Wächst das Internet exponentiell?
Sunday, 24. March 2013
Die Telekom will Trafficbegrenzungen für normale DSL-Anschlüsse einführen, so geht es derzeit durch die Medien. Und auf dem Telekom-Blog wird dazu ein Nicht-Dementi veröffentlicht, das nur sagt, dass solche Tarife noch nicht eingeführt wurden, ohne Distanzierung von diesen Plänen. Verwiesen wird dabei auf einen Spiegel-Artikel mit den Worten:
Auf der einen Seite wächst das Datenvolumen exponentiell.
Doch stimmt das? Der Spiegel-Artikel gibt das gar nicht so einfach einfach her.
Definition: Wachstum

Was bedeutet exponentielles Wachstum überhaupt? Bei exponentiellem Wachstum wächst etwas immer stärker, je mehr da ist, um einen festen Prozentsatz. 2^x wäre eine solche Wachstumsfunktion: 1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024 ... Man muss sich klarmachen, dass dies bei großen Werten im realen Leben extrem katastrophal sein kann - z.B. beim Ölverbrauch. Hätten wir einen festen Ölvorrat und wüchse unser Verbrauch exponentiell, stünden wir irgendwann an dem Punkt, an dem am nächsten Tick der gesamte verbliebene Ölvorrat verbraucht würde - genau das macht das Peak-Oil-Szenario so erschreckend.
Lineares Wachstum ist einfacher. Wächst etwas immer um den gleichen Wert, wächst es linear - beispielsweise wenn jemand jeden Tag eine Liegestütze mehr macht.
Polynomiales (kubisches) Wachstum (meine Vermutung: Internetwachstum entspricht eher sowas) sieht exponentiellem Wachstum ähnlich, hat aber nicht diese enorme Steigerung am Ende des Graphen. x³ ist das Beispiel im Graphen: 1, 8, 27, 64, 125, 216, 343, 512. Etwas, das immer mehr immer mehr wird, jedoch später mit immer geringerem prozentualem Wachstum.
Trafficentwicklung des Internets
Der Spiegel-Artikel gibt das exponentielle Wachstum also gar nicht so einfach her. Denn der fasst die Studie so zusammen:
Bis 2016 werde sich das durch die weltweiten Computernetze transportierte Datenvolumen vervierfachen
Eine Vervierfachung ist aber noch nicht exponentielles Wachstum. Exponentielles Wachstum ist irgendwas^x, eine Vervierfachung ist 4*x. Man sieht mein Problem auch schön auf dem (per Cisco-Tool) erstelltem Graph der Trafficprognosedaten:

Die Linie für z.B. Nordamerika sieht linear aus. Ist das im gesamten wirklich exponentielles Wachstum?
Hier noch die Daten des Gesamttraffics aus dem Whitepaper per Wolfram:
Das sind 30.734, 43.441, 54.812, 69.028, 87.331, 110.282 PB per Monat.
Und immerhin: Das Wachstum erhöht sich im Laufe der Zeit. Jährlich wächst der Traffic um 13, 11, 15, 18, 23 PB per Monat. Lineares Wachstum können wir also ausschließen. Aber ist das nun exponentiell oder polynomial?
Sieht man das am Steigungsgraph der Interpolation?
Ich nicht.
Exponentielles Wachstum ist Wachstum um einen festen Prozentsatz. Und prozentual ist das bei den gegebenen Werten Wachstum um 43%, 25%, 27%, 26%, 26%. Das ist also praktisch exponentielles Wachstum, abgesehen von der Abweichung im ersten und zweiten Jahr. Die prozentualen Wachstumswerte als Chart:
Nebenbei: Mathematisch erschlagen
Hier hatte ich zuerst die Interpolation genommen und mir mit großen x angesehen. Aber eine Interpolation per Polynom kann doch nur polynomiales Wachstum zeigen, oder? Und Wolfram kann auch nicht einfach die Fortsetzung dieser Reihe berechnen, was ich einfach mal als Hinweis auf nicht-exponentielles Wachstum nahm.
Man kann auch versuchen, das per Hand zu berechnen. Und vergessen wir dabei einfach mal den Wachstumsabfall - es geht also um das Wachstum 11, 15, 18, 23 der Werte 43, 54, 69, 87, 110.
"Es gibt ein m>1, so dass für n>=n_0 stets (a_n+1)/(a_n) >=m ist, dann liegt exponentielles Wachstum vor (man zeigt leicht a_n>= C m^n)"
-
- 54/43 >= m
- 69/54 >= m
- 87/69 >= m
- 110/87 >= m
Ja, ein solches m existiert:
Demnach wächst das Internet exponentiell. "Gibt es M>0 und p mit: für n>=n_0 ist stets a_n>M n^p, dann hat man mindestens polynomiales Wachstum."
Das ist auf deutsch die simple Überlegung: Finden wir ein Polynom, das weniger stark wächst als die gegebenen Werte?
Gut, prüfen wir das. Das zu lösende Gleichungssystem:- 43 > M * 1^p
- 54 > M * 2^p
- 69 > M * 3^p
- 87 > M *4^p
- 110 > M * 5^p
Und ja, solche p und M scheinen zu existieren:
"Gibt es M und p mit: für n>=n_0 ist stets a_n<=M n^p, dann hat man höchstens polynomiales Wachstum."
Finden wir ein Polynom, das stärker wächst als die gegebenen Werte?
- 43 <= M * 1^p
- 54 <= M * 2^p
- 69 <= M * 3^p
- 87 <= M *4^p
- 110 <= M * 5^p
Und ja, auch solche M und p gibt es:
Demnach wächst das Internet nicht exponentiell, sondern polynomial.
Und dadurch wird klar: Diese Formeln sind für echte Folgen, nicht für ein paar Werte, und helfen hier nicht weiter. Sie sagen nur, dass man die Werte sowohl exponentiell als auch polynomial fortsetzen kann.
Trafficentwicklung in Deutschland
Aber es geht in der Diskussion um Volumenbegrenzungen für DSL-Anschlüsse ja gar nicht um das ganze Internet. Es geht um DSL-Anschlüsse in Deutschland, und ohne mobiles Internet, ohne die Internetisierung der Entwicklungsländer, kann das alles ja schon wieder ganz anders aussehen. Oben im Cisco-Graph sah das Wachstum für Deutschland sehr linear aus.
Aber es geht ja ein bisschen genauer.
Aus der Advanced-Version des Cisco-Tools kommen die genauen Daten: Traffic bis 2016 ohne mobiles Internet und nur für Deutschland. Zugunsten der Telekom mische ich Business und Consumer-Segment, auch wenn es bei diesen Tarifen wahrscheinlich nur um Consumer gehen wird (so ganz sicher kann man sich eben nicht sein). Das sieht so aus
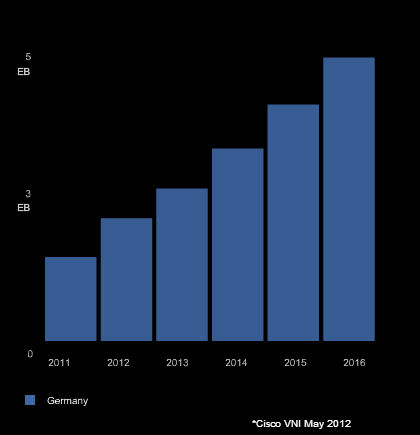
Die genauen Werte sind 1196.9, 1748.6, 2175.3, 2744.6, 3370.2, 4040.4. Das Wachstum also 552, 427, 569, 626, 670. Wieder sich steigerndes Wachstum, abgesehen von dem Einbruch auf 2013. So sieht die Ableitung der Interpolationsfunktion aus (interessante Abweichung):
Das ist Wachstum um 46%, 24%, 26%, 22%, 19%. Also: Nein, bei dem Wachstumsabfall am Ende ist das eher kein exponentielles Wachstum, sondern polynomiales.
Als Chart:
Fazit
Zuerst: Ja, die Cisco-Daten sagen aus, dass das Internet insgesamt exponentiell wächst (wenn Internet == Traffic). Nicht jedoch das deutsche Internet ohne Mobilfunk, um das es bei der DSL-Volumenbegrenzungsdiskussion geht. Aber auch das deutsche Internet wächst nicht linear, sondern es wächst der Prognose nach von 26% bis 19% im Jahr, was immer noch gewaltiges Wachstum ist. Das könnte für die Telekom tatsächlich eine Herausforderung sein - um das richtig zu bewerten müsste man die Kapazitäten kennen. Trotzdem deuten die Daten daraufhin, dass sich die Situation für die Telekom im DSL-Bereich in Zukunft eher entspannen wird, wenn das prozentuale Wachstum tatsächlich weiterhin abnimmt. Dementsprechend halte ich den simplen Hinweis auf exponentielles Wachstum des Internets für irreführend.
PS: Danke an Robert und Hartmut für eure Hilfe beim Erstellen des Artikels.
Bash: echo mit Umbrüchen
Saturday, 23. March 2013
iCTF 2013 - { netflow: [] }
Saturday, 23. March 2013
Speicherverbrauch kleiner Fenstermanager unter Precise
Thursday, 21. March 2013
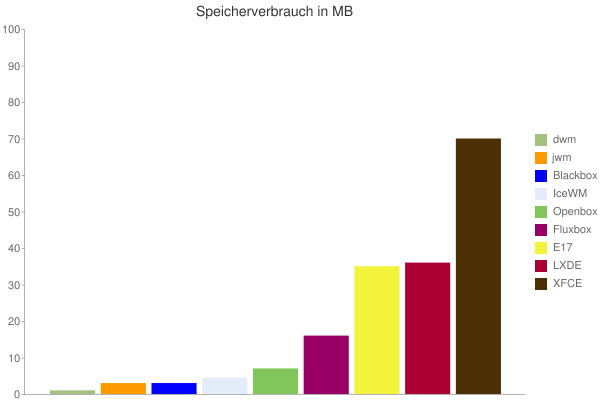
Wieder Daten, die nicht von mir sind (Quelle, via).
Die Werte sind klein, aber auch anders errechnet als die von mir damals, denn hier wurde nur der Speicherverbrauch der Fenstermanager selbst angeschaut, nicht des Gesamtsystems.
Für mich ist es interessant zu sehen, wie die Vermutungen und Trends von damals sich bewahrheitet und gehalten haben: XFCE ist immer noch deutlich speicherhungriger als die Alternativen, insbesondere LXDE, was wiederum deutlich größer ist als die echten kleinen Fenstermanager. Und E17 kann mit LXDE mithalten, was schön zu sehen ist - das war bei der letzten Messung nur zu erhoffen.
Sinatra 1.4.1: Method set not found
Thursday, 21. March 2013
Die Lügen der Spielehersteller
Tuesday, 19. March 2013
Spieler sind dumme Kiddies. Zumindest scheinen das einige Spielehersteller zu glauben, wenn man sich so ansieht, mit welcher Leichtigkeit Lügen als Verteidigung benutzt werden. Drei Beispiele:
1. EA: SimCity rechnet in der Cloud
Eigentlich ein schöner Gedanke: Das Spiel vom Spielehersteller statt auf dem eigenen Rechner berechnen lassen und auf dem eigenen PC nur ein Video davon anzeigen. Mit solchen Streaming-Angeboten wurde vor kurzem noch massiv experimentiert, immer verbunden mit Abogebühren. Also richtig nett von EA, bei SimCity jedem Kunden teure Rechenleistung in der Cloud zur Verfügung zu stellen, um so die ungeheuer aufwändige Städtesimulation auf den lächerlich unterdimensionierten Core i7-Gamer-PCs überhaupt spielen zu können...
Dies behauptete Lucy Bradshaw gegenüber Polygon:
With the way that the game works, we offload a significant amount of the calculations to our servers so that the computations are off the local PCs and are moved into the cloud. It wouldn't be possible to make the game offline without a significant amount of engineering work by our team.
Natürlich ist das Quatsch. Rechenleistung in der Cloud ist viel zu teuer, um jedem Einmalkäufer unbegrenzt lange ein Spiel laufen zu lassen. Und die Serverfarmen können sowas auch gar nicht so ohne weiteres - Spiele sind tatsächlich anspruchsvolle Aufgaben, und die typischen Spiele-PCs sind entsprechend leistungsstarke Geräte. Da müsste schon hochoptimierte Soft- und Hardware laufen, um nicht jedem Nutzer praktisch einen kompletten Spieleberechnungsserver zur Seite stellen zu müssen - und auch dann wäre das noch zu teuer.

Nein, das war nur eine Schutzbehauptung, um das wahnwitzige, kundenfeindliche und nicht funktionierende Always-On-DRM zu rechtfertigen. Sonst wäre es nicht möglich, dass das Spiel auch zeitweise ohne Verbindung läuft. Später "enthüllte" ein Insider offiziell, dass die Server nicht notwendig sind. Trotzdem war die Lüge nicht völlig uneffektiv, da kein normaler Kunde die Behauptung prüfen kann - und seither wimmelt es in Diskussionen zum Spiel von Fanboys, die artig den Unsinn wiederholen.
2. Bioware: Menüs dynamisch? Können wir nicht
DLCs sind ein wichtiges Werkzeug im Kampf um das Geld der Spieler. Mit möglichst kleinen Preisen unter der Preisgrenze des Kunden bleiben ist die eine Seite dieser Taktik. Die andere ist eine Anhebung des Verkaufspreises des Spieles: Teile des Spiels werden zurückgehalten und nachher extra verkauft. So kann ein Spiel vermeintlich zum normalen Preis von ~49,99€ angeboten werden, obwohl der reale Preis - mit den DLCs gerechnet - deutlich teurer ist.
Nicht immer stimmt das. Manchmal sind DLCs tatsächlich einfach sehr kleine Addons, die nach Fertigstellung des Spieles entwickelt wurden und einen Teilbereich sinnvoll erweitern. Sicheres Zeichen für die geplante Verarschung der Kunden ist jedoch, wenn das DLC bereits fertig vorbereitet im Hauptspiel ist.

So geschehen bei Mass Effect 3: Das zusätzliche Teammitglied des DLCs From Ashes war bereits vor dem DLC im Hauptspiel enthalten. Die Lüge lieferte dann Michael Gamble mit der Behauptung, dass dies nötig gewesen sei, um im Charakterauswahlbildschirm ihn nach DLC-Installation anzeigen zu können:
We wanted Javik to be a fully featured squad member, with deep dialogue throughout the game – and we needed him to be accessible via the character selection GUI (which you cannot simply ‘overwrite’ with DLC).
Natürlich gelogen - für einen Programmierer ist es total normal, Menüs von einem Layoutmanager dynamisch, je nach Anzahl der Elemente, zeichnen zu lassen. Wieder eine Lüge als Schutzbehauptung, diesmal eine faktisch inkorrekte technische Tatsachenbehauptung, die der dumme Kunde schon glauben wird. Nicht unpassender Höhepunkt eines Spiels, das alle Erwartungen und Versprechungen als Ende einer Trilogie komplett nicht erfüllte.
3. Westwood/EA: So planten wir das zumindest
Command & Conquer - Tiberian Sun ist ein Beispiel, das mich betrifft. Damals kaufte ich das Spiel noch vor den Tests voller Begeisterung und nahezu unbesehen, und las auf der Rückfahrt mit freudiger Erwartung die Packung. Aber so ganz stimmte nicht, was da stand. Was man heute noch findet sind Berichte über die geschönten Screenshots - die hatten Explosionen, mehr Details und mehr Effekte. Aber auch die Beschreibungstexte stimmten nicht (und dazu finde ich inzwischen keine Quellen mehr): Von deformierbaren Terrains und der Bedeutung von Tag/Nacht war da die Rede, aber nichts davon war wirklich im Spiel.

Ich habe erst deutlich später realisiert, dass der Unterschied zwischen dem, was ich erwartete, und dem eigentlich Spiel nicht meinem übermächtigen Vorstellungsvermögen, sondern den falschen Versprechungen zuzuschreiben war. Die Lüge hier war ein Versuch, mit falschen Beschönigungen die Verkaufszahlen anzukurbeln - in einer Zeit, bevor im Internet deswegen die Woge der Empörung laut gewesen wäre. Es war an den Spieletestzeitschriften, ihre Leser rechtzeitig zu warnen - was EA durch eine damals ungewöhnlich späte Herausgabe des Testmusters effektiv verhinderte.
Sicher gibt es genug weitere Beispiele, um mit falschen Versprechungen und eiskalten Lügen von Spieleherstellern einen ganzen Blog zu füllen.
Die Wehwehchen der Anderen
Friday, 15. March 2013
Unity, Adware, Mir und Rolling Releases - es gab und gibt viel zu diskutieren und zu streiten im Ubuntuland. Vielleicht beruhigt da der Blick über den Tellerrand: Auch andere Distributionen und Projekte hatten in letzter Zeit ihre Probleme, und manche davon waren unschön. Unschön genug, um Mitleid zu haben, und sich darüber zu freuen, dass dieser Kelch bisher an uns vorbeigingen.
Fedora 18: Das Anaconda-Desaster
Vielleicht hätte eine Orientierung an den Qualitätskriterien des Wikigotts Dee das verhindert (na, wie komm ich darauf?), aber so hatte Fedora 18 nach Release wohl mehr als nur kleinere Qualitätsprobleme. So viele, dass sie ein äußerst spaßiges Review provozierten. Marke:
Desktop effects
Did not work, at all. Nothing.
Aber es war der Installer Anaconda, der so richtig missraten zu sein scheint. Unter der Abschnittsüberschrift "Installation - Worst ever" finden sich Fundstücke wie
You enter a world of smartphone-like diarrhea that undermines everything and anything that is sane and safe in this most important of software configuration steps.
Wer das für übertrieben hält - und nun gerade ansetzen will, mich für die Auswahl dieses doch offensichtlich verwerflichen Reviews zu flamen - dem seien die Screenshots und die ausführliche Beschreibung ans Herz gelegt. Von
Confirmation buttons show everywhere, text is spread about, the fonts size and placement is equally chaotic. I could not think of any way to make this any uglier or less friendly.
zu
It gets worse once you hit the installation destination nonsense. You get disks represented visually. That's it. Not by their names. By identical icons with labels that refer to actual disk models. Not /dev/sda or /dev/sdb, which is what you expect. No. You get the manufacturer's model strings. And I happen to have two identical disks. So which is which? I'll give you a hint, the two disks are shown in reverse order, /dev/sdb first, /dev/sda second. What moronity.
bis
Let us not forget bad alignment, fonts and all that. And then, it says below, before continuing to the next step, but there's no next step, no buttons. Look at the lost equity. Look at the stupidity of that whole deal. If software could contract disease, it would be suffering right now from Ebola, AIDS and Typhus, all at the same time.
ist alles dabei und wird alles gezeigt.

Der geneigte Ubuntunutzer mit vagen Wissen durch Hörensagen über Fedora mag sich nun wundern: "Dass Fedora früher Probleme mit dem Installer hatte ist mir neu, woher kommen die Probleme jetzt?" Und tatsächlich ist das eine Situation, die dem kritischen Ubuntunutzer bekannt vorkommen könnte: Er wurde neu designt. Von Designern. Über einen längeren Zeitraum wurde versucht, mit geballter Designpower Anaconda einfacher, sicherer und besser zu machen - insbesondere bei Máirín Duffy habe ich das aus der Ferne von Anfang an verfolgt. Und was auf dem virtuellen Papier noch halbwegs vernünftig klang, wurde mit einer falschen Annahme hier, einer vermeintlichen Erleichterung dort und insbesondere inkonsistenter Umsetzung zu einem weithin gescholtenen Projekt, das wohl sogar das Release verzögert hat.
Java: Die unsichere Sprache
So kritisch Usability-Probleme, Machtspiele und Technologiefragen auch sein mögen - es geht immer noch kritischer. Beispielweise könnte eine Programmiersprache dafür bekannt werden, inhärent unsicher zu sein. Auf dem besten Weg ist Oracles Java-Projekt: Da nutzen Super-kritische Java-Exploits gleich zwei Bugs, und das war nicht der erste in letzter Zeit. Da bekommt selbst eine extra Webseite zum Beantworten der Frage "How Long Is It Since The Last Java Zero Day Was Discovered?" eine echte Daseinsberechtigung.
Die Propagandawirkung wird verschärft durch Oracles Hintergrund. Oracle kaufte Sun, und auch wenn Sun durchaus selbst Probleme mit der Entwicklergemeinde hatte, wurde Java in den letzten Jahren eine weitgenutzte Programmiersprache - insbesondere auch im akademischen Umfeld. Trotz all der Kritik, welche die Sprache durch ihren Boilerplate-Lastigkeit immer wieder abbekommt. Doch Oracle tat einiges dafür, weiteren Wachstumserfolg zu verhindern: Direkt wurde Google für ihre Java-Nutzung in Android verklagt, was ein äußerst interessantes API-Copyright-Urteil gegen Oracle provozierte - und viele abschreckte, Java auch nur in Betracht zu ziehen. Als ob Oracle nicht schon für seine absurde Entscheidung, Solaris proprietär zu machen, verhasst genug wäre.
Die Zero-Days-Exploits jetzt passen da nur zu gut ins Bild des eben auch unfähigen, geldgierigen und unethischen Giganten.
Und sonst?
Welches Projekt hatte noch Ärger? Um ehrlich zu sein, an Streitthemen in der Linuxgemeinde ist in den News fast immer Ubuntu beteiligt. Vielleicht habe ich ja was übersehen? Wenn ja, ab in die Kommentare damit - Ubuntu ist manchmal fürchterlich, aber das wenigstens nicht alleine.
Chrome verbieten, Zoomen zu verbieten
Thursday, 14. March 2013
Geanys/GTKs Copy & Paste reparieren
Wednesday, 13. March 2013
Erinnerungswürdige Geany-Funktionen
Tuesday, 12. March 2013
Ich programmiere lieber in einem Editor als in einer IDE. Und grundsätzlich darf ein Editor für mich so schlicht wie möglich sein - obwohl ich eine Weile emacs benutzt habe, was mir irgendwann zu kompliziert wurde. Genausowenig halte ich von vim und den absurden Tastaturverrenkungen dort (im Terminal meine Wahl: nano).
Aber Geany hat mich getäuscht und so langsam an einige Funktionen herangeführt, die ein einfacher Editor nicht hat. Beim ersten Ausprobieren gefiel mir Geany, weil es mir editorartig direkt den Text präsentierte - das Pluginsystem und integrierte Terminal konnte ich erst ignorieren, später deaktivieren. Die Tastaturbelegung war mir zugänglich, da standardkonform, und weil ich zu der Zeit gerade Eclipse nutzen musste, war die Funktions- und (inzwischen deaktivierte) Dateiübersicht - als IDE-Feature im vermeintlich schlichten Editor - auch kein Grund zur Verwunderung. Die Oberfläche lässt sich gut anpassen, so sieht meine inzwischen wirklich schlicht aus:

Trotzdem, Geany ist mehr als ein einfacher Editor. Und einige fortgeschrittenere Funktionen haben sich im Laufe der Zeit dann doch als praktisch herausgestellt:
Column select
- Mit "Shift + Alt + Pfeiltaste" kann Text spaltenweise markiert werden. Meine Quelle zeigt dafür ein schönes Beispiel: Will man aus einer Liste
/home/abc/* /home/abc/*
jeweils das /home/\w+/ entfernen, könnte man so den entsprechenden Teil markieren und löschen. Vorausgesetzt die Länge ist immer gleich. Nicht so schön wie die Sublime-Multicursor-Funktion und zugegeben selten benutzt, aber trotzdem gelegentlich praktisch.
Markierung setzen und hinspringen

Relativ oft arbeite ich in einer Datei an mindestens zwei Stellen gleichzeitig. Ist die Datei relativ klein ist das kein Problem, und ich versuche inzwischen wirklich, die LoC möglichst gering zu halten. Doch ist es ein fremdes Projekt oder auch ein älteres Serendipity-Plugin von mir (die Serendipity-Plugin-Struktur führte bei mir zu organisch wachsenden Ein-Datei-Codebasen, so hat die serendipity_event_spamblock_bayes.php immerhin 2000 Zeilen, und das ist bereits die smartifizierte Version), wird das schnell übersichtlich. Jeweils eine Markierung setzen und zwischen denen hin- und herspringen ist eine Funktion, die ich mir gewünscht habe bevor ich sie kannte: Auf den Rand neben der Zeilennummer die Markierung setzen, dann mit "Strg + ," oder "Strg + ." zur nächsten Markierung rauf- bzw runterspringen. Anker für Code, von mir noch zu selten benutzt.Zeilen duplizieren
Simpel: Ein "Strg+d" (ich hoffe, das ist die Defaultbelegung) fügt unter dem Cursor die Zeile ein, in welcher der Cursor gerade ist. Ist jedoch Text markiert, wird der markierte Text hinter den Cursor kopiert. Der Cursor bleibt jeweils genau da, wo er ist.
Eine der simplen Funktionen, die ich unter Eclipse praktisch fand und später vermisste habe, und deren Ausgestaltung unter Geany mir gut gefällt.Absatz formatieren
Bei Code hat das keinen Effekt, aber ich fand es praktisch als ich an Latex-Dokumenten gearbeitet habe: Mit "Strg+j" wird der momentane Absatz entsprechend der Zeilenlängenvorgabe umgebrochen. Verhindert, immer wieder Enter zu drücken weil die Zeile zu lang wird und das so manuell zu machen.
Suchen- und Ersetzen
Code muss manchmal überarbeitet werden, und Kleinkram wie automatische und codeweite Variablenumbenennung ist eine Stärke klassischer IDEs. Mit dem Suchen- und Ersetzen-Dialog, aufrufbar per "Strg+h", kann Geany das auch, sogar mit Regexpressions, also für wesentlich mehr als nur einfache Variablenumbennungen geeignet.

Dateiweise oder in allen geöffneten Dokumenten, schrittweise oder alle auf einmal, und wenn schrittweise, dann in unterschiedlichen Tempi - ich nutze immer noch manchmal sed für sowas, aber Geanys Funktion ist mächtig und nützlich genug, um sed desöfteren zu ersetzen. Und die Änderung schrittweise durchzuführen und so in der GUI prüfen zu können vermeidet Fehler.
Zusätzlich beherrscht Geany eine gut funktionierende Syntaxvervollständigung, die erwähnte Funktionenübersicht erweist sich immer wieder als praktisch, und wenn man wollte, könnte man mit dem Pluginsystem und dem Terminal sicher etwas anfangen. Man kann Geany aber auch als simplen Editor ohne weitere Fähigkeiten nutzen - er lädt schnell genug, um problemlos mal schnell eine Config-Datei anzupassen. Was man über Eclipse nicht gerade sagen kann.
LSR-Protest-Plugin
Friday, 8. March 2013
SimCity offline
Wednesday, 6. March 2013
Seit vorgestern ist SimCity für amerikanische Spieler geöffnet. Und natürlich brechen die Server zusammen (via).
SimCity hat einen Always-On-Kopierschutz, scheinbar recht fest in das das Spielprinzip eingebacken, mit Nachbarsstädten und Anreizen, mehrere kooperierende Städte zu bauen. Und so wie es sich anhört, leidet das Spiel darunter (zu wenig Platz pro Stadt). Klingt erstmal so, als wäre das abgesehen des Platzmangels der Versuch einer halbwegs sinnvollen Ausgestaltung, auch wenn das selbstverständlich eine reine Multiplayer-Option hätte werden können.
Aber dass die Server nicht halten ist so richtig lächerlich.
EA weiß genau, dass sie unter Beobachtung stehen. Aber wenn sie nichtmal genug Serverkapazitäten für den Start schaffen, interessiert sie das nicht. SimCity ist eine starke Marke, die Kunden werden das schon schlucken - und die Serverkapazitäten etwas geringer zu halten spart Geld. Nebenbeobachtung: Spielefirmen scheinen immer mit eigenen Servern zu arbeiten, nie frei skalieren zu können, wahrscheinlich wäre auch das zu teuer.
Das absurde: Schon der Name SimCity weckt bei mir Erinnerungen an viele Spielstunden mit SimCity 2000, verbracht zum einen an einem PC mit Modem und Kosten im Minutentakt, das natürlich aus war, und Jahre später nochmal an mehrere Sommernachmittage in einer Dachkammer gänzlich ohne Internet.
Mit Always-On-Kopierschutz gewinnt man nur die Kiddies, die ihrer Erinnerung nach Zeit ihres Lebens Internet hatten, die noch nie nach einem Umzug monatelang ohne dastanden, die noch nicht erlebt haben, wie bei anderen Spielen Server zusammenbrechen - oder solche, denen das alles scheißegal ist, für die 55 € kein Geld und eine Kaufentscheidung nie auch nur im entferntesten moralisch ist, die bei 30 Minuten Warteschlange eben auf Youtube rumtrollen. Willfährige Kunden, die schlucken was sie serviert bekommen.

