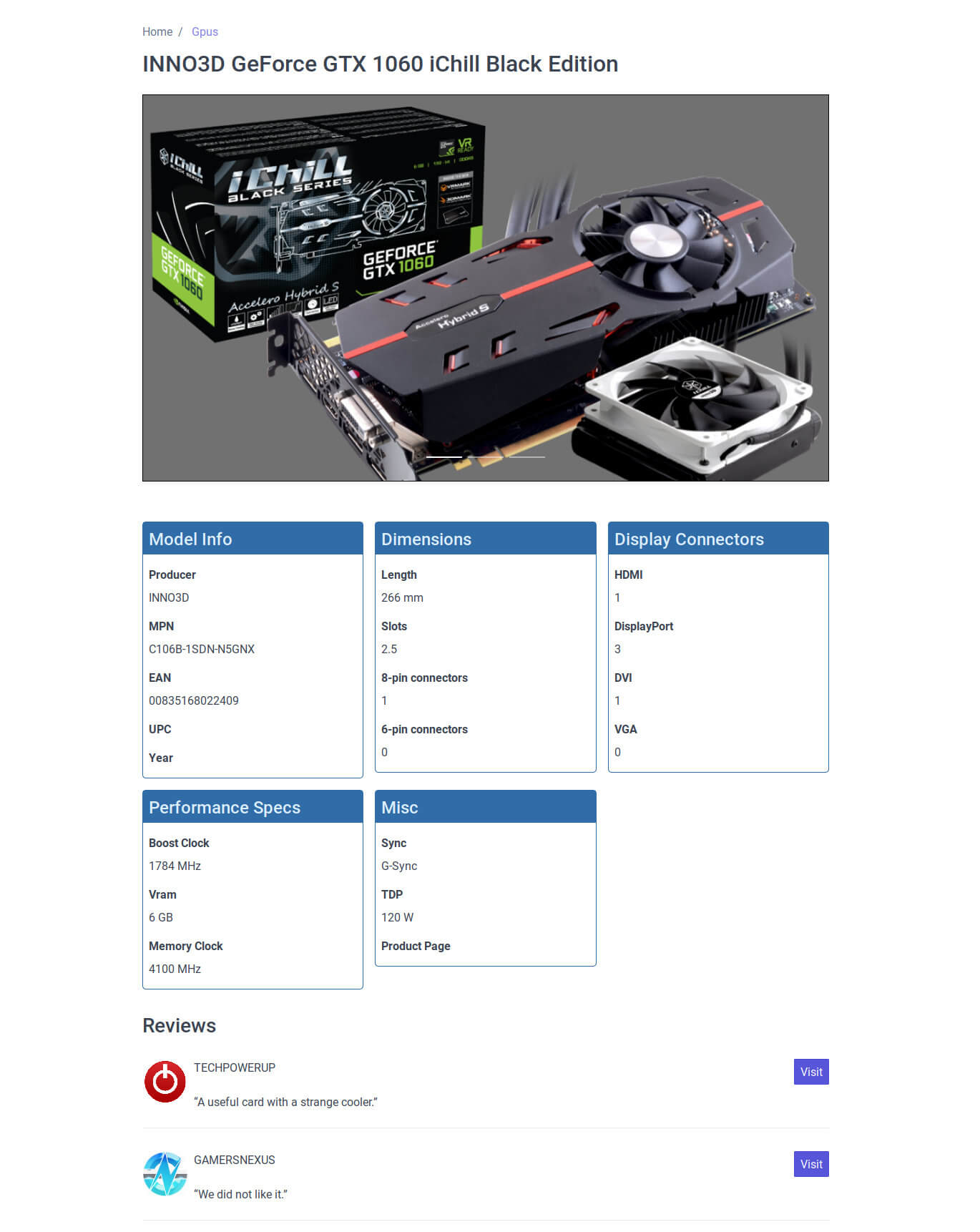
Nebenbei: Statische Seiten zu generieren entstammt als Ansatzpunkt natürlich dieser Projektidee.
Falls jemand als Mitentwickler einsteigen will, gerne! Einfach in Kontakt treten. Softwaretechnisch wird das ein statischer Seitengenerator in Ruby; Das, sowie HTML, CSS und vielleicht Javascript muss geschrieben werden, und mit dem angedachten Backend und der Datensammlung gibt es nochmal eine ganz andere Aufgabe zu bewältigen.
Eine Metabenchmarkseite
Der Metabenchmark verdient mehr Aufmerksamkeit. So oft wollen Leute wissen, wie gut Prozessoren und Grafikkarten im Vergleich mit anderen sind, welche Spiele und Anwendungen sie wie gut bewältigen. Und viel zu oft schauen sie dabei auf die falschen Daten: Künstliche Vergleiche von Spezifikationen oder Ergebnisse artifizieller Benchmarks, die über die Praxis fast nichts aussagen. Echte Benchmarks der Zielanwendungen sind der viel bessere Weg, Prozessen und Grafikkarten zu vergleichen.
Gleichzeitig ist das nicht einfach. Verschiedene Benchmarks mit teils disjunkten Teilnehmerlisten vergleichbar zu machen ist komplizierter, als ich anfangs dachte. Doch mittlerweile meine ich, das Problem algorithmisch so gut gelöst zu haben wie möglich. Wenn es mal offensichtlich falsche Ergebnisse gibt, dann liegt das mittlerweile immer an fehlenden Daten. Was sehr selten geworden ist.
Und doch beobachte ich für den Benchmark wenig Popularität, außer ich stoße Leute drauf. Deswegen soll der Metabenchmark seine eigene Seite bekommen, mit einer besseren Oberfläche, und so besser sichtbar werden. Und ebenfalls eine API bekommen, sodass andere Projekte ihn benutzen können. Wobei er selbst seine Prozessoren und Grafikkarten aus der API der Hardwaredatenbank ziehen würde.
Und wie gehabt: Ein PC-Builder
An pc-kombo würde sich laut diesem Plan erstmal gar nicht viel ändern. Die Daten der anderen Seiten benutzt er ja jetzt schon und bräuchte sie auch weiterhin. Aber mit einem kleineren Kern, besserer Automatisierung und reduzierten Ansprüchen an die Datenbank kann ich vielleicht ein paar der Verbesserungen umsetzen, zu denen ich bisher nicht kam.
Im Grunde will ich nehmen, was pc-kombo sowieso schon macht, es besser kapseln, automatisieren und zugänglich machen. Dabei mir und anderen helfen, daher sind die APIs geplant und eine freie Lizenz für die Datenbank. Es muss sich natürlich erst noch zeigen, ob ich das wirklich gebaut kriege und dann auch so wird, wie ich mir das derzeit vorstelle.
GNOME zieht gegen den Patenttroll und sammelt Spenden
Tuesday, 22. October 2019
 Letzten Monat wurde die GNOME Foundation von einem Patenttroll verklagt, der via eines offensichtlich invaliden Patents Geld für Shotwell verlangte, GNOMEs Bildverwaltungsprogramm. Wahrscheinlich kein geschickter Schachzug. Und tatsächlich wehrt sich GNOME: Die Forderungen werden verneint, das Vergleichsangebot zurückgewiesen, das Patent angegriffen.
Letzten Monat wurde die GNOME Foundation von einem Patenttroll verklagt, der via eines offensichtlich invaliden Patents Geld für Shotwell verlangte, GNOMEs Bildverwaltungsprogramm. Wahrscheinlich kein geschickter Schachzug. Und tatsächlich wehrt sich GNOME: Die Forderungen werden verneint, das Vergleichsangebot zurückgewiesen, das Patent angegriffen.
Sie schreiben es auch in der Ankündigung, aber es ist gleichzeitig der richtige und der harte Weg. Es ist kurzfristig riskanter und teurer, als sich erpressen zu lassen. Aber es sendet ein Signal an andere Patenttrolle, sogar über GNOME hinaus, das freie Software kein geeignetes Angriffsziel ist. Zu kämpfen schützt auch ganz konkret andere Projekte vor diesem Angreifer, indem seine Ressourcen gebunden werden, das Patent möglicherweise invalidiert wird. In früheren Fällen sind Betreiber solcher Patenttrolle auch schon ins Gefängnis gewandert.
Eine gute Aktion von GNOME also, völlig egal wie man zur Desktopumgebung selbst steht. Sie sammeln hier Spenden, um die Kosten tragen zu können. Ich habe mich daran gerade beteiligt. Jeder, der mit freier Software zu tun hat, sollte das wenn möglich ebenfalls machen. Und sei es nur aus Eigeninteresse.
Serendipity 2.3.1
Wednesday, 21. August 2019
Serendipity 2.3
Tuesday, 13. August 2019
 Die neue stabile Version 2.3 von Serendipity war nötig. PHP bricht einfach immer mehr als stabile Grundlage weg, überspitzt ausgedrückt – die Versionen werden weniger lange unterstützt und die neuen haben gravierende Änderungen. Also muss Serendipity angepasst werden und die Version mit diesen Anpassungen auch zeitnah erscheinen. In meinem Kopf ist 2.3 solch eine erzwungene Version. Denn nun kann Serendipity mit PHP 7.2, 7.3 und 7.4 laufen, bevor 7.1 wegbricht.
Die neue stabile Version 2.3 von Serendipity war nötig. PHP bricht einfach immer mehr als stabile Grundlage weg, überspitzt ausgedrückt – die Versionen werden weniger lange unterstützt und die neuen haben gravierende Änderungen. Also muss Serendipity angepasst werden und die Version mit diesen Anpassungen auch zeitnah erscheinen. In meinem Kopf ist 2.3 solch eine erzwungene Version. Denn nun kann Serendipity mit PHP 7.2, 7.3 und 7.4 laufen, bevor 7.1 wegbricht.
Andererseits ist das der neuen Version gegenüber gar nicht fair. Denn einige der Änderungen – weniger zur Alpha, sondern zur letzten stabilen Version – sollten ziemlich bedeutsam sein und Serendipity deutlich verbessern. Mehr noch, wenn sie in der Zukunft noch mehr Feinschliff erhalten und sich alles mehr noch zu einem organischen Ganzen zusammenfügt. Wo ich mitspielte meine ich damit unter anderem: Die Galleriefunktion (Interface), responsive images (Feintuning), den Maintenance-Modus (für Upgrades) und den neuen voku/simple-cache (Redis!).
Was auch für das Release spricht ist die Commitliste: Es sind viele Verbesserungen vieler Autoren drin. Unter anderem, jeweils ein Beispiel: Mario hat das Timeline-Theme unter PHP 7.2 repariert, Don Chambers es generell aktualisiert, Thomas hat an mehr Stellen Patches beigesteuert als mir klar war (und nebenbei den Überblick behalten auch für 2.1.x sowie das Release gestemmt!), hannob Sicherheitslücken aufgedeckt, Matthias das HTML der Bildunterschriften modernisiert, Garvin die Überarbeitung der Mediendatenbank fertiggestellt und so überhaupt erst möglich gemacht, Mitch hat den Trackbackfresser gefunden und Stephan Brunker nl2br/nl2p verbessert.
Artikel zu Cities: Skylines und den Erweiterungen
Monday, 17. June 2019
Für GamersGlobal habe ich einen Nutzerartikel zu Skylines geschrieben. Es geht um die Erweiterungen: Was taugen die und wie stark ändern sie das Grundspiel?

Das unter Linux gut laufende Spiel hat ja einige DLCs, ganz günstig sind sie aber nicht. Ich hatte für mich selbst versucht herauszufinden, welche heutzutage kaufenswert sind, aber dazu keine guten Antworten gefunden. Daher der Artikel, für den ich alle Erweiterungs-DLCs (also nicht die Radiosender und Content-Packs) nach und nach hinzufügte und eine lange Zeit spielte. Da ging wirklich viel Zeit für drauf – ich wollte gründlich sein und die Frage so fundiert wie mir möglich beantworten.
Spoiler: Die neuesten drei Erweiterungen Industries, Parklife und Campus gefielen mir gut.
Steam verbessert Shader-Performance durch Pre-Cache unter Proton
Saturday, 15. June 2019
Steam hat schon vor Jahren einen P2P Shader-Cache für OpenGL und Vulkan eingeführt. Kürzlich ist er auch für Proton/DXVK aktiviert worden, jetzt auch auf meinem Linux-Rechner in der stabilen Version von Steam.
Worum geht es hier? Was sind Shader?
DXVK wandelt Aufrufe von DirectX, der unter Windows genutzten Grafik-API, nach Vulkan um. Zusammen mit wine können damit Windows-Spiele besonders gut unter Linux laufen. Aber es werden eben auch die Shader umgewandelt, das konnte bisher einen Moment dauern.
Shader sind nicht das Level, auf dem ich programmiere und Ahnung habe. Aber sie sind meinem Verständnis nach Grafikeffekte als Code, hier ein Beispiel. Sie müssen kompiliert werden, umgewandelt werden von Code in etwas, was direkt von OpenGL bzw Vulkan nutzbar ist. Siehe auch diese Erklärung, warum das unter Linux derzeit besonders problematisch ist.
Auf jeden Fall kann es einen Moment dauern und das ist natürlich potentiell schlecht, denn dann stockt das Spiel. Für die meisten Spiele geht es hier nur um die ersten Sekunden nach dem ersten Start, aber bei anderen passiert das kontinuierlich während des Spielens.
Wie funktioniert der Cache?
Es ist geteilter Cache aller Steam-Nutzer. Nach dem Spielen analysiert Steam, welche Shader kompiliert wurden. Die werden dann hochgeladen und an die anderen Nutzer verteilt. Die sparen sich dann den Kompilierungsschritt, wodurch ihr Spiel flüssiger läuft. Und Steam kann sich jetzt auf der Ebene bewegen, auf der das Spiel lebt: Ein DirectX-Spiel, das per Proton/DXVK unter Vulkan läuft, produziert auf dem Linuxrechner Vulkan-Shader. Steam kann genau die Cachen, nicht die vorgelagerten DX-Shader (die wahrscheinlich sowieso vom Entwickler vorkompiliert wurden), die durch die Grafik-Pipeline dann nochmal umgewandelt werden müssten.
Die von Valve dafür genutzte Software heißt wohl Fossilize. Das besonders nette ist: Der Entwickler des Spiels muss dafür nichts tun.
Wenn ich das richtig verstehe landen übrigens nicht die Shader selbst im Cache, die wären grafikkartenspezifisch. Sondern eine Zwischenrepräsentation, die dann immer noch einmal kompiliert bzw von Vulkan/OpenGL interpretiert werden muss. Ich bitte um Korrektur, falls das nicht stimmt.
Welche Spiele betrifft es?
Unter Linux im Grunde alle, denn entweder nutzen sie OpenGL oder Vulkan direkt oder indirekt per DXVK. Leider zeigt Steam in der Oberfläche nicht an, welche Spiele bereits Shader-Cachedateien heruntergeladen haben. Aber es betrifft jetzt eben auch Proton-Spiele, also Windows-Spiele, die unter Linux mit Steams Kompatibilitätshelfer laufen. Ich habe Downloads für Witcher 3 und Path of Exile gesehen, Downloads der Shader werden nämlich doch angezeigt.
Funktioniert es?
Vielleicht. Ich habe gestern zum ersten mal Dark Souls 2 gestartet, da war der Cache gerade eingeführt. Ich beobachtete tatsächlich keine Ruckler, auch nicht beim ersten Laden des Hauptmenüs. Und normalerweise konnte man an dieser Stelle bei diesen Protonspielen schon bemerken, dass sie nicht nativ unter Windows laufen, durch ein Ruckeln am Anfang. Das ist jetzt wohl weg.
Es gibt da aber ein Problem: Normalerweise wird ein solcher Shader-Cache wenige MB groß sein. Aber manche Spiele wie Path of Exile benutzen sehr viele Shader und Kombinationen derselben, die (schon durch den DXVK-Zwischenschritt) auch nicht bei Spielstart, sondern während des Spielens geladen werden. Das führte bisher zu Rucklern. Und auch mit dem neuen Cache stottert es noch, mehr sogar als bei meinem ersten Spieldurchlauf – was aber eher an den Änderungen im letzten Spielupdate liegen dürfte, den neuen Gegner in den Startgebieten mit mehr grafischen Effekten. Oder da geht etwas anderes schief. Auf jeden Fall half der Cache bisher nicht. Was eben auch an seiner Größe liegen dürfte: Gestern hat Steam alleine für PoE mal eben 700MB an Shader-Cacheinhalten heruntergeladen. Jetzt gerade läuft der nächste 1,1 GB große Download. Ich bin gespannt, ob sich irgendwann der Cache auf eine finale Größe einpendelt und ob er dann die kleinen Ruckler des Spiels beseitigt.
Er könnte ja auch selbst zum Problem werden. Wenn er nicht für so große Datenmengen gebaut wurde führen bei diesem Spiel vielleicht die Cache-Abfragen selbst zu Rucklern.
Auf jeden Fall ist es grundsätzlich eine gute Sache. Es zeigt: Auch wenn Steam proprietäre Software ist, ist es eben der eine Spieleshop, der an Linuxspieler denkt. GOG, die eigentlich bessere DRM-freie Alternative, könnte so etwas gar nicht umsetzen, da ihr Linux-Client nicht existiert.
Wenn Android bei der Smartwatch "Missing Feature: Watch" anzeigt
Wednesday, 15. May 2019
Android Studio kann Anwendungen im Emulator oder auf verbundenen Geräten ausführen. Die werden dann per adb herübertransportiert. Bei der Huawei Watch 2 ging das problemlos, und auch auf dem Pixel-Smartphone gab es keinerlei Probleme. Normalerweise muss nur das Telefon oder die Uhr mit dem Kabel mit dem Laptop verbunden werden, bei der Uhr geht das über die Ladeschale. Bei der TicWatch Pro dagegen stellte sich Android Studio quer. Es sei gar keine Uhr, das ist natürlich Quatsch.
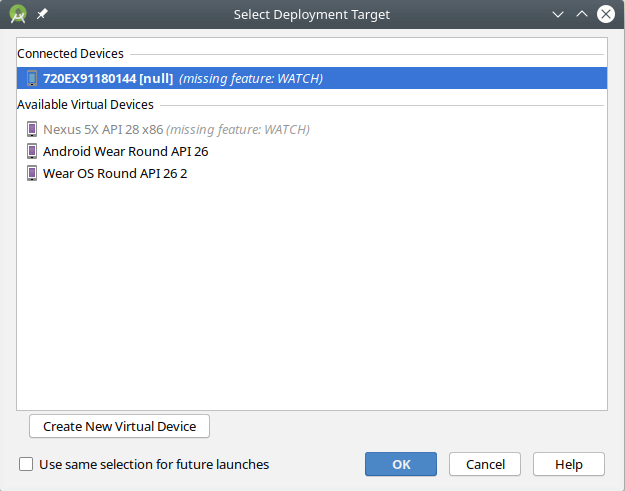
Ein adb devices erklärte das echte Problem:
malte@jet:~$ adb devices List of devices attached 720EX91180144 no permissions (user in plugdev group; are your udev rules wrong?); see [http://developer.android.com/tools/device.html]
Es fehlten die per udev vergebenen Zugangsrechte. Um sie herzustellen legt man die Datei /etc/udev/rules.d/51-android.rules mit diesem Inhalt an:
SUBSYSTEM=="usb", ATTR{idVendor}=="05c6", ATTR{idProduct}=="90bc" MODE="0666", GROUP="plugdev", SYMLINK+="android%n"
Die Werte für ATTR{idVendor} und ATTR{idProduct} verrät ein lsusb:
malte@jet:~$ lsusb ... Bus 003 Device 004: ID 05c6:90bc Qualcomm, Inc. ...
Was ich allerdings nicht weiß: Warum ist das bei manchen Android-Geräten notwendig, bei anderen aber nicht? Wird da von udev oder der Distribution (in dem Fall: Ubuntu) eine eigene Whitelist gepflegt?
Path of Exile
Tuesday, 14. May 2019
Path of Exile (PoE) ist ein kostenloses Hack'n Slay. Es ähnelt Diablo 2 sehr, greift an manchen Stellen gar explizit auf Storyelemente der Genregröße zurück, es hat aber auch viele Eigenständigkeiten.
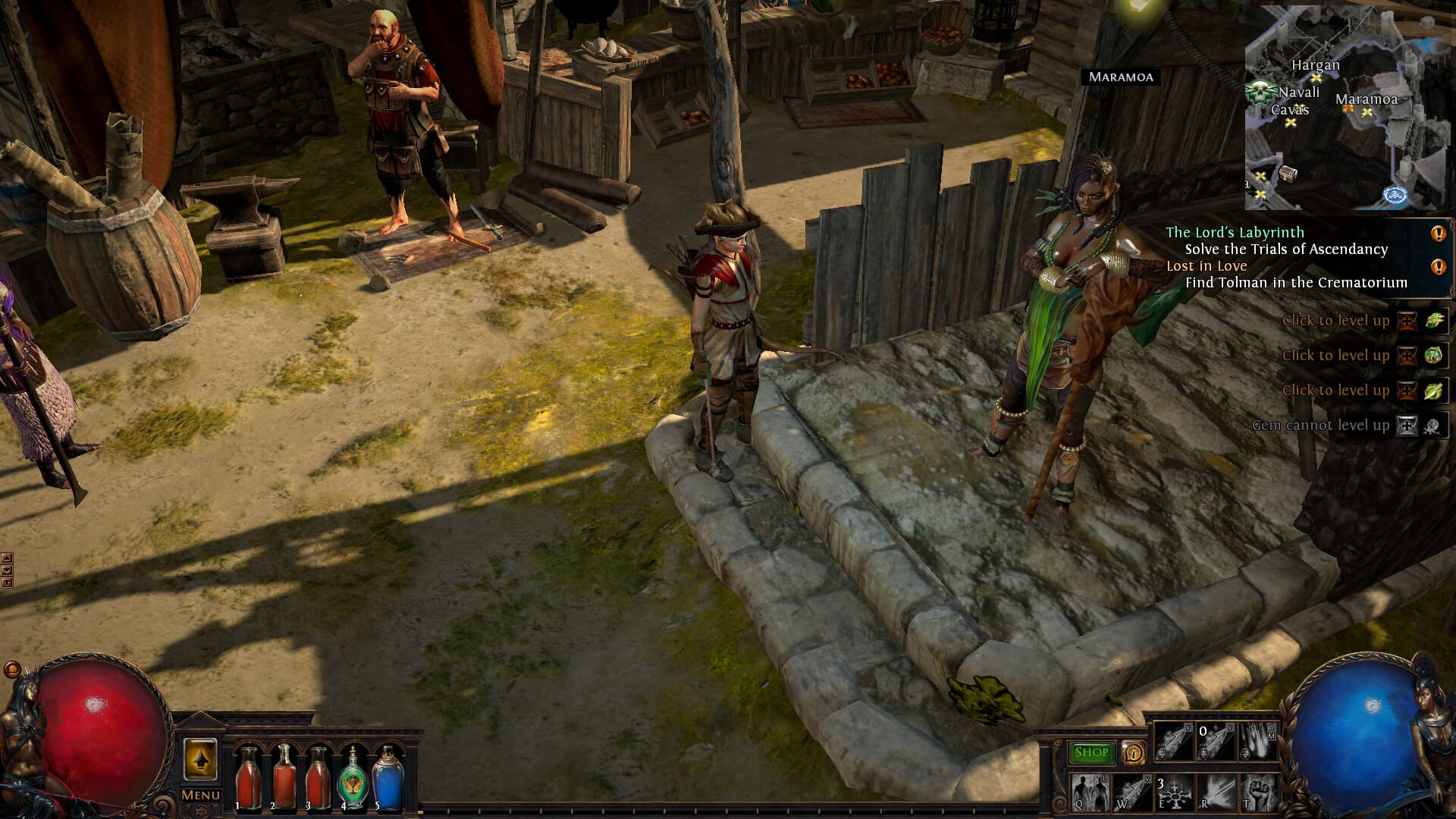
Erstmal gibt es natürlich wieder Unmengen an Gegner. Die sind in einer Spielwelt verteilt, die regelmäßig neu generiert wird. Portale verbinden diese mit der Stadt und speichern so den Spielfortschritt, in der Stadt gibt es Questgeber und Händler sowie die Truhe für Gegenstände zu schade zum Verkaufen. Aber zuerst muss ein Charakter gewählt werden. Zur Auswahl stehen nicht ganz die üblichen Archetypen, sondern leichte Abwandlungen davon, ironischerweise ist genau das mittlerweile typisch. Ich entschied mich für die oben zu sehende Jägerin (im Spiel Ranger genannt). Ein großes Böse lauert irgendwo, verseucht die Welt und verursacht die Monsterhorde – das ist der reguläre Plot, aber es fehlen die Blizzard-typischen Renderfilme, die aus der ebenso platten Handlung von Diablo 2 etwas mitreißendes gemacht haben.
Aber nun zu den Besonderheiten. Fähigkeiten wie Zaubersprüche und Spezialangriffe beispielsweise werden nicht mit Skillpunkten gelernt. Sie werden gefunden, fallen als Juwelen von toten Gegnern, liegen in Truhen oder sind Questbelohnungen. Um sie zu nutzen müssen sie in die farblich passenden Sockel der angelegten Ausrüstungsgegenstände gelegt werden.
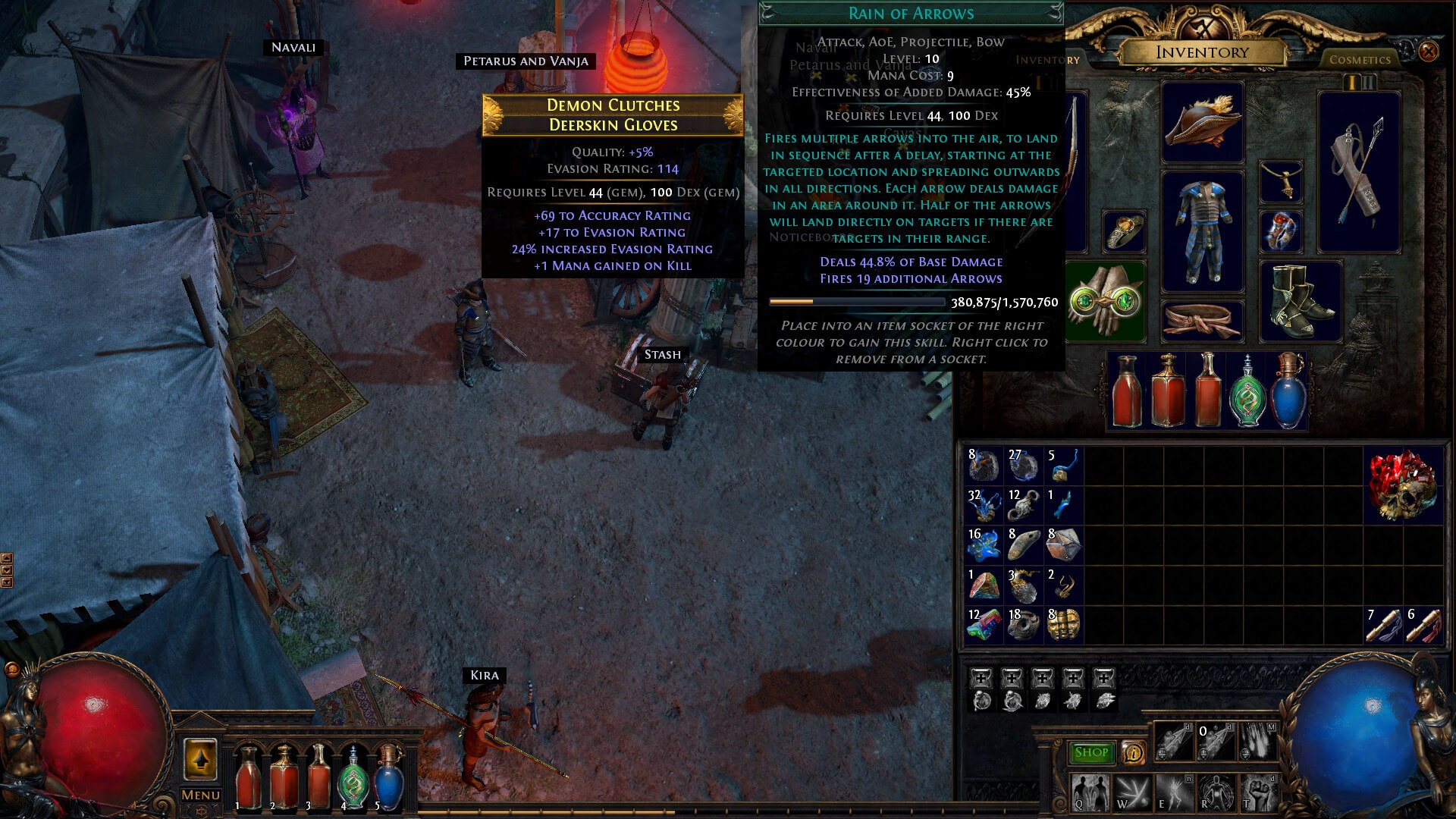
Haben diese mehrere Sockel und sind diese verbunden, können dann zusätzlich Unterstützungsjuwelen eingesetzt werden. Bei meinem Charakter war das sehr wichtig: Die Hauptattacke ist Pfeilregen, der eine ganze Fläche beharkt, verbunden ist er mit einem Schattenklon, der die gleiche Attacke mehrfach nochmal ausführt und sich selbständig seine Ziele aussucht. So konnte ich mich besonders bequem durch die Spielwelt schnetzeln. Trägt man diese Fähigkeiten mit sich herum werden sie im Laufe der Zeit stärker.
Die zweite Besonderheit ist der riesige Fähigkeitsbaum:
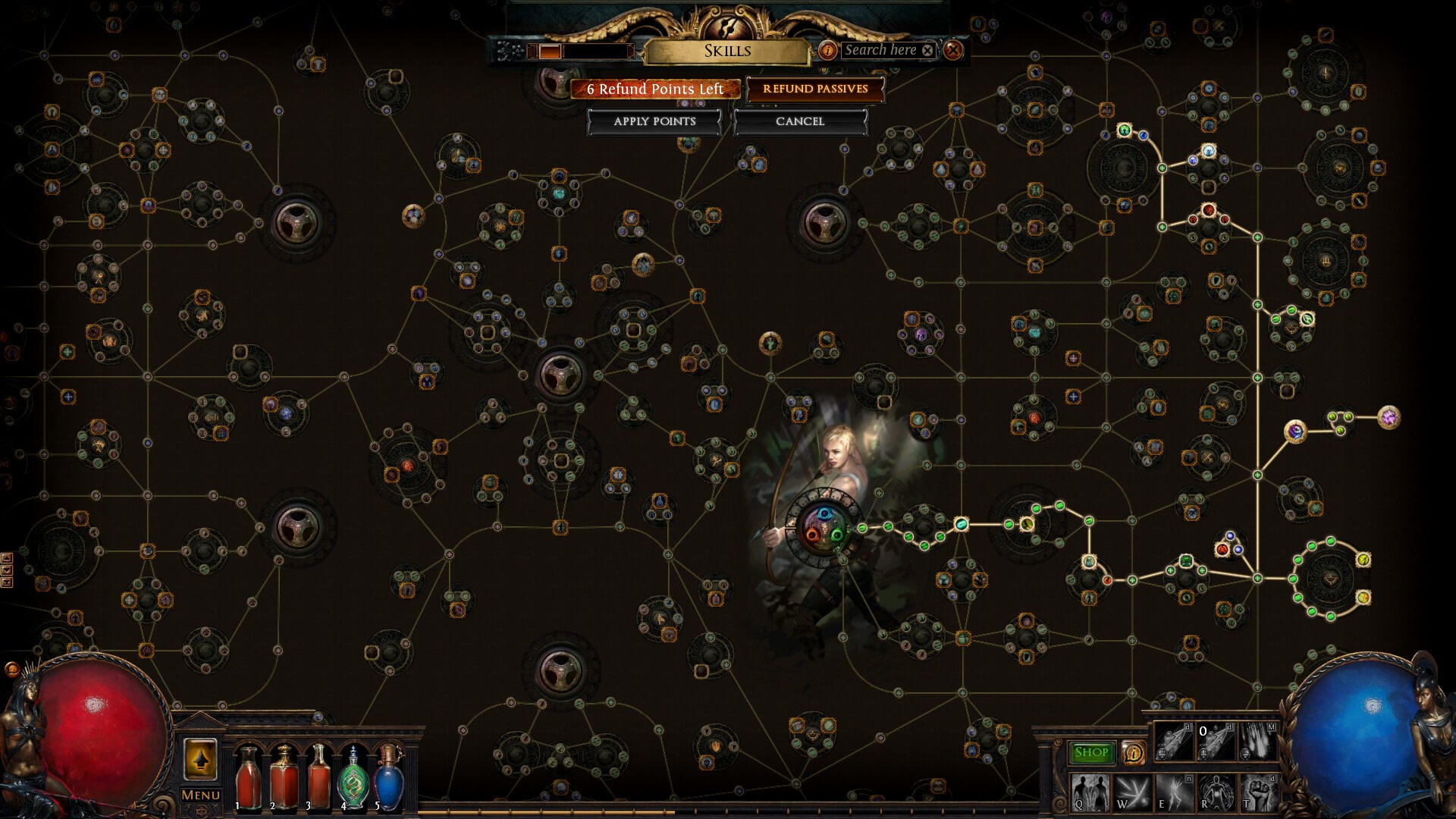
Dort werden passive Fähigkeiten gelernt. Es gibt da simple wie erhöhter Schaden und bessere Attributswerte, aber auch seltenere mit großen Vor- und Nachteilen: Beispielsweise erlernte meine Jägerin eine, die ihre Ausweichfähigkeit um 30% erhöht, Energieschild und Rüstung aber ensprechend verringert. Das beeinflusst dann welche Ausrüstung sie nutzen sollte. Die Auswahl erschlägt natürlich, aber es macht schon Spaß einen Pfad auszuwählen und in eine Richtung zu optimieren.
Desweiteren ist das Konzept besonders. Es ist Free2Play ohne Gängelungen, was besonders in Kontrast zu Diablo 2 auffällt, das als Vollpreisspiel ja keine Gängelungen nötig hatte. Und doch waren damals (historisch begründete?) direkt fühlbare Einschränkungen wie beim Platz in der Schatztruhe vorhanden. PoE hat diese nicht im gleichen Umfang und macht die Truhe dann gleich noch allen Charakteren zugänglich, sodass man einfach Gegenstände tauschen kann. Stattdessen ist das Konzept, mit optionalen Mikrotransaktionen Geld zu verdienen. Da sind dann auch Komfortverbesserungen dabei, aber der Großteil ist wohl Kosmetik. Das funktioniert nur wenn Spieler das Spiel mögen und lange spielen, daher wird versucht das Spiel durch regelmäßige Verbesserungen unendlich lange spielbar zu machen. Auf der GDC gab es dazu einen Vortrag:
Wegen dieses Vortrags habe ich das Spiel jetzt überhaupt nochmal angeschaut, vor Jahren war es schon einmal installiert. Zum einen weiß ich von League of Legends (das ich mittlerweile vor Jahren mehrere Jahre gespielt hatte), dass so etwas gut funktionieren kann und sehr spielerfreundlich ist. Es macht Spaß, ein Spiel wachsen zu sehen. Zum anderen hatte ich PoE damals ausprobiert und zwar nett gefunden, aber nicht richtig toll und trotz des Fähigkeitsbaums etwas simpel. Ich war gespannt zu sehen wie es sich seitdem entwickelt hatte.
Tatsächlich erkenne ich nur wenig wieder, zu kurz war die Spielzeit damals. Es fällt aber schon auf wie viele Mechaniken über dem regulären Spiel drüberzuliegen scheinen. Da gibt es hier Portale eines vergesslichen Geistes zu Mini-Dungeons, in denen Stabilisatoren Erinnerungsfetzen freischalten, die dann in einem Nexus auf einer Karte zu einem Pfad zusammenkombiniert werden können, um andere Dungeons mit dem Potential für besonders gute Items zu erreichen. Dann ist im zweiten Akt ein Jäger, der als Begleiter bestimmte Gegner besiegen hilft und sie dann für eine Arena einfängt. Später gibt es dann eine Spielerbehausung, in der Items magische Effekte bekommen können (und mehr? Ich habe mich mit der nicht stark beschäftigt) und eine Mine, die bestimmte Ressourcen braucht um in die Tiefe zu gelangen (=mehr Items). Und das ist noch lange nicht alles.
All das ist sichtbar gewachsen und macht das Spiel schon tiefer, aber es überlagert auch die Hauptstory. Ich habe dazu den Eindruck, dass die vielen Zusatzinhalte das Balancing zerstören. Lange Zeit zumindest ist das Spiel schlicht zu einfach, was auch an den vielen Erfahrungspunkten und besseren Ausrüstungsgegenständen dieser Zusatzbeschäftigungen liegen könnte. Später kommen dann schwierigere Inhalte, aber teilweise unvermittelt. Dass der Trial of Ascendancy schwieriger ist als die vorherige Spielwelt was angesichts des Namens und der Optionalität noch nachvollziehbar. Aber nicht okay fand ich die Unmöglichkeit, bei einem der ersten Bosse des vierten Akts nicht zu sterben, da dort zufällig verteile Feuerbälle auf die Arena niederregnen und meiner Jägerin einfach zu viel Schaden zufügten. Da konnte ich mich durchsterben, aber mit meinem Build (ohne besonders viel Leben oder Elementarschutz) konnte kein Skill der Welt das überstehen. Da war alles zuvor fairer, ein Tod immer meine eigene Schuld in der konkreten Situation.

Vielleicht wird hier langsam auch für mich spürbar, dass es unter Linux mit Proton in diesem Spiel doch noch Einschränkungen gibt. Viele Spielstunden lang lief das Spiel hervorragend. Aber erfahrene Spieler berichten, dass es später rucklig wird. Das Problem sind wohl die Shader: PoE benutzt wohl gerade später davon Unmengen, sie müssen unter Proton aber bei Bedarf gebaut werden, was zu Rucklern führe. Ruckler aber könne man sich später nicht leisten. Immerhin speichert DXVK/Proton sie auf der Festplatte zwischen, leider reicht das bei den vielen Effektskombinationen später wohl nicht mehr. Und tatsächlich bin ich jetzt trotz DXVK_USE_PIPECOMPILER=1, was etwas zu helfen schien, zuletzt nur wegen eines doofen Rucklers gestorben.
Das ist durchaus schade, denn bis ungefähr Akt 4 lief es fast immer butterweich. Und PoE hebt sich von den anderen modernen Genrevertretern ab, die ich bisher gespielt habe. Victor Vran setzte mehr auf Skillchallenges in der düsteren Spielwelt, was zwar auch Wiederspielwert, aber ein deutlich kleineres Spiel bot. The Incredible Adventures of Van Helsing hatte eine ganze Prise mehr Charme, aber viel weniger Wiederspielwert. Ähnlich Torchlight, das zwar nett ist und gute Spielelemente hat, mich dann aber irgendwann nicht mehr fesseln konnte. Hier wäre noch ein Vergleich mit Tochlight 2 und Diablo 3 interessant, vielleicht in den Kommentaren?
Für meinen Teil bin ich jetzt wohl wieder an dem Punkt angelangt, an dem das Spiel erstmal weiterreifen muss – diesmal bräuchte es keine Spielinhalte, sondern eine innovative Lösung auf Seiten von wine/DXVK/Proton (bis jetzt heißt es allerdings, das Problem sei unlösbar) oder eine native Linuxversion.

