LineageOS droht Wegfall von 51 Telefonen
Monday, 15. April 2024
Erst kürzlich hatte LineageOS 21 überraschend viele Geräte auf Android 14 ziehen können, doch bereits jetzt scheint die Unterstützung von vielen dieser Telefonen ungeplant wegzubrechen.
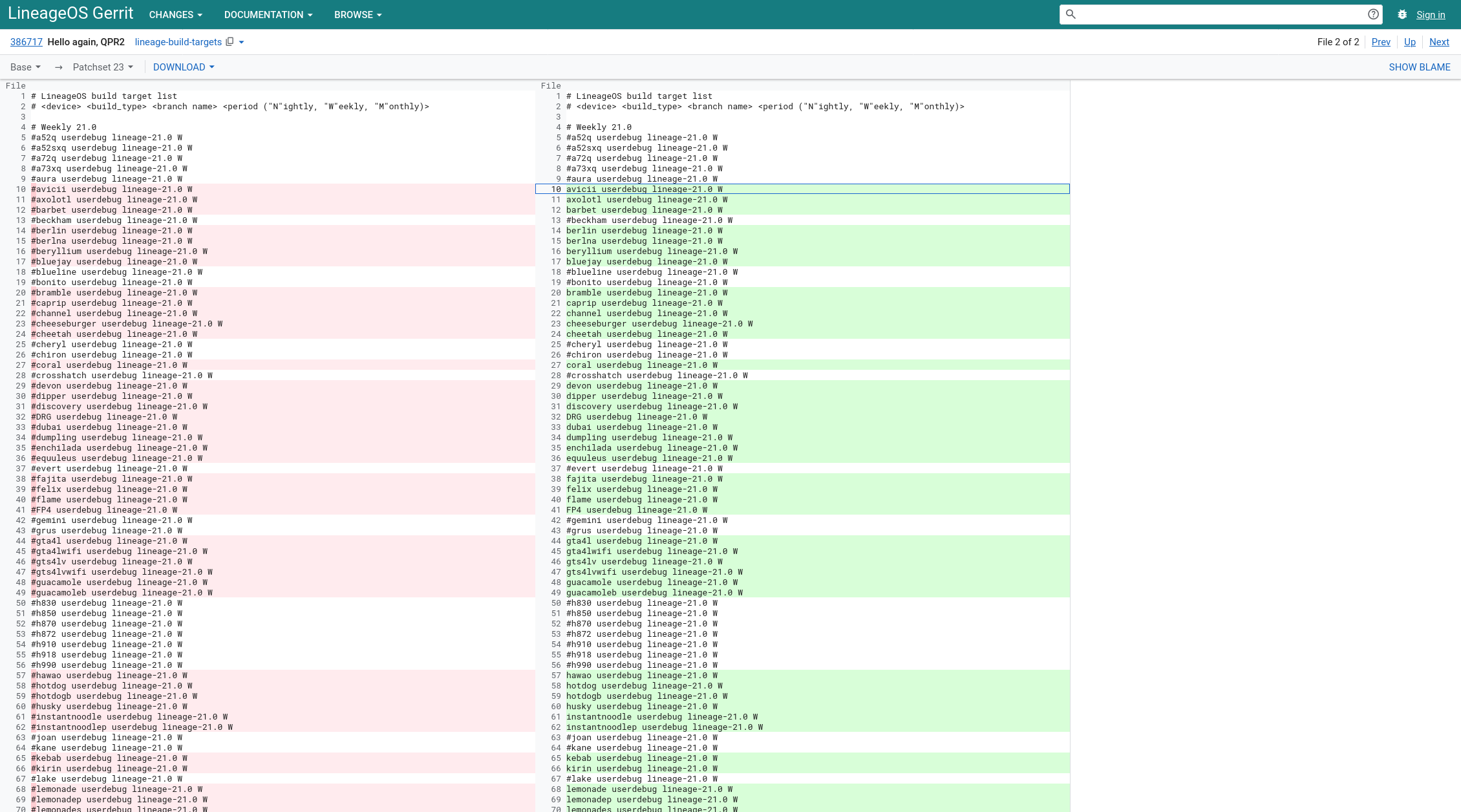
Schuld sei ein Android-Update, berichten Projektmitglieder im Lineage-Subreddit, nämlich QPR2. Diese Zwischenversion von Android 14 mit einigen neuen Funktionen ändert diesmal wohl auch gewaltig viel an der Hardwareunterstützung, entfernt alten Code, den die nun kaputten Lineage-Geräte noch benutzten. Nun muss das Projekt entscheiden wie damit umgegangen wird: Kann Code wieder eingebaut werden oder gibt es alternative Lösungen in Android, die doch funktionieren?
Was bei den betroffenen Geräten genau kaputt ist wurde nicht beschrieben. Erwähnt wurde aber RIL, eine Kompatibilitätsschicht für die Kommunikation mit dem Modem. Diese würde nun als Alternative für weggefallenen Code gebraucht. Das Problem scheint also mindestens die gesamten Telefoniefunktionen zu betreffen.
Unklar ist, ob bei einem Scheitern der Bemühungen um QPR2 die Telefone noch mit LineageOS 20 versorgt werden würden, also mit Android 13 samt Sicherheitsupdates. Das dürfte von den jeweiligen Maintainern abhängen. Für Nutzer wäre das leider sowieso nicht ideal, vor allem nicht wenn bereits LineageOS 21 installiert war: Ein Downgrade braucht normalerweise ein Löschen der Daten auf dem Gerät, bedeutet also viel Arbeit.
In der Zwischenzeit sind alle Updates gestoppt werden. Wer schonmal schauen will, ob das eigene Gerät mit relativer Sicherheit bald wieder welche bekommt, kann auf diese Liste schauen (oben im Screenshot). Die rechts grün markierten, wieder einkommentierten Codenamen (also ohne vorangestelltes #) dürften in den nächsten Tagen die neue Version ausgeliefert kriegen. Für die anderen sieht es bisher düster aus. Darunter auch mein eigenes LG G5 (als h850 in der Liste).
Android 14 auf dem LG G5 (LineageOS 21)
Tuesday, 27. February 2024
LineageOS 21 ist raus und bringt Android 14 auf viele Geräte. Darunter ist auch das alte LG G5. Meine Übersichtsseite sustaphones ist bereits aktualisiert.
Zu Jahresbeginn hatte ich das Lineage-Projekt noch kritisiert, aber auch geschrieben:
Oder wer weiß, vielleicht überrascht mich das Projekt nochmal und unterstützt nicht nur das G5 weiter, sondern geht auch ein paar der identifizierten Projektprobleme an.
Und tatsächlich wird das LG G5 ganz offiziell weiter unterstützt. Was kein Unfall ist, sondern die breite Verfügbarkeit der neuen Version laut der Releasebeschreibung an der besseren technischen Situation liegt, den Vereinfachungen bei Lineage und Android selbst. Gleichzeitig habe ich diesen Commit entdeckt, demnach ist Signature-Spoofing aktiviert und damit wenigstens einer meiner Kritikpunkte an der Projektaufstellung entschärft.
Das Update auf LineageOS 21 von LineageOS 20 war problemlos. Es gingen keine Daten verloren und es gab auch keine Probleme zu umschiffen. Die Upgrade-Anleitung trifft zu, es ist nur der Entwicklungsmodus zu aktivieren, das Recovery-System in der neuesten Version zu installieren, danach da reinzubooten und mit dem Sideload-Modus das aktuelle Image aufzuspielen. Nichtmal ein Cache musste gelöscht werden.
LineageOS 21 bzw Android 14 selbst fühlt sich nur minimal verändert an. Angenehm ist, dass das in LineageOS 20 erst spät stabilisierte Akkuladelimit weiterhin einwandfrei zu funktionieren scheint. Da hatte ich Probleme erwartet. Anrufe funktionieren, die Kamera schießt Fotos, die WLAN-Verbindung war bisher stabil. Tatsächlich scheint meinem ersten Eindruck nach die Geräteleistung sogar verbessert worden zu sein, Webseiten laden etwas schneller – aber das mag Einbildung sein. Keine Einbildung ist, dass die von Lineage mitgelieferten Anwendungen überarbeitet wurden. Gerade die Fotogalerie war da auffällig, deren Änderungen mit der stärkeren Unterteilung in Zeitabschnitte gefällt mir. Aber auch einige andere Programme sehen zumindest anders aus, integrieren sich via Material You besser in die wählbaren Systemfarben. Und sogar einer der letzten mir bekannten Bugs scheint gelöst worden zu sein, nämlich dass sich der Musikspieler beim ersten Versuch in den Hintergrund zu schalten verschluckte und die Musik abbrach (beim zweiten mal ging es dann). Das ging jetzt mehrfach direkt. Nicht schlecht!
Bei sustaphones steht das LG G5 als eines der neueren Telefone mit auswechselbarem Akku nun auch wieder ziemlich weit oben – da ist aber zu beachten, dass der Bootloader seit LGs Abschaltung der Infrastruktur nicht mehr entsperrt werden kann, daher ist es für die meisten keine echte Option. Und es ist mittlerweile eigentlich auch zu alt, kommt entsprechend an die Grenzen von Leistungsfähigkeit und Hardwarehaltbarkeit. Gleiches dürfte für das verwandte LG V20 gelten. Der Griff sollte derzeit wohl eher zum teuren Shift6MQ gehen (das ich gerne mal testen würde), oder wenn man anders als ich den fehlenden Kopfhöreranschluss verzeiht zum Fairphone 4 oder 5 (dessen Unterstützung für Android 14 dürfte folgen). Eigentlich neige ich aber zum weiteren Überbrücken mit Altgeräten, bis hoffentlich bald die EU-Regulierungen greifen und neue Telefone wieder auswechselbare Akkus bekommen. Und wer schon ein entsperrtes G5 hat bekommt das mit dem neuen Android nun vll etwas komfortabler hin.
Warum ich 2024 nach Alternativen zu LineageOS suchen werde (von Bankingapps zu Projektzustand und -ausrichtung)
Monday, 8. January 2024
LineageOS ist die große alternative Androiddistribution, die übliche Wahl, will man ein Smartphone von Googles Diensten befreien oder einem nicht mehr unterstütztem Gerät neues Leben einhauchen. Das Lineage-Projekt unterstützt eine fantastisch große Auswahl an Telefonen (und ist daher prominent auf meinem nachhaltigem Telefonfinder sustaphones vertreten) und bietet für sie ein schlankes Android mit einigen nützlichen Kernprogrammen. Ich selbst nutze LineageOS seit Jahren für mein privates Telefon und hatte sogar mit dem Spark+ von Wileyfox die kommerziellen Bemühungen des Vorgängerprojekts unterstützt. Und als Anwendungsentwickler bemühte ich mich, unsere Anwendungen auf LineageOS lauffähig zu halten und testete entsprechend auch damit.
Aber gerade in 2023 haben sich bei mir Zweifel breitgemacht, ob LineageOS für mich – und teilweise, für alle – die richtige Wahl ist. Daher habe ich schon dieses Jahr nach Alternativen geschaut und glaube, dass sich das 2024 verstärken wird.
Probleme mit Bankingapps und mehr
Tatsächlich habe ich schon ein Gerät umgestellt: Mein Zweittelefon. Das dient eigentlich als Backup und bekam mit dem Wechsel zu /e/ (vom Murenaprojekt) die Zusatzaufgabe, Anwendungen für Banken und ähnliches abzudecken. Auch deswegen fehlten die in meiner Appliste letzte Woche, neben Sicherheitsbedenken.
Auf Lineage funktionieren diese Apps nicht, nicht ohne weiteren Aufwand zumindest. Ich bin genau einer einzigen Bankapp begegnet, bei der das anders war: Consorsbank SecurePlus funktionierte den negativen Bewertungen zum Trotz direkt hervorragend. Alle anderen von mir getesteten aber kommen ohne Google-Dienste nicht zurecht.
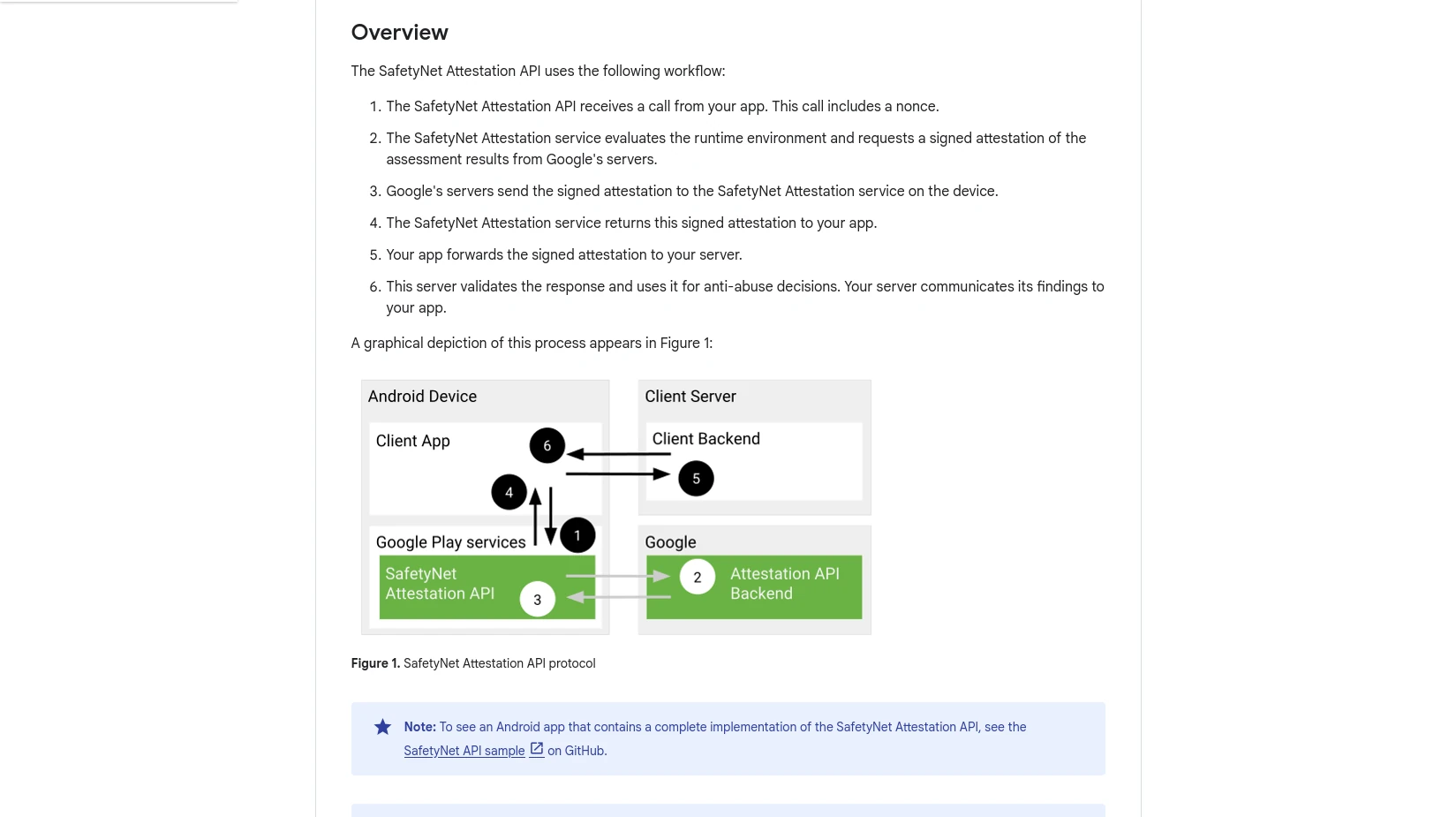
Die aber liefert LineageOS nicht. Man kann sie manuell mitinstallieren, hängt dann aber wieder am Haken von Google, wofür ein Android wie LineageOS doch genau die Alternative ist. Doch scheinbar sieht sich LineageOS selbst nicht so: Da es konsequent Begrenzungen von Android ohne Google nicht ausbügelt scheint der beabsichtigte Nutzungsmodus der mit den Googlediensten zu sein. Dass dem so ist, wird aber nicht kommuniziert.
Das zweite Beispiel dafür ist die Lokalisierungsfunktion. LineageOS kann natürlich GPS – aber GPS alleine ist eine Qual und funktionierte in der Praxis bei mir noch nie. Googles Android fängt das mit einer Funkzellenlokalisierung auf, mit der erstmal eine etwas ungenauere Position bereitsteht, GPS liefert dann nach einer Weile die Feinpositionierung. Doch LineageOS baut dieses Verhalten nicht nach.
Doch kann man das dem Projekt negativ zurechnen, liegt der Hund nicht bei Android selbst begraben? Andere Projekte zeigen: Das ginge durchaus besser. So gibt es mit microG eine Alternative zu den Googlediensten. Bei /e/ ist die vorinstalliert, deswegen funktionieren dort alle von mir getesteten Bankenanwendungen. Und für die Funkzellenlokalisierung gibt es UnifiedNlp mit einer Datensammlung von Mozilla im Hintergrund. Lineage müsste das nur einbauen.
Aber nicht nur macht LineageOS das nicht: Es macht es auf vielen Ebenen schwieriger, sowas selbst nachzuholen. Zum Beispiel, indem Signatur-Spoofing nicht unterstützt wird, was unter anderem zur Anfangszeit von Corona für die microG-Implementierung der Bluetooth-API gebraucht wurde. Und indem keinerlei Lösung für Root bereitgestellt wird. So war es mir deswegen mittlerweile unmöglich, den Rootrechte benötigenden Advanced Charging Controller richtig zu aktivieren. Früher gab es da mit Magisk eine Lösung, die entwickelte sich aber zwischendurch ebenfalls unbrauchbar und hätte nach jedem Lineage-Update eine Neuinstallation gebraucht. Für letzteres kann Lineage erstmal nichts, aber Lösungen stellt das Projekt eben auch – laut Eigenaussage gar absichtlich – nicht bereit.
LineageOS macht sich ungezwungen unsympathisch
So sitzt LineageOS schon mit seiner Ausrichtung zwischen allen Stühlen. Nur mit Googlediensten zu funktionieren spricht nur Massennutzer an, die aber installieren eher sowieso kein alternatives Android. Wenn ich aber also einen Fork mit microG benutzen müsste, warum soll ich dann überhaupt bei LineageOS bleiben und nicht ein Projekt wählen, das direkt auf solche Nutzungsprobleme eingeht?
Doch es ist mehr als das: LineageOS verbietet sogar die Diskussion über solche Probleme. Und generell über alle Probleme, die Nutzer mit dem Projekt haben könnten. So sehen die Reddit-Regeln aus:
- Do not ask for an ETA
- Do not ask whether your device will be supported
- No VoLTE requests
- Bugs should be reported by following the instructions on the wiki, they should not end up here.
- Don't ask for help with non-Lineage ROMs. We only support LineageOS, not things 'based on' LineageOS.
- Do not ask for features to be added
- No Xposed/Magisk/SuperSU/MicroG/Substratum discussion
- Please don't post links to unofficial builds or unofficial news sources. If it's not lineageos.org -- it's not official.
- Don't write news/make announcements that primarily pertain LineageOS
Nicht nur ist das unheimlich repressiv: Es ist auch in den Details wahnsinnig. VoLTE zum Beispiel, das heißt Voice over LTE. In manchen Ländern wie den USA wurde mit 3G auch gleich 2G abgeschafft, über dieses Netz liefen zuvor die Telefongespräche. Die sollten jetzt alle über LTE (4G) laufen. Das geht mit manchen Providern und manchen Geräten, aber nicht mit allen. Es ist ein absoluter Blocker für viele betroffene Nutzer, es ist existenzgefährdend für das gesamte Lineage-Projekt. Und das offizielle Supportforum verbietet nun jede Diskussion und jedwede Nachfrage darüber, denn so wird diese Regel von den Moderatoren interpretiert. Ergebnis sind frustrierte Nutzer und ein Unvermögen, innerhalb des Projekts dieses extreme Problem anzugehen.
Oder das mit den Funktionen: Nicht nur ist das genau, wie man FOSS-Projekte nicht machen sollte, weil Funktionswünsche von Nutzern elementar wichtig für jede sinnvolle Weiterentwicklung sind. Mit dieser Regel werden sogar Dokumentationswünsche geschlossen, bei denen der nachfragende Nutzer anbietet die nötige Arbeit selbst zu machen! Es ging da bei einem mir besonders übel aufstoßenden Post um ein Datum, das der Nutzer von sustaphones hätte übernehmen können, was ich ihm anbot. Nach dem Schließen des Threads wurde dann da natürlich nichts draus, die anderen Lineagenutzer sind ärmer dafür.
Und natürlich brauchen Nutzer einen Ort, um den Entwicklungsstand der nächsten Versionen zu erfragen! LineageOS kommuniziert null mit seinen Nutzern. Es gibt keine Ankündigungen einer Projektleitung (gibt es die überhaupt?), keine Entwicklertagebücher (ins Blog wurde seit einem Jahr nicht geschrieben), Pläne für die Zukunft bleiben unbekannt, es gibt gar nichts. Anstatt dann bei Nachfragen das als Problem zu erkennen und durch irgendeine Form von Transparenz ihren Quell zu beseitigen, verbieten sie mit den Fragen das Symptom.
Lineage macht es sich wirklich unnötig schwer. Es ist ein Projekt, das eine engagierte Nutzercommunity brauchen würde, es vergrault aber in seinem Hauptdiskussionsforum so effizient wie möglich jeden engagierten Nutzer. Es ist ein Projekt, das freie Software und ein befreites Android bewirbt, ist dann aber ohne Googledienste nur mit starken Einschränkungen nutzbar und tut nichts dagegen – verbietet sogar die Diskussion über existierende Lösungen. Und es ist ein Projekt, das die starke Anpassbarkeit des Systems bewirbt, blockiert aber an allen Stellen wo möglich ebendiese, wo auch immer sie über das Anpassen des Bildschirmhintergrundes hinausgeht.
Sind das die Auswirkungen der gescheiterten Kommerzialisierung? Meine Theorie ist, dass LineageOS als Cyanogen sich von allem fernhalten wollte, was Google oder Provider verärgern könnte. Deswegen war dann ein Sprechen über Restriktionsmanagement wie Safety-Net und existenzbedrohendes wie VoLTE verboten. Das ist nun nach der Pleite im Nachfolgeprojekt immer noch so, ohne dass es irgendeinen validen Grund geben würde.
Welche Alternativen es gibt
Dieses Verhalten von LineageOS schafft immerhin Platz für andere Androidprojekte. Viele davon sind Forks von LineageOS, bessern aber die Nutzungsprobleme aus. So bei dem von mir getesteten /e/, das nicht nur mit microG meine Bankanwendungen unterstützt, sondern direkt eine gute funktionierende freie App integriert hatte, um diese auch aus dem Playstore zu installieren und automatisch zu aktualisieren. Zusätzlich werden von dem System weitere Alternativen zu den Googleapps bereitstellt. Nicht alles davon funktioniert wohl perfekt, aber wenigstens ist da überhaupt ein Problembewusstsein und Lösungswille erkennbar.
Ähnlich bei CalyxOS: Auch hier ist microG und sind die Mozilla Location Services vorinstalliert, zusätzlich setzt das System einen sehr viel stärkeren Fokus als LineageOS auf Datenschutz und Sicherheit. Das macht es zu einer klar besseren Wahl, wird das genutzte Telefon denn unterstützt.
So ähnlich geht es weiter. iodé sah ich in letzter Zeit oft erwähnt, wie /e/ baut das auf LineageOS auf, kommt mit microG und minimiert besser als LineageOS die Datensendung an Google und installiert F-Droid vor. Praktisch! Volla bietet inzwischen auch microG und ein eigenständiges Bedienkonzept und scheint den Anspruch zu haben, mehr Nutzungsprobleme durch eigene Apps aufzufangen (Außeneindruck, ich habe es noch nicht getestet), so ist F-Droid ebenfalls vorinstalliert. F-Droid gibt es nochmal direkt bei DivestOS, bei dem noch dazu der Entwickler bei meinem Kontakt angenehm mit seinen Nutzern redete, zusätzlich proprietäre Blobs viel konsequenter als bei LineageOS entfernt werden.
Das alles wären direkte Alternativen, die Android mit Android ersetzen. Mein Traum eines brauchbaren Linuxtelefons (in dem Fall tatsächlich relevant: ich meine GNU/Linux) hat sich bisher nicht materialisiert. Ubuntu Touch hat aber weiterhin ein starkes Konzept, das dann irgendwann mit Waydroid eine brauchbare Alternative bieten könnte, aber noch ist es nicht so weit. Jolla mit seinem SailfishOS dürfte da etwas weiter sein und wäre ebenfalls eine Möglichkeit. Immerhin verkaufen sie ihr Betriebssystem als praxistauglich, andererseits ist es nicht frei. Und in der Ferne ist da auch noch PostmarketOS, auf eine Art der vielversprechendste Linuxansatz für Telefone, wobei wohl bisher auf keinem Gerät alltagstauglich und ich keinen Grund habe anzunehmen, dass sich das 2024 ändert.
Tatsächlich werde ich jetzt nicht direkt mein Telefon mit einer Alternative neu aufsetzen. Ich habe mich mit dem Zweittelefon als Zwischenlösung arrangiert. Aber die Lebenszeit meines G5 dürfte schon aufgrund der alternden Hardware arg begrenzt sein, außerdem war bereits die weitere Versorgung mit LineageOS 20 (=Android 13) wegen des benötigten Kernelupgrades total überraschend. Geht es da auf der einen oder der anderen Seite zu Ende, dann ist der Moment gekommen und ich werde mir eine der Alternativen zu Lineage herauspicken. Oder wer weiß, vielleicht überrascht mich das Projekt nochmal und unterstützt nicht nur das G5 weiter, sondern geht auch ein paar der identifizierten Projektprobleme an.
Denn ich denke, dass LineageOS sich als Projekt wirklich verbessern kann und solche negativen Eindrücke vermeiden könnte. LineageOS scheint an sich ein sehr erfolgreiches Projekt zu sein, ist vielgenutzt und gleichzeitig Grundlage weiterer toller Projekte. Hat es da diese Nutzerfeindlichkeit nötig? Hat ein solches Projekt wirklich keine Ressourcen für eine transparentere Projektplanung und Problematisierung? Ist es wirklich unmöglich, die im Diskussionsforum aufschlagenden Nutzer besser einzubinden? Und woher kommt diese Schockstarre angesichts existentieller Nutzungsprobleme wie VoLTE, der Unwille, Nutzungsprobleme von Android abseits der Googledienste anzugehen? Warum ist die Distanz zum Geist der Linuxdistributionen so groß?
Und um versöhnlicher zu enden: Völlig klar muss auch sein, dass eine solche Projektkritik keine Kritik an jedem einzelnen Entwickler ist. Solche Projekte entwickeln sich in unsichtbaren Gruppendynamiken. Zudem sind wahrscheinlich der Großteil der engagierten Entwickler nie im von mir stark kritisierten Redditforum auch nur lesend gewesen. Und selbst dort habe ich neben einzelnen Menschenfeinden, die nie wieder in einem solchen Projekt wirken sollten, intelligente, sympathische und freundliche Projektmitglieder beobachten können. Ich weiß aus eigener Projekterfahrung, dass nutzerfeindliche Entwickler bzw Moderatoren nicht immer direkt auffallen und von ihnen auf die anderen zu schließen völlig unfair sein kann.
Ich wünschte nur, Lineage würde gar nicht erst die Grundlage für eine solche Kritik geben und ich sie hier nicht entsprechend einordnen müssen.
Meine Appliste für Android (2023, F-Droid)
Tuesday, 2. January 2024
Ich möchte dieses Jahr im Blog mit noch etwas mehr Rückblick beginnen.
Die letzten Jahre habe ich als Entwickler professionell Mobilanwendungen geschrieben – eine absurde Geschichte, kam ich doch erst recht spät zum Smartphone. Aber entsprechend intensiv beschäftigte ich mich damit. Andererseits war meine letzte App-Auflistung 2020. Da hat sich also ein bisschen was getan, daher ist es Zeit für eine neue Liste. Die wird alphabetisch sortiert, ich überspringe die eingebauten Anwendungen die ich nicht benutze oder für nicht relevant halte.

Zum Rahmen, bei mir lief 2023 ein LG G5 mit LineageOS (plus anderen Telefonen, dazu später mal mehr) ohne Google-Dienste, die Apps entstammen daher fast alle F-Droid.
AntennaPod
Dieses Jahr bin ich zum Hören von Podcasts von Escapepod auf AntennaPod umgestiegen. AntennaPod ist ein wesentlich umfangreicheres Programm, mit viel mehr Interface und Funktionen. Das sprach mich gar nicht so sehr an, der Wechsel hatte andere Gründe: Escapepod funktionierte auf meinem Gerät nicht mehr ordentlich. Immer wieder blieb es stecken, kamen keine neuen Folgen in die App, obwohl sie tatsächlich verfügbar waren.
Es könnte sein, dass Escapepod einem Lineage-Bug zum Opfer fiel, für den ich inzwischen einen Workaround habe. Aber AntennaPod funktionierte seitdem problemlos und auch mit dem anderen Interface habe ich mich schnell arrangiert: Letzten Endes drücke ich auf Abspielen und kann hier noch etwas angenehmer die Abspielreihenfolge anlegen. Von daher gab es keinen Grund zurückzuwechseln.
Audio Recorder
Mit dieser App lassen sich Tonaufnahmen anfertigen, wieder abspielen und exportieren. Die Aufnahmen werden direkt als .ogg gespeichert und nicht erst platzfressend als .wav angelegt. Funktionierte einwandfrei und brauchte ich auf der BIG für ein Interview.
Aurora Store
Zwar laufen auf meinem Telefon keine Google-Dienste, aber eben doch manche proprietären Apps aus Googles Playstore. Der Aurora Store kann diese installieren und später aktualisieren. Zwischendurch war die App mal kaputt, wohl weil Google gegen die genutzten anonymen Accounts vorging, inzwischen funktioniert sie aber wieder.
Binary Eye
Diese App entdeckte ich für meinen damaligen Job, Binary Eye war der eine immer gut funktionierende QR-Code-Scanner. Ersetzte mehrere zwischendurch angetestete Alternativen und kam dann auch für den eigenen Gebrauch auf das Telefon.
Calendar
Der von Lineage bereitgestelle Kalender ist (ein Fork von?) Etar, für mich funktionierte er gut.
DB Navigator
Die eine Anwendung, die leider wirklich aus dem Playstore kommen muss, weil die Bahn sich einfach querstellt und die App unwürdigerweise weder selbst verteilt noch auf F-Droid einstellt. Immerhin, sowohl die alte Variante der App als auch die kürzlich veröffentlichte neue Version funktioniert ohne Google-Dienste bei mir einwandfrei. Und das muss ich der Bahn dann wieder positiv anrechnen.
F-Droid
Und klar: Ohne F-Droid würde diese Liste nicht existieren. F-Droid ist weiterhin der eine vertrauenswürdige Appstore, mit einer tollen Auswahl quelloffener Software. Und deswegen die eine App, an die ich regelmäßig Geld spende.
Fennec
Firefox für Android via F-Droid. Der Browser ist weiterhin super, die Erweiterungen wie UBlock Origin machen das Internet insgesamt besser. Gegen Ende 2023 wurden die Erweiterungen auch endlich geöffnet (vorher war nur eine statische Mini-Auswahl verfügbar), viel zu spät und viel später als versprochen, aber das Ergebnis ist halt trotzdem toll und Fennec damit einzigartig.
Forecastie
Forecastie ist eine Wettervorhersage-App, die zum einen als solche für mich gut funktioniert, zum anderen auch ein hübsches transparentes Wetterwidget auf den Startbildschirm zeichnen kann.
FreeOTP+
Erstellt diese TOTP-Codes, die bei manchen Seiten als zweiter Faktor beim Login dienen. Sicherer als SMS-Codes, nutze ich das als Backup für den Solo-Fidostick oder falls der nicht unterstützt wird. FreeOTP+ hat mich dabei jetzt seit einigen Jahren nicht enttäuscht.
MuPDF Viewer
Ein kleiner PDF-Viewer, der PDFs anzeigen kann und bei Start eine Dateiliste zur Auswahl anbietet.
Music
Mitgeliefert von LineageOS, hat Music bei mir das Problem manchmal sich nicht ordentlich in den Hintergrund zu schalten, dann geht etwas nach dem Bildschirm die Musik aus. Beim zweiten Versuch funktionierte es bisher immer, deswegen habe ich die App noch nicht ausgewechselt. Ansonsten spielt sie normal gut Musik ab, dass dabei Playlisten verständlich unterstützt werden fand ich angenehm.
NewPipe Sponsorblock
NewPipe ist eine bessere Alternative zu Googles YouTube-App, denn es entfernt die Werbung zwischen den Videos und ermöglicht das Herunterladen. NewPipe Sponsorblock ist eine bessere Alternative zu NewPipe, denn es ergänzt die App um einen Blocker für in die Videos eingebauten Videos, üblicherweise eben Sponsorerwähnungen.
Allerdings sehe ich gerade, dass der Entwickler das Projekt Ende Dezember archiviert hat. Schade!
Notes / Another Notes app
Eine nette kleine Notizenanwendung. Im Appmenü identifiziert sie sich vernünftigerweise nur als Notes, sie kann Checklisten und unterstützt mehrere separate Notizblöcke, die im Startbildschirm der App als Liste oder Raster angezeigt werden können.
Ich benutze sowas vor allem als Einkaufszettel und mir ist am wichtigsten, dass das Anlegen, Abhaken und Entfernen von Listeinträgen flüssig funktioniert. Diese App hat dafür das in meinen Augen genau richtige Bedienkonzept, deswegen blieb ich bei ihr hängen.
Open Camera
Eigentlich mag ich diese Kamera-Anwendung gar nicht so gerne. Sie hat mir zu viele Einstellmöglichkeiten, die ich dann doch nicht nutze. Die eine, die ich gerne nutzen würde – der HDR-Modus – stürzt bei mir dagegen bei der Nutzung ab. Aber immer wenn ich versuchte, auf die von LineageOS mitgelieferte Kamera-App zu wechseln, funktionierte die nur für ein paar OTA-Updates und dann gar nicht mehr. In diesen Situationen war Open Camera immer die eine zuverlässige Alternative.
Wäre aber mal wieder an der Zeit, der mit LineageOS 20 (also Android 13) umgebauten Standardapp eine Chance zu geben, derzeit scheint sie zu funktionieren.
Organic Maps
Organic Maps empfand ich als leichter bedienbare Alternative zu OSMAnd+. Sie hat ähnliche Probleme: Vor allem, dass die Suche immer wieder Aussetzer hat, dass die Kartendaten bei Details wie Öffnungszeiten nicht mit Google Maps mithalten können und die Routenfindung mit Bus & Bahn nicht so gut funktioniert. Aber als Offline-Karte taugt die App trotzdem. Zur Routenfindung griff ich auf den DB Navigator zurück.
PDF Doc Scanner
Ich habe hier weder einen Drucker noch einen Scanner im Haus, was in der papierlastigen deutschen Bürokratie immer wieder ein Problem ist. Dieser Dokumentenscanner ist da eine große Hilfe: Mit der Telefonkamera lassen sich so Papiere einscannen, wobei ein schiebbarer Rahmen das Papier auf dem Foto markiert, dessen automatische Erkennung auch noch gut funktioniert. Das Ergebnis sieht dann so aus als käme es aus einem normalen Scanner, das beugt Meckerkommentaren von Bürokraten vor und reduziert die Dateigröße des PDFs.
Entstammt dem IzzyOnDroid F-Droid Repository, das F-Droid hinzugefügt werden kann und dann ein paar weitere Apps bereitstellt. Das würde ich gerne vermeiden, aber in der Sammlung von F-Droid selbst fand ich keine Alternative.
Shattered Pixel Dungeon
Ein Rougelike, das mir sehr gefallen hat. Es ist ein vollständiges Spiel und kann mit seinen verschiedenen Charakteren viele Stunden beschäftigen, ist frei von Mikrotransaktionen und einfach ziemlich gut. Vor allem für ein Mobilspiel. Man sehe auch das Review bei Gnu/Linux.ch. Für mich ein Reisebegleiter.
Signal
Ich habe mich lange gegen Signal gesträubt, weil das Projekt alternative Clients nicht zulassen wollte und nicht auf F-Droid ist. Unsympathisch. Dann bekam ich aber mit, dass sie immerhin ein .apk auf ihrer Webseite veröffentlichen, was ich anderen Apps auch durchgehen ließ. So bekam Signal kürzlich also doch eine Chance.
Noch nicht viel benutzt.
Syncthing
Syncthing nutzte ich früher mal als Dropboxalternative auf meinem PC, was mir dann irgendwann zu umständlich war (bzw ich das Zweitgerät nicht mehr nutzte, den Laptop). Auf dem Telefon entdeckte ich es wieder als Backuplösung für die Fotos.
Telegram
Weil Telegram – anders als Signal – auf F-Droid vertreten ist und – anders als andere verschlüsselnde Messenger – verlässlich funktionierte, wurde es vor einigen Jahren zu meiner Haupt-Chatapp. Das ist bisher so geblieben.
Ich weiß um den schlechten Ruf der App, aber ich meide Telegram-Gruppen sowieso und eine gute funktionierende Option braucht es nunmal.
VLC
VLC nutze ich inzwischen selten, nur um auf Reisen heruntergeladene Videos abzuspielen. Früher war es wichtiger, da hatte NewPipe auf dem G5 einen Bug und brach regelmäßig die Videowiedergabe ab, während das Streamen von der App zu VLC funktionierte.
Weggefallen sind damit:
Advanced Charging Controller(Hauptfunktion in LineageOS 20 eingebaut, + Rooten von LIneageOS wurde unmöglich)CPU Info(kein Anwendungsgrund mehr, würde ich bei Bedarf neu installieren)Document Viewer(-> MuPDF Viewer, Sicherheitslücke)Escapepod(-> AntennaPod)Jitsi Meet(-> Telegram, würde ich bei Bedarf neu installieren)NewPipe(->NewPipe Sponsorblock)OSMAnd+(->Organic Maps)Scarlet Notes FD(-> Another Notes app)StressTest(kein Anwendungsgrund mehr, würde ich bei Bedarf neu installieren)Transportr(-> DB Navigator)
Wie sieht es bei euch aus, habt ihr Empfehlungen für mich?
Simdock jetzt mit Compositing und GTK3
Tuesday, 5. December 2023
Simdock ist mein Dock für den Linuxdesktop, das ich seit ein paar Jahren pflege. Jetzt konnte ich dem Code ein großes Update verpassen und damit das Projekt für die nächste Zeit absichern.
Kurzfassung
- Simdock läuft nun mit der GTK3-Version von wxWidgets, bei mir ist das das sehr neue wxWidgets-3.2.4. Dadurch wird es auch auf modernen Systemen wieder kompilieren.
- Durch den Wechsel zu GTK3 musste auch die genutzte Library Wnck aktualisiert werden, die Version 1 zuvor setzte auf GTK2, das kollidierte. Nebeneffekt davon ist, dass für die dynamischen Programmanzeigen größere Icons gewählt werden sollten.
- Dank der neuen Version von wxWidgets konnte durch wenige Codeänderungen Compositing für den Dockhintergrund aktiviert werden. Die Pseudotransparenz funktioniert weiterhin, wenn kein Compositor am Laufen ist.
- Es werden wieder AppImages gebaut. Die gab es für Simdock schonmal, die waren aber durch den Wegfall von Travis CI ausgefallen. Die AppImages hatten (zumindest aber auf meinem System) noch einen Bug mit dem neuen Compositing, mehr dazu unten.
Der allgemeine Hintergrund des Updates
Simdock lief die letzten Jahre relativ zuverlässig vor sich hin. Aber der Wechsel zu GTK3 war eine große Gefahr für die weitere Existenz des Projekts und die Migration jahrelang durch eine fehlende Funktion von GTK3 blockiert.
Nun war der Wechsel aber unumgänglich, es musste etwas passieren. Denn selbst auf meinem eigenen System konnte ich Simdock nicht mehr bauen. Void Linux hatte wxWidgets auf GTK3 umgestellt, ohne die GTK2-Version weiterhin bereitzustellen. Und das alte AppImage lief auch nicht, neue wurden sowieso nicht mehr gebaut. Ich rechnete eigentlich damit, das Projekt aufgeben zu müssen – und stolperte dann gestern doch über die Lösung.
Als Simdock vor ~2 Monaten für mich wegbrach hatte ich noch mit keiner Lösung gerechnet und mir stattdessen Alternativen angeschaut. Und tatsächlich auch gefunden: Plank ist mittlerweile eine hervorrage Alternative. Es fehlen die konfigurierbaren Starter, dafür kann es sich selbst verstecken (Auto-Hide) und und ist so platzsparend, außerdem hatte es schon lange echte Transparenz. Ich nutzte es mit Openbox und jetzt nochmal mit IceWM (da kollidierte es erst mit meiner Konfiguration, aber mit der Versteckenfunktion passte es). Die Existenz der Alternative war entspannend! Aber jetzt nachziehen zu können befriedigt dann doch meinen Ehrgeiz. Und es war die bessere Lösung in meiner derzeitigen Projektaufräumaktion, so statt dem Aufgeben genau wie bei izulu nach Jahren des Zeitmangels die Modernisierung umsetzen zu können.
Technische Erklärungen
Warum war der Wechsel zu GTK3 so problematisch? Es sollte überraschen, denn wxWidgets abstrahiert das Toolkit eigentlich weg, ob da jetzt GTK2, GTK3 oder gar QT läuft sollte egal sein. Gleichzeitig ist wxWidgets eines dieser großartigen Projekte, bei denen Upgrades generell schmerzlos sind, ich musste genau null Zeilen wxWidget-Code anpassen.
Das Problem war diese Funktion: gdk_pixmap_foreign_new(). Simdock benutzte sie, um den Hintergrund des X11-Desktops zu holen und den dann als Hintergrund des eigenen Fensters zu setzen. Klassische Pseudotransparenz. Und für diese Funktion gibt es in GTK3 einfach keinen direkten Ersatz. Der Code sah leicht vereinfacht so aus:
wxBitmap* backImage = new wxBitmap();
WnckScreen *screen = wnck_screen_get_default ();
// The XID of the background pixmap
Pixmap pm = wnck_screen_get_background_pixmap(screen);
if (pm != None) {
wxBitmap* backImage = new wxBitmap(
gdk_pixmap_foreign_new(
pm
)
);
return backImage;
}
Da wurde also auch Wnck genutzt, dessen Details sich ebenfalls ändern würden, das verstellte weiter den Blick auf die Lösung. Es gibt einfach keinen dokumentierten Weg, die Pixmap des XServers mit GTK3 in ein Grafikobjekt zu quetschen um sie dann wxBitmap zu übergeben.
Stattdessen sah meine Lösung schließlich so aus:
wxSize sz = wxGetDisplaySize(); wxBitmap* backImage = new wxBitmap( gdk_pixbuf_get_from_window( gdk_x11_window_foreign_new_for_display( gdk_display_get_default(), gdk_x11_get_default_root_xwindow() ), 0, 0, sz.GetWidth(), sz.GetHeight() ) );
Das benutzt jetzt also GDK-Funktionen ohne den Wnck-Umweg. Und war nur möglich, weil ich mit der Hilfeseite zu X Window System Interaction endlich über die passende Dokumentation gestolpert war. Der Code holt sich das Root-XWindows mit gdk_x11_get_default_root_xwindow(), macht daraus ein GDK-Window mit gdk_x11_window_foreign_new_for_display und davon kann gdk_pixbuf_get_from_window dann eine Grafik ziehen. Dass dadrin ebenfalls gdk_display_get_default benutzt wird folgte direkt der Dokumentation.
Jedoch: Das ist nicht ganz das gleiche! Denn die Grafik beinhaltet auch alle offenen Fenster. Es ist eben nicht der X-Hintergrund, an den ist einfach nicht ranzukommen. Doch für Simdock war das gut genug: Normalerweise sind eh keine Fenster hinter einem Dock, und ich schaffte es, Simdock vor dem Ziehen dieses Screenshots auszublenden. Flickert ganz kurz, aber da das nur bei Hintergrundbildwechseln passiert sollte das okay sein.
Damit war die Makefile anpassbar. Wnck-3.0 und wxWidgets-GTK3 konnten ins Projekt, Simdock damit wieder auf modernen Systemen gebaut worden. Und die nächste langjährige Baustelle war angehbar.
Echte Transparenz mittels eines Compositors hätte das Problem mit der oberen schwierigen Umsetzung von Pseudotransparenz umgangen. Diese Transparenz sollte wxWidgets eigentlich können, es gibt mit wxBG_STYLE_TRANSPARENT einen passenden setzbaren Hintergrund, der echte Transparenz bringen soll. Doch bei mir hatte das in vorherigen Tests nie geklappt.
Mit GTK3 und einer neuen Version von wxWidgets testete ich das erneut. Und tatsächlich: Es brauchte nur minimale Codeänderungen und die Transparenz lief direkt. Ein echter Durchbruch. Simdock soll weiterhin Pseudotransparenz unterstützen – das war das originale Alleinstellungsmerkmal des Programms, weswegen ich es überhaupt übernommen habe – aber echte Transparenz zusätzlich anbieten zu können ist super. Vor allem, wenn es jegliches Flickern vermeidet.
Die Lösung folgt genau der Dokumentation, wie ich sie vorher schonmal verlinkt hatte: Im Konstuktor des wxWindow, in diesem Fall dem wxFrame, SetBackgroundStyle(wxBG_STYLE_TRANSPARENT); setzen und erst danach mit Create(parent, ...); das Fenster erstellen. Vorher sah der Anfang des Konstruktors so aus:
MyFrame::MyFrame (wxWindow parent, simSettings set, ImagesArray array,
wxWindowID id, const wxString & title, const wxPoint & pos,
const wxSize & size, long style):
wxFrame (parent, id, title, pos, size, style)
{
…
SetBackgroundStyle(wxBG_STYLE_PAINT);
}
Daraus wurde das hier:
MyFrame::MyFrame (wxWindow parent, simSettings set, ImagesArray array,
wxWindowID id, const wxString & title, const wxPoint & pos,
const wxSize & size, long style):
wxFrame()
{
// This enables full composited transparency:
SetBackgroundStyle(wxBG_STYLE_TRANSPARENT);
Create(parent, id, title, pos, size, style);
…
}
Da veränderte sich also ebenfalls die Definition des Konstruktors, plus dem schnelleren Setzen von wxBG_STYLE_TRANSPARENT vor dem Create.
Ausstehende Probleme
Simdock hat relativ früh AppImages bereitgestellt. Ich war auf der Froscon in einem Vortrag des AppImage-Projekts und fand die Idee super. Die wurden aber die letzten Jahre nicht mehr gebaut, weil die Travis-CI nicht mehr kostenlos war.
Also stellte ich die Buildpipeline wieder her. Diesmal mit Github-CI, und weil linuxdeployqt einen Fehler produzierte wechselte ich zu linuxdeploy mit dem GTK-Plugin. Das funktionierte an sich! Aber: Das AppImage bleibt bei mir schwarz, wenn Compositing aktiviert ist.
Ich habe ein Issue dafür auf, in dem ich auch mehr der Details zu den AppImages erkläre. Den gewählten Ansatz finde ich wirklich geschickt, die Logik hauptsächlich in eine zweite Makefile zu packen. Das hält die Github-CI-Workflowdatei simpel. Aber das Ergebnis muss eben auch funktioniere. Bis sich da eine Lösung auftut werde ich das AppImage weiter bauen lassen, aber nicht bewerben.
Mit all den Änderungen hat Simdock technisch einen großen Schritt getan und ich freue mich, dass das möglich war. Es wäre zu schade gewesen, das Projekt wegen den GTK-Migrationsproblemen aufgeben zu müssen. Und wer ein nettes Dock mit gutem Fenstermanagement sucht, mit Plank aber aus irgendwelchen Gründen nicht warm wird, dem kann ich Simdock jetzt wieder guten Gewissens empfehlen. Die Installation per Kompilierung wird im Readme beschrieben.
Warum ich von meinem PineTab ausgerechnet auf ein Microsoft Surface Pro umstieg
Monday, 30. October 2023
Gut, ein großer Faktor war, dass das das PineTab nicht mehr anging. Aber der Wechsel gibt eine interessante Geschichte ab und war so oder so eine gute Idee – wobei das PineTab auch ein paar Vorteile hatte.

Der Wechsel
An einem Donnerstag hatte ich das PineTab wieder aus dem Schrank genommen, es angemacht und aktualisiert. Tatsächlich fehlten ein paar wichtige Daten wie meine Passwortdatenbank. Ich hatte das PineTab schon zuvor als Reisebegleiter benutzt – dafür ist es vom Formaktor her super geeignet, klein und leicht und doch mit Tastatur – aber seitdem neu installiert und es auf der letzten Reise durch einen Arbeitslaptop ersetzt gehabt. Ein paar Datentransfers und ein Update später war alles bereit. Die Reise sollte am Samstag starten.

Freitag mach ich das PineTab nochmal zur Kontrolle an – und nichts passiert. Nicht ganz, tatsächlich klackerte das Ding vor sich hin. Das hatte es früher schon manchmal gemacht, irgendwas stimmt da mit der Hardware meines Modells nicht. Aber diesmal blieb der Bildschirm über viele Versuche aus, ob neu geladen oder nicht. Das war neu, und nun war ich in Panik. Wegen dem Charakter der Reise brauchte ich unbedingt ein fähiges Begleitergerät, um auf die Server zu kommen etc. Aber es blieben nur noch ein paar Stunden um ein neues Gerät einzurichten und es musste Linux drauf laufen.
Also ging ich auf Kleinanzeigen und suchte nach Laptops in der Umgebung. Es gab die Auswahl zwischen überteuertem Schrott und für die Reise ungeeigneten Gaming-Monstern. Auf Verdacht suchte ich nach Surface – und fand einen Treffer für ein Surface Pro 3. Das war verlockend: Gleiches Prinzip wie das PineTab, also ein Tablet mit andockbarer Tastatur, die Erfahrungen in der Familie mit der Gerätefamilie sind positiv und einer schnellen Recherche zufolge gibt es ein Projekt, um die Geräte mit Linux kompatibel zu machen, wobei das ältere dritte Surface-Tablet noch mehr Standardhardware einsetzt und daher sowieso kompatibel sei. Angeschrieben, prompte Antwort, rübergelaufen und das Gerät war in meiner Hand.
Linuxinstallation auf dem Surface Pro (3)
Durch Zeit und die Größe des einzigen USB-Sticks im Haus beschränkt entschied ich mich notgedrungen für Lubuntu. Die Installation war überraschenderweise problemlos. Per Tastenkombination (wie bei einem Android-Telefon "Lautstärke hoch + Power") das BIOS starten, Booten von USB bei der Bootreihenfolge aktivieren. Lubuntu startet dann direkt, Wlan funktionierte, der Installer konnte durchlaufen. Ich musste dann nur nochmal die Windows-Bitlocker-Verschlüsselung deaktivieren, weil ich zur Sicherheit die Windowsinstallation tatsächlich behalten wollte und der Installer wegen der Verschlüsselung keinen Speicherplatz abzwacken konnte.

Alltag mit Vor- und Nachteilen
Nach der Installation zeigte das Surface-Tablet, das ich bis jetzt fast ausschließlich mit der Tastatur als Laptop benutzte, seine Stärken. Alle in meiner Besprechung erwähnten Schwächen des PineTabs sind gelöst:
- Das Gerät geht zuverlässig an.
- Es wirkt mit seinem Magnesium-Gehäuse viel wertiger
- Der (hochauflösende und gute) Bildschirm wird deutlich heller.
- Die Lautsprecher sind lauter und besser.
- Die Tastatur wabbelt weniger; Das Touchpad ist zwar nicht toll, aber etwas größer und wirkt genauer.
- Es gibt keine Probleme mit einer SD-Karte, dessen Mechanismus und Abdeckung, weil eine echte SSD eingebaut ist.
- Die Performance des Prozessors ist viel besser, das Gerät bei Alltagsnutzung dadurch angenehm schnell.
Außerdem vermeidet die Standardhardware – x86-Prozessor statt ARM – und das damit mögliche reguläre Lubuntu die Softwareprobleme, die postmarketOS damals hatte und die bei meinem Test an dem Donnerstag teilweise auch heute noch bestanden.
Perfekt ist das Surface Pro 3 aber auch nicht. Zuerst ist es größer, 12" statt 10", 800g statt 575g. Das macht es für einen Reisebegleiter weniger geeignet. Der in meinem Modell verbaute i7-4650U-Prozessor hat nur zwei Kerne und ist abseits des Vergleichs mit dem PineTab nicht sehr leistungsfähig. Anfangs ruckelte sogar Youtube auf 1080p – was ich durch eine Kontrolle der Hardwarebeschleunigung und folgendem Erzwingen von h264 löste und was wenn ich mir seitdem die Performance anschaue auch ein Bug gewesen sein kann. Bei Videos wird auch auffällig, dass der Akku nicht besonders lange hält, ob das nun am Alter des Akkus, an fehlenden Optimierungen im Kernel für die Hardware oder an sonstwas liegt sei dahingestellt. Das Ladegerät ist ein interessantes magnetisches Ansteckkabel, aber damit eben auch ein proprietär, eventuell schwer zu ersetzen. Und schließlich ist der Bildschirm zwar schön und hell, aber auch spiegelnd, was mich immer stört.
Trotz der Nachteile kommt das Surface-Tablet klar besser weg. Es ist eben auch ein Vergleich zweier sehr unterschiedlichen Qualitätsklassen. Das Surface Pro 3 in dieser Ausführung kostete bei Release 2000 USD und war trotzdem Massenhardware mit einem Megakonzern im Rücken. Dafür ist es von 2014, also völlig veraltet. Das PineTab ist deutlich moderner, ich kaufte es als Neugerät 2020, aber der theoretische technische Fortschritt wiegt die Nischigkeit und den Preisunterschied (es kostete ~160 USD) eben doch nicht auf.
Trotz des Alters des Surface Pro 3 und der Größe ist es ein besserer Reisebegleiter, als es das PineTab damals war. Die Installation und Nutzung von Linux war problemlos, wobei meine Wahl von Lubuntu die Nutzung als Tablet etwas einschränkt. Ich würde wegen dem Alter des Akkus und dessen fast unmöglicher Auswechselbarkeit das Gerät auch nicht generell empfehlen, sondern eher raten nochmal nachzurecherchieren, ob eines der neueren Surface-Tablets oder ein Alternativgerät gut unterstützt wird. Oder direkt zu einem Framework-Laptop greifen. Die Option hatte ich aus Zeitmangel nur nicht – wobei ein teures neues Gerät auch nicht zu meinem Reiseland gepasst hätte und es durchaus ein Plus war, so die Nutzungszeit eines Altgeräts noch etwas zu verlängern.
Dem PineTab werde ich mit etwas mehr Zeit nochmal eine Chance geben. Möglich ist es ja, dass es nach einer Bedenkpause wieder angeht oder es tatsächlich ein Softwareproblem ist, das den Bildschirm schwarz bleiben lässt. Ich mochte den Ansatz des Geräts als Prototyphardware für den mobilen Linuxdesktop und hätte mit ihm gerne noch ein paar Softwareiterationen miterlebt. Es wäre schade, wenn es das jetzt schon war. Wobei man ehrlicherweise sagen muss, dass die Hardware wohl auch schlicht zu schwach war, um als Arbeitsgerät zu taugen und Macken wie die schlechten Lautsprecher auch die Nutzung als SD-Multimediatablet blockieren, dadurch blieb es daheim ungenutzt. Es wäre also abseits eines Reisebegleiters, was sich jetzt wohl erledigt hat, immer nur ein Experimentiergerät gewesen um zu schauen, was bessere Hardware könnte. Hardware, wie sie das alte Surface-Tablet eben schon mitbringt…
Wiederhergestellt: izulu 2.0
Monday, 14. August 2023
Mein langjähriges Projekt izulu ist ein Skript, das den Bildschirmhintergrund dem Wetter anpasst. Oder eher: Es ist es jetzt wieder. Denn izulu war kaputtgegangen und ich hatte lange keine Motivation, es zum Laufen zu bringen. In Version 2.0 (bzw 2.0.1, ein paar kleine Fixes kamen obendrauf) funktioniert es erneut, mit neuer Bilderauswahl, anderen APIs, aber auch reduziertem Funktionsumfang.
Es war überfällig, denn lange wollte ich da nicht ran. Zu ärgerlich war diese letzte API-Abschaltung, diesmal die von Dark Sky, die izulu mit in den Abgrund riss. Es ist eine lange Liste inzwischen eingestellter Dienste: Google Wetter, Yahoo Weather, Yahoos WOEID und freegeoip.net sind nur die, die mir gerade einfallen.
Nur weil ich über passende Alternativen stolperte und daraufhin eine Strategie formulieren konnte, kam jetzt die Überarbeitung:
- Entferne alle Funktionen, die du nicht selbst dauernd nutzt.
- Behalte den Kern, wie er ist – als recht simples Bash-Skript mit entsprechender Struktur.
- Benutzt werden nur APIs, die keinen API-Key brauchen. Der Aufwand ist Nutzern nicht zuzumuten, auch nicht realistisch in einem Bash-Skript unterstützbar.
- Genauso wird für das Projekt keine eigene Serverkomponente mehr betrieben, um den Aufwand dem Nutzen angemessen zu halten.
Bright Sky war Ausgangspunkt dafür. Das Projekt verpackt Daten des Deutschen Wetterdiensts in eine angenehm zu nutzende API, izulu zieht davon das aktuelle Wetter. Zweitens wird MET genutzt, das Norwegian Meteorological Institute, dessen API liefert die (optionalen) Wettervorhersageicons unten rechts. Damit izulu auch läuft, ohne dass unbedingt die genaue Position angegeben werden muss, verrät der Mozilla Location Service bei Fehlen derselben eine ungefähre Position über die IP-Adresse.
Noch etwas hat sich seit 2009 getan: Es ist inzwischen viel einfacher, an gute und frei nutzbare Bilder zu kommen. Damals war die beste mir bekannte Möglichkeit CC-lizenzierte Bilder von Flickr, wobei die damaligen CC-Lizenzen mit ihren Bedingungen nicht gut zum deutschen Rechtssystem passten, sie zudem auch im Konzept von izulu nur so halb umzusetzen waren (Herkunftsnennung in einer Dokumentationsdatei, ob das reichte?). Deswegen sind nun alle Wetterbilder mit solchen von unsplash ersetzt.
Die entfernten Funktionen (die zufällige Bilderwahl aus einem Ordner oder von Flickr, das Wetterradarbild Deutschlands oder der Schweiz) müssen nicht unbedingt dauerhaft entfernt bleiben, wenn sie wirklich gewünscht werden. Gerne würde ich zudem brightsky.dev durch eine internationalere Wetter-API ersetzen, da fand ich bisher aber keine brauchbare.
Das Skript jetzt wieder am Laufen zu haben fühlt sich toll an. Das Konzept, das ja gar nicht von mir kam, finde ich immer noch nett, der Computer fühlt sich hiermit etwas natürlicher an und die Wettereinbindung ist auch schlicht praktisch. Der über die Jahre fabrizierte Bash-Code ist abgesehen von ein paar Details angemessen simpel, vor allem da jetzt um einige Codezeilen reduziert.
Vorschläge gerade für die Wetter-API-Auswahl wären willkommen. Wer izulu mal testen will werfe einen Blick in die Readme, die Abhängigkeiten sind gering, wobei Wayland bisher nicht unterstützt wird und ich das Release nur unter IceWM getestet habe.
Mit Upscaling allgemein Fotos verbessern?
Monday, 31. July 2023
Vor der Bildergenerierung war die Bildhochskalierung. Die Idee ist ähnlich: Ein neuronales Netz wird auf Bilderdaten gelernt, bekommt eine Eingabe und spuckt ein Bild aus. Beim Hochskalieren ist das statt Text eben ein Bild und das Ergebnis soll möglichst nah an der Eingabe sein. Normalerweise: Größer. So wird aus einem Fitzelbild aus den 90ern ein modernes in 4K mit vollen Details, aus einem Mini-Pixelicon eine etwas größere Grafik für andere Einsatzzwecke. Aber: Geht auch einfach besser?
Denn mein Ziel ist meist nicht das Hochskalieren an sich. Fitzelbilder habe ich selten. Sondern, wenn ich ein schlechtes Bild habe, möchte ich ein gutes Bild herausbekommen. Egal was nun das Problem ist, ISO-Rauschen, ob das Bild verwackelt ist, Kompressionsartefakte hat oder was auch immer schiefgehen kann. Wenn mir Software das Bild kreativ bearbeiten könnte ist es mir egal, ob es danach die zwanzigfache Auflösung hat, wenn ich es danach wieder auf 1080p herunterskaliere und es immer noch besser aussieht als zuvor wäre ich zufrieden.
Testmotiv und Software
Ich habe das an diesem Bild getestet:

Ein perfektes Testmotiv für mein Ziel. Das ist Chichen Itza, von mir 2015 mit dem Nokia Asha 210 aufgenommen. Die Kamera des Nokia-Telefons hat etwa alle drei Fotos ein halbwegs brauchbares ausgespuckt und hier hatte ich Glück, das Bild ist hübsch. Aber man sieht trotzdem an vielen Stellen die geringe Qualität der Kamera, am Bilderrauschen in den dunklen Wolken, an den unscharfen Kanten der Pyramide, an den fehlenden Details. Trotzdem ist es 1600x1200 Pixel groß, was als Auflösung z.B. zum Zeigen hier im Blog völlig reichen würde. Es hochzuskalieren ist also für mich eher uninteressant, wenn dadurch nicht die generelle Bildqualität verbessert wird.
Genau das will ich mit Upscayl 2.5.5 testen. Die Software hat ein supersimples Interface, zeigt nach dem vierfachen Hochskalieren eine praktische Vergleichsansicht, liefert eine Auswahl verschiedener Hochskalierer mit, bietet auf Github ein praktisches AppImage an und benutzt beim Hochskalieren ohne weiteren Aufwand meine AMD-Grafikkarte für den Prozess.
Das Ergebnis
Seht selbst, klickt auf diese Fotos:




Das sind die wieder auf 1200p herunterskalierten Bilder dieser Modelle: Real-ESRGAN, Remacri, Ultramix-balanced, Ultrasharp.
Das Ergebnis variiert stark je nach genutztem Modell, und dann nochmal je nach Bildbereich. Skaliert man die Bilder wie hier wieder auf 1600x1200 herunter verlieren sich einige der Details, die hinzugedichtet wurden. So wieder verkleinert ist die Gesamtbildqualität nur beim vom Remacri-Modell produziertem Ergebnis besser – und auch dann nur minimal. Bei diesem Modell sind auch die Farben konstanter – das Bild ist nur etwas aufgehellt, bei den Schatten der Bäume und der Pyramide, während beim Ergebnis von Real-ESRGAN einige Farben verfälscht wurden, beispielsweise der Rasen sehr viel grüner ist.
Im Detail
Wegen des Effekts der Herunterskalierung zeige ich jetzt ein paar der Details des Originalbilds des gleichen Auschnitts der Hochskalierten und noch nicht wieder verkleinerten Ergebnisse von Real-ESRGAN und Remacri. So kann die Leistung der Hochskalierer besser diskutiert werden.



Reihenfolge: Real-ESRGAN, Remacri, Original.
Der Rasen stellt alle Modelle außer Remacri vor große Probleme. Schon im Original leicht unscharf, machen sie aus ihm eine grüne Masse und verlieren dabei jedwedes Detail. Zoomt man näher heran sieht man, dass auch das Remacri-Modell nicht den Rasen wiederhergestellt hat, es hat ihn nur nicht so glattgebügelt, dass er in der normalen Ansicht falsch wirkt.

Reihenfolge: Real-ESRGAN, Remacri, Original.
Die Menschengruppe auf dem Rasen wird von den Modellen seltsam hochskaliert. Die geringe Informationsdichte des Originalbilds scheint sie etwas ratlos zurückzulassen. Die vorhandenen Farben werden verstärkt, und manche Kleidungsstücke werden erstaunlich gut erträumt, aber andere Details wie die richtige Reflexionsfarbe an den Beinen gelingt gar nicht. Das Ergebnis wirkt in der Nahansicht absurd, herausgezoomt ist das Ergebnis okay, wobei die Menschen etwas mehr wie Plastikfiguren wirken als zuvor.
Wenn ich mir angucke, wie klein die Menschen im Originalbild sind, ist das Ergebnis eigentlich beeindruckend. Da werden viele Kleidungsstücke aus wenigen Pixeln erraten und dann an die Bewegungsrichtung angepasst. Es sieht nur nicht so gut aus, wie ich mir erhofft hatte, gerade durch diese grünen Lichtklekse, die ein perfektes Modell weggelassen hätte.



Reihenfolge: Real-ESRGAN, Remacri, Original.
Interessant ist, wie die Pyramide behandelt wurde: Hier sieht man, dass die Modelle auf ein solches Bauwerk geeicht wurden. Nur auf ein anderes. Zwar verwaschen insgesamt, wird beim Heranzoomen deutlich, dass hier eine Art Zeichnung auf die Mauersteine projektiert wurde. Die ist im Originalbild vielleicht zu erahnen – existiert aber in echt nicht an diesem Gebäude, es handelt sich um eine Interpretation von Bildfehlern. Man könnte sich aber gut vorstellen, dass andere Mauerwerke (aus Marmor?) solche Muster tatsächlich haben.



Reihenfolge: Real-ESRGAN, Remacri, Original.
Beim Himmel mit den aufgetürmten Regenwolken sieht das Ergebnis etwas anders aus: Den verbessern auf den ersten Blick alle Modelle. Besonders das Standardmodell für Bilder, Real-ESRGAN, lässt das Bilderrauschen verschwinden und zeichnet die Wolken trotzdem so eindrucksvoll wie zuvor. Remacri wirkt erst, als wäre es bei der Verbesserung nur etwas dezenter gewesen, überrascht allerdings, wenn man hineinzoomt: Dann sieht das Ergebnis überhaupt nicht mehr verbessert aus, sondern wurden aus dem Bilderrauschen echte Bildfehler. Und auch die Bäume wurden verstümmelt. Die wiederum sind Real-ESRGAN extrem gelungen, sie sehen einfach besser aus als im Original, schärfer und ohne Bildfehler. Allerdings sind sie auch wesentlich grüner.
Schaut man sich meinen Einsatzzweck an, ist Remacri das beste Modell und kommt dem nahe, was ich anfangs wollte: Das wieder verkleinerte Bild sieht fast identisch aus, nur Details sind verändert, der Himmel z.B. hat weniger Bilderrauschen. Wenn ich mir aber in den hochskalierten Bildern anschaue, was die Modelle gemacht haben, sind Remacris Veränderungen seltsam. Und ist die Arbeit von Real-ESRGAN viel näher an dem, was ich mir von diesen Hochskalierern erhoffen würde – Paradebeispiel sind da die auf einmal scharfen Bäume, einfach perfekt. Wenn das mit allen Details ginge! Zudem sind die Verbesserung von Remacri zu gering, als dass ich dessen Arbeit als Erfolg verbuchen wollte. Weniger Bilderrauschen bei den Wolken ist eben nicht kein Bilderrauschen, die Pyramide bleibt an den Kanten unscharft, und so geht das weiter.
Insgesamt würde ich als Fazit die Eingangsfrage verneinen, allgemein relevant und zuverlässig die Bildqualität zu verbessern scheint mit allen gesteten Modellen nicht zu gehen.
Vielleicht gibt es andere Modelle, die statt den bisher von upscayl benutzten diese Aufgabe besser erledigen würden? Das Upscale-Wiki listet einige Alternative, die von der Beschreibung her besser passen könnten. Es könnte sich lohnen, die für einen nächsten Test in upscayl zu integrieren, oder schlicht direkt eine andere Software zu benutzen. Wenn es da denn eine passende geben würde, mir ist keine bekannt.
Wie ich das neue und das alte Thunderbird-Logo verbinden würde, vielleicht
Wednesday, 12. July 2023
So sieht das neue Thunderbird-Logo aus:

Es ist hübsch geworden! Und stark angelehnt ans moderne Firefox-Logo. Mit seinem flachen Design ist es wunderbar geeignet, um auf Telefonen als Startbutton für die Anwendung zu dienen, selbst wenn sie auf monochrom gestellt werden braucht es nur eine leichte Abwandlung. Genau diese Variante zeigte der Vorstellungsartikel, das war bestimmt eine der Anforderungen an das neue Design.
Doch wenn ich das Logo nur als Logo betrachte, missfallen mir im direkten Vergleich zum Vorgängerlogo ein paar Eigenheiten. Schauen wir erstmal das alte Logo an:
![]()
Dieses Logo hatte einen anderen Charakter als das neue. Da ist zum einen der Charakter des Vogels selbst. Der dünne Schnabel erinnerte mehr an eine Brieftaube, das braune Auge blickte freundlich, auf jeden Fall freundlicher als das dämonisch anmutende weiße Augenloch des neuen Logos.
Freundlicher ist generell das Stichwort. Dazu trägt auch die stärkere gezeichnete Struktur der Federn bei. Das neue Logo wirkt moderner, aber das bedeutet derzeit eben auch: abstrakter. Und flache abstrakte Strukturen wirken keinesfalls freundlich. Außerdem bin von den vielen neuartigen simplen Logos mit ihren geometrischen Formen und flachen Oberflächen gelangweilt. Da ist das neue Thunderbird-Logo keinesfalls ein sehr negatives Beispiel, das ist ja nicht einfach eine aufgemotzte Grundform wie z.B. bei den Google-Appicons, aber es ist ein Schritt in diese Richtung.
Ich würde daher das neue und das als Logo verbinden. Die neue Grundstruktur gefällt ja auch mir, die neue Rundung um den getragenen Briefumschlag mit dem Firefox-artigen Schwanz funktioniert, selbst wenn es eine Kopie ist. Auch die neuen lila Aufhellungen würde ich behalten, schon sie alleine geben dem Logo einen neuen Anstrich. Doch vom alten Logo würde ich:
- das Auge übernehmen, genau so wie es war,
- den hellblauen Schnabel übertragen, vermischt mit dem lila Farbverlauf, und dabei den neuen Schnabel verkleinern - meine Variante hat sogar ein kleines Atemloch,
- die Federkleidstruktur kopieren, teilweise, sodass da wieder Federn-symbolisierende Schritte im Körper sind und im Gesicht, um das Auge herum, die Einbuchtung wieder und die Gesichtsstruktur stärker zu sehen sind.
Das würde dann so aussehen:

Technisch ginge die Umsetzung besser, und klar, für ein monochromes Startericon ist das weniger geeignet. Durch die stärker ausgearbeitete Strukturen ist das noch weniger ein vollständig modernes Logo im Flat-Design. Aber mir gefällt diese Variante gerade deswegen. Für meine Augen bewahrt sie besser das positive des alten Logos, sie wirkt insgesamt freundlicher, macht aus einer Brieftaube weniger einen Raubvogel und ist durch die Form trotzdem im Vergleich zum alten Logo modernisiert und ans Firefox-Logo angepasst.
Mit Easy Effects und AutoEq den Kopfhörerklang verbessern
Monday, 5. June 2023
Durch PipeWire wird es einfach, einen systemweiten Equalizer zu setzen und damit potentiell den Ton des eigenen Ausgabegerätes anzupassen. Easy Effects ist (unter anderem) ein solcher Equalizer, ist in den Quellen von Void Linux und funktionierte bei mir auf Anhieb. Doch was genau soll man einstellen? Da kommt die Webanwendung AutoEq ins Spiel. Mit ihr kann man für viele Kopfhörer passende Voreinstellungen abrufen und in Formate für verschiedene Equalizer umwandeln, darunter auch Easy Effects. Ich habe das für meinen ATH-M50x durchgespielt und beschreibe im Folgenden mein Vorgehen.
Mit AutoEq Konfiguration herunterladen
In der Suchleiste oben auf der Webseite kann nach dem eigenen Kopfhörermodell gesucht werden.
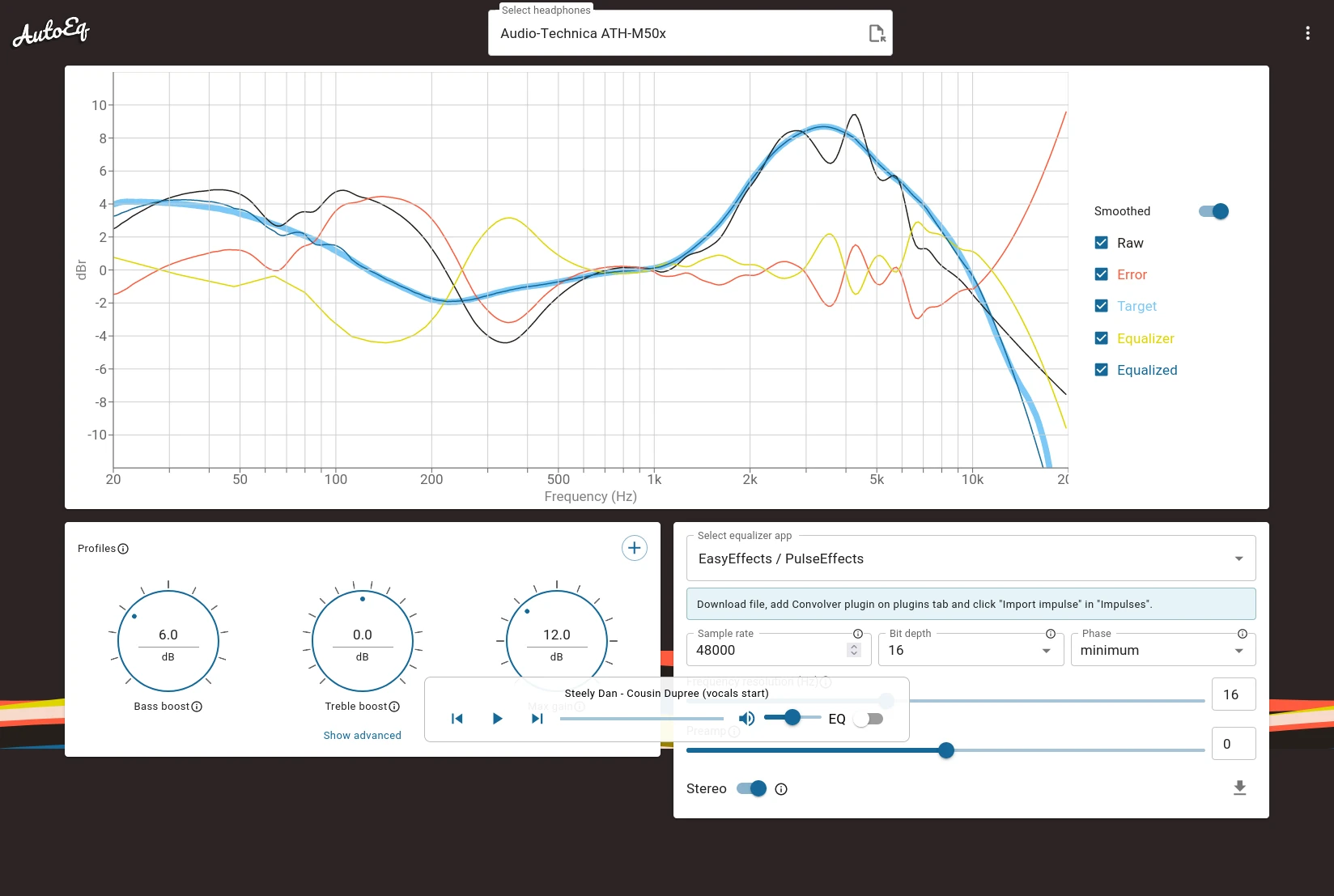
Einmal gefunden geht die Vorschau der Einstellungen auf. Rechts kann das Zielprogramm ausgesucht werden, Easy Effects ist als EasyEffects / PulseEeffects in der Liste. Bei der nun aufgehenden Konfiguration muss der Schalter für Stereo aktiviert werden. Ob 44.1kHz, 48kHz oder gar 96kHz richtig ist sollte an der Pipewire-Konfiguration hänge, im Zweifel ist es 44.1. Unten rechts versteckt sich der Download-Button als schwer zu erkennendes Icon.
Man kann die Konfiguration hier auch ändern. Hat jemand Hinweise, was man versuchen sollte?
Mit Easy Effects Konfiguration laden
Jetzt installieren wir Easy Effects. Unter Void ging das einfach mit
sudo xbps-install easyeffects
Das Programm startet der gleichnamige Befehl easyeffects.
In Easy Effects folgen wir nun den Anweisungen der AutoEq-Webseite:
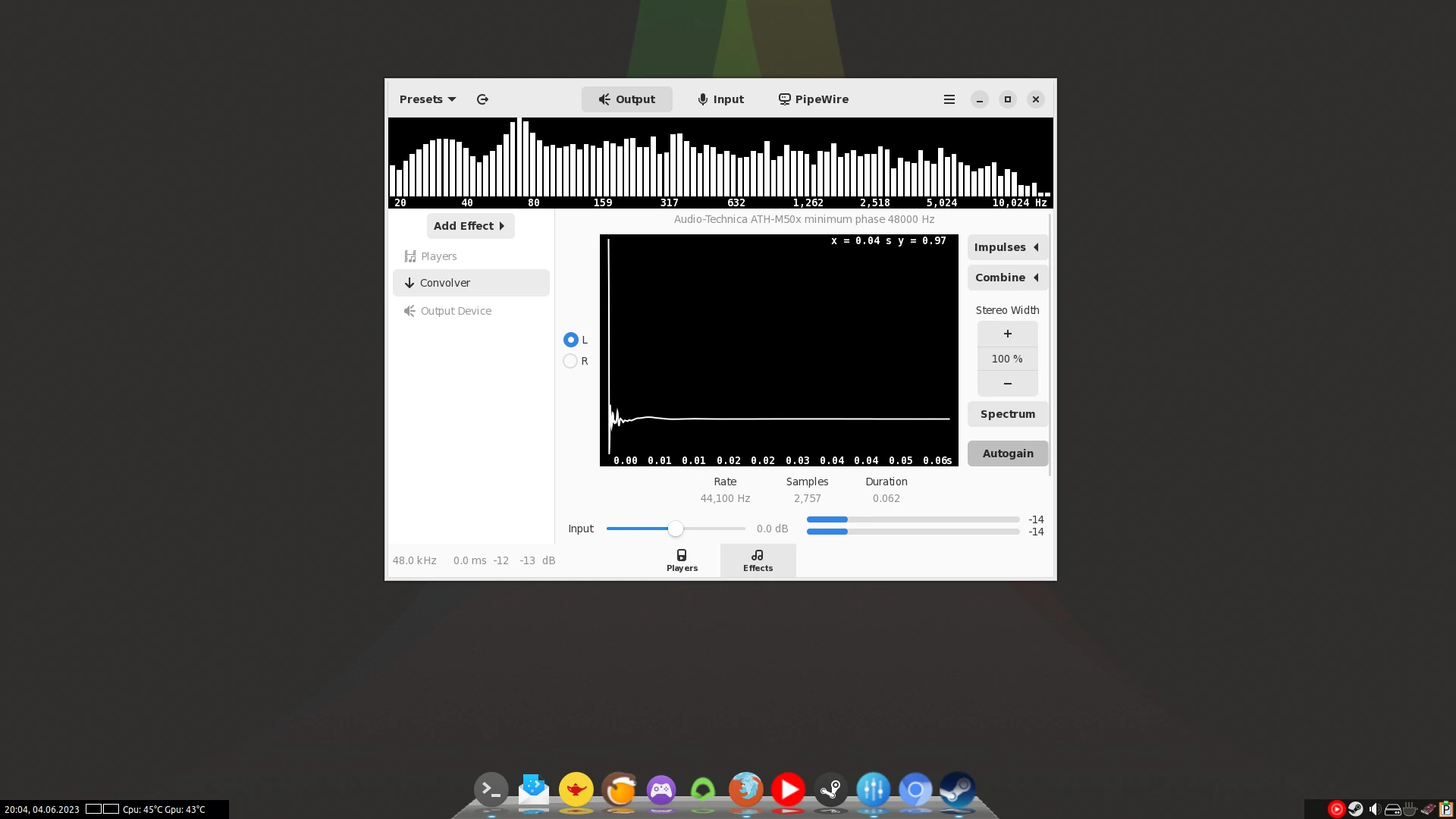
Wechsel in die Effektliste und füge das Plugin Convolver hinzu. Dort auf der rechten Seite auf den Button "Impulses" klicken. Darüber kann die eben heruntergeladene .wav-Datei importiert werden. Danach fehlt noch ein Klick auf "Load", wieder unter Impulses und neben dem eben hinzugefügten Eintrag, nun sollte der veränderte Klangeffekt direkt eintreten.
Wieviel dieser Ansatz bringt variiert natürlich extrem, je nach Kopfhörer und auch je nach Musik. Bei meinem M50x scheint mir der Effekt relativ dezent – was gut ist, sind seine Messwerte doch auch ohne jede Anpassung gut. Manche Instrumente werden leichter hörbar, auch der Sänger von Greta Van Fleet. Das war zumindest bisher nicht unangenehm, aber ich werde es mit mehr Musik testen, bevor ich entscheide ob ich dieses Profil dauerhaft aktiviere.
Aber vom M50x mal abgesehen: Generell ist es nett, die Möglichkeit zu haben den Klang zu konfigurieren. Ich frage mich, ob es neben dieser AutoEq-Anpassung an ein Zielklangprofil noch andere interessante Effekte gäbe? Dass neben der Ausgabe auch das Mikrofonsignal mit bearbeitet werden kann, inklusive Lärmfilter (wie unter Alsa, aber einfacher zu konfigurieren), kann definitiv praktisch sein. So spielt PipeWire langsam ein paar Stärken aus.
Update 05.08.2023: Ich habe Easy Effect gerade aus dem Autostart genommen. Zwei Probleme nervten mich: Gelegentlich konnte das System plötzlich keinen Ton mehr ausgeben, bis in pavucontrol zwischen dem echten und dem virtuellen Output gewechselt wurde. Und heute war auf einmal nur noch Ton auf der linken Seite des Kopfhörers, bis zum Reboot. Solche Probleme gab es vorher nicht, daher vermute ich die Schuld bei Easy Effect und verzichte zumindest eine Weile auf den Equalizer.
Android 12 für das LG G5 via LineageOS 19.1
Monday, 17. April 2023
Überraschenderweise ist für das LG G5 eine neue Version von LineageOS veröffentlicht worden. LineageOS 19.1 basiert auf Android 12L. Das ist überraschend, weil der alte Kernel des Telefons ein Upgrade über Android 11 hinaus vorher verhinderte. Doch es wurde jetzt schlicht eine neuere Kernelversion (4.4) auf das Gerät portiert, selbst Android 13 erscheint nun möglich.
Eine gute Neuigkeit für alle, die bereits LineageOS oder ein anderes Custom-ROM auf dem Gerät am Laufen haben. Wer bis jetzt noch auf die Originalversion setzte geht dagegen leer aus – denn LG hat mit ihrer Mobilabteilung auch den Server abgeschaltet, mit dem der Bootloader des Telefons freigeschaltet werden konnte, was für ein Einspielen des Updates aber nötig ist. Sympathische Firma das.
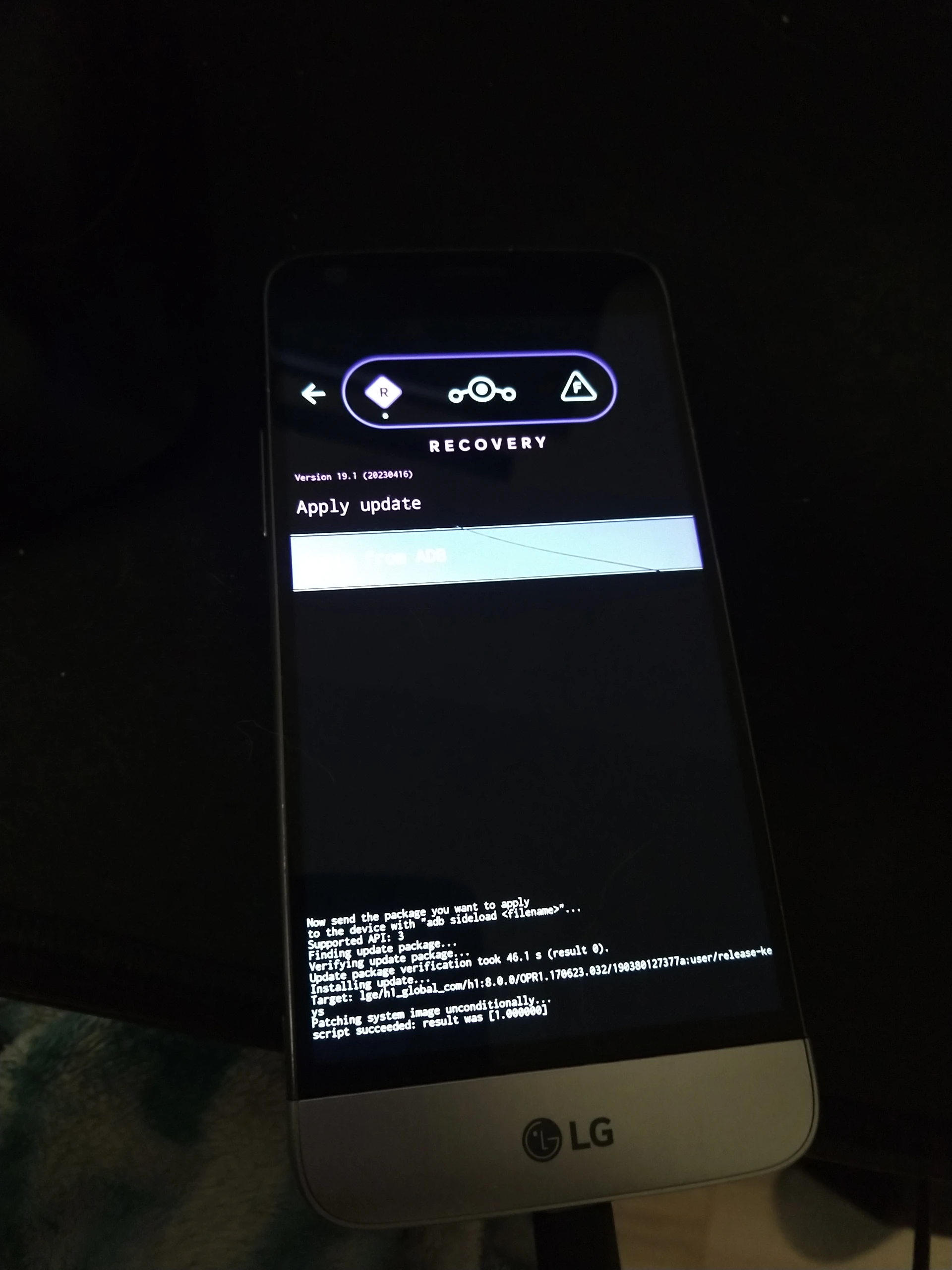
Um von LineageOS 18.1 auf 19.1 zu aktualisieren lädt man von der Downloadseite das Lineage-Ziparchiv und die recovery.img herunter. Eine Verschlüsselung auf dem Gerät muss laut meinem Test deaktiviert werden! Bei der Updateaktion sollten dann die eigenen Daten erhalten bleiben, aber man muss definitiv ein Backup parat haben.
Danach das Telefon verbinden, den Entwicklermodus freischalten, USB-Debugging aktivieren und der Rest geht am PC:
adb reboot bootloader sudo fastboot flash recovery Downloads/recovery.img sudo fastboot reboot
Das Telefon startet jetzt nochmal die alte Version von Lineage, das ist kein Problem. Nach diesem Neustart schicken wir das Gerät in den frisch installierten Recovery-Modus:
sudo adb reboot recovery
Das wäre alternativ auch per Tastenkombination gegangen (und so hätte der Lineagestart verhindert werden könnten), theoretisch, in der Praxis funktionierte bei mir nur dieser Weg über adb.
Im Lineage-Recovery-Programm Apply Updates auswählen und 19.1 kann installiert werden:
adb sideload Downloads/lineage-19.1-*-nightly-h850-signed.zip
Waren vorher die Google-Apps installiert müsste man sie jetzt wieder installieren, wie in der Upgradeanleitung beschreiben.
Nach dem nächsten Neustart sollte LineageOS 19.1 auf dem G5 starten.
Skyrim mit Mods unter Linux
Monday, 27. February 2023
Skyrim funktioniert mit Steams Proton unter Linux, das Spiel läuft sogar gut. Aber beim Modden ist fast die gesamte Dokumentation auf Windows ausgerichtet. So gibt es keinen nativ unter Linuxs laufenden Modmanager – abgesehen von modsquad, dessen Dokumentation mir aber ungenügend war. Doch das tolle: Es ist alles lösbar.

0. Die Erweiterungen kaufen
Das betrifft nur jene, die wie ich auch das originale Skyrim haben und nicht die neue Special Edition kaufen wollen. Das Problem ist: Das alte Spiel (auch Oldrim oder Skyrim LE genannt) ist samt seinen Erweiterungen von Bethesda im Steam-Shop versteckt worden. Und während die SE gerade reduziert war, blieb das Originalspiel und die DLCs sicher mit voller Absicht beim vollen Preis. Aber ohne die DLCs sind viele Mods nicht installierbar.
Als Lösung kaufe man die Skyrim Legendary Edition für Steam außerhalb von Steam. Auf CDKeys.com kostete sie ~7€ (kein Affiliate-Link, auch kannte ich die Seite vorher nicht). Ich hatte zuvor nur das Grundspiel, durch den Kauf wurden die Erweiterungen dem hinzugefügt.
Die alte Version hat Nachteile zur neuen: Sie sieht wohl (ohne Mods) schlechter aus und viele neue Mods werden nur noch für die SE veröffentlicht. Vorteil der LE sei die bessere Performance, zudem ist derzeit die Modauswahl für diese Version noch größer; Außerdem ist sie beim Kauf über CDKeys günstiger.
Wer SSE schon hat oder lieber damit spielen will sollte diesem Artikel trotzdem folgen können. Am Modden ändert sich nichts grundlegendes, eigentlich ist nur die Modauswahl etwas anders.
1. SKSE ist per Steam installierbar
SKSE ist fast unabdingbar. Die Software erweitert Skyrim um Skriptmöglichkeiten, die von einigen Mods gebraucht werden. Und da sind fundamentale dabei. SKSE kann dabei für das original Skyrim einfach per Steam installiert werden, per Shopseite. Spieler der SE laden es dagegen vom Nexus.
Wer die LE hat kann hier abbrechen. Oldrim hat einen Steam-Workshop mit einer gar nicht mal so geringen Auswahl. Zusammen mit SKSE lässt sich das Spiel jetzt schon deutlich verbessern. Wer aber Mods aus dem Nexus installieren will (oder muss, weil er auf die SE gesetzt hat) sollte weitermachen.
2. Mod Organizer 2 hat einen Linuxinstaller
Die Nexusmods lassen sich auch manuell installieren – dann werden die Texturen und .esps per Hand in den Data-Ordner von Skyrim geschoben. Aber das bricht natürlich irgendwann zusammen, vor allem wenn ein inkompatibler Mod wieder entfernt werden soll. Besser ist ein Modverwalter wie Mod Organizer 2.
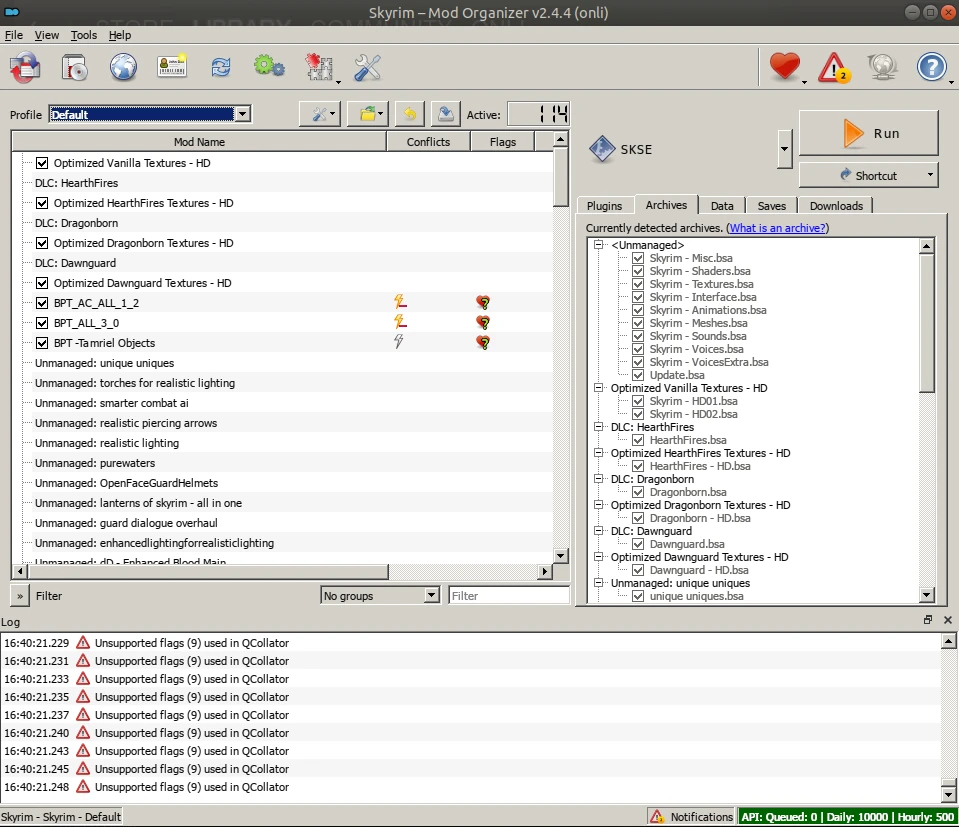
Und der lässt sich per diesem Repo unter Linux installieren. Die in der Readme beschriebenen Installationsschritte sind dabei nicht kompliziert:
- Das Spiel in Steam installieren.
- Den Installer des letzten stabilen Release herunterladen.
- Das heruntergeladene Archiv entpacken.
- Im Ordner
./install.shausführen. - Dem Installer folgen.
- Wenn danach in Steam Skyrim gestart wird, startet stattdessen der Mod Organizer 2. Neben der Modverwaltung dort kann von hier aus das Spiel selbst gestartet werden.
Die Installation forderte eine bestimmte Proton-Version, die in den Steam-Einstellungen von Skyrim gesetzt werden sollte. Bei mir war das Proton-6.3 und ich habe mich dran gehalten.
3. ENBoost (Teil von ENBseries) wird irgendwann gebraucht
Jetzt läuft Skyrim mit vollem Modsupport, was ich richtig nutzen wollte. Was anfangs gut lief kippte irgendwann: Das Spiel wurde instabil. An diesem Punkt war die einzige Lösung ENBseries. Auch wenn der obere ModOrganizer-Installer auf Github dagegen empfiehlt.
Die Installation von ENBseries ist wieder leicht, es wird nur durch eine vermurkste Webseite erschwert. Das Modprojekt Step erklärt es aber eigentlich ganz gut. Man geht über die News-Sektion der Webseite auf Download, klickt dann auf den Spielnamen und landet dadurch auf der Release-Seite. Die Versionsnummern ganz unten sind entgegen ihrer Darstellung klickbar. Auf der folgenden Seite ganz unten ist der Downloadlink.
Das heruntergeladene Archiv entpacken und manuell die d3d9*.dll-Dateien, enbhost.exe und enblocal.ini in den Skyrim-Ordner schieben.
Jetzt kann man wieder der Step-Seite folgen um ENBoost zu aktivieren. Ich werde dazu allerdings noch meine eigenen Konfigurationshinweise nachliefern.
Und auch wenn Step und das Crashfixplugin davor warnten muss ich zwischendurch in der enblocal.ini ExpandSystemMemoryX64=true setzen. Danach aber entfernte ich ein paar Texturenmods und ich konnte das wieder entfernen, tatsächlich lief Skyrim mit de Einstellung nicht super stabil (aber besser als vorher), es ist besser sie nicht zu brauchen.
Ich war übrigens sicher, dass ENBSeries unter Linux nicht laufen würde, zu oft hatte ich das früher gelesen. Aber früher ist da wohl das Stichwort. Tatsächlich läuft ENBSeries gut und Skyrim damit stabiler als vorher. Sogar Grafikerweiterungen scheinen zu funktionieren, wobei ich angesichts der Performancekosten damit nur ganz kurz experimentiert habe.
4. Das High Poly Project ist ein Performancekiller
Thema Performance: Es gibt im Nexus das High Poly Project. Objekte bekommen mehr Polygone, dadurch werden Rundungen erstmals wirklich rund. Doch zumindest unter Linux, oder unter Linux mit meiner Radeon RX 570, tut der Mod der Performance gar nicht gut.
Das war nicht unbedingt absehbar, weil der Autor keine Performanceprobleme beobachtete und es auch sonst in den Kommentaren keine direkt sichtbaren Warnungen gab. Also, Finger weg, oder sorgfältig testen.
5. Schatten können gut aussehen
Das größte Problem nach der Installation waren für mich auch gar nicht die Texturen oder fehlende Rundungen der Objekte, es waren total kantige Schatten. Ich musste erst nachlesen um zu glauben, dass Skyrim schon damals da so kaputt war, ich dachte das lag an Linux (und nehm es deswegen hier auf). Um die Schatten zu reparieren muss die .ini angepasst werden. Doch Vorsicht, die im Dateisystem platzierte wird durch den Mod Organizer 2 ignoriert. Stattdessen muss man den INI-Editor der Software nutzen.
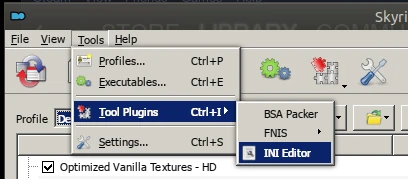
Die wichtigste Einstellung war für mich in der skyrimprefs.ini: iShadowMapResultion=8192. Später reduzierte ich das auf 4096, zugunsten der Performance. Wieder ist Step hier hilfreich.
2023 Skyrim mit seinen vielen Mods zu spielen macht mir das Spiel wesentlich sympathischer. Denn meine Erinnerungen an meinen ersten Durchlauf vor einigen Jahren sind gemischt – das Spiel hat was, aber einiges störte mich auch, ich vermisste Morrowind. Einige der Schwachstellen sind durch Mods mittlerweile verbesserbar und Modden selbst ist ja auch ein interessantes Spiel. Dadurch läuft meine Zeit mit Skyrim diesmal deutlich besser.
Ich plane zwei Folgeartikel: Einmal möchte ich näher auf die verschiedenen Konfigurationsänderungen und Mods eingehen, die das Spiel mit vielen Mods unter Linux stabiler machen. Der zweite soll alle anderen Mods vorstellen, die mir diesmal das Spiel verbessern, als Update zu meinem Modartikel von 2016.
Samsung A3 (2016) auf Android 11/LineageOS 18.1 updaten
Monday, 30. January 2023
Das A3 (SM-A310F, oder: a3xelte) bekam von Samsung nur Android 7. Mit LineageOS als Custom Rom geht mehr, es wäre schade das kleine Telefon nicht damit zu versorgen.

Wer einfach nur die Anleitung haben will sollte unter Installation weiterlesen. Ich werde nämlich jetzt erstmal erklären, was ich von dem Gerät halte und wie meine Erfahrung mit dem Flashen war. Denn es lief diesmal nicht problemlos.
Kontext und Einschätzung
Es gibt mehrere verschiedene A3. Dieses "A3 (2016)" ist tatsächlich von Ende 2015 und ist damit nicht besonders neu. Bei sustaphones ist es gelistet, weil es früher offiziell von LineageOS 17.1 unterstützt wurde. Das ist leider vorbei, keines der größeren Projekte unterstützt das Telefon noch, die von mir installierte war eine inoffizielle Version. Vielleicht spielt da eine Rolle: Das Telefon war superzickig. Lief die erste Installation der TWRP-Recovery-Software noch durch, musste ich sie wiederholen (weil ich nicht schnell genug reagierte und Samsungs Androidversion sie beim Start löscht), was dann leider nicht mehr klappte. Daraufhin startete das Telefon nicht mehr, sondern blieb immer beim ersten Schritt im Bootvorgang mit dem "Galaxy A3[6]"-Logo hängen. Da der Odin-Download-Modus noch startete war das lösbar, aber nur mit einer speziellen Kombination aus einem Heimdall-Fork und einer älteren TWRP-Version, dazu unten mehr. Zwischendurch war ich sicher, das Gerät nur noch wegwerfen zu können.
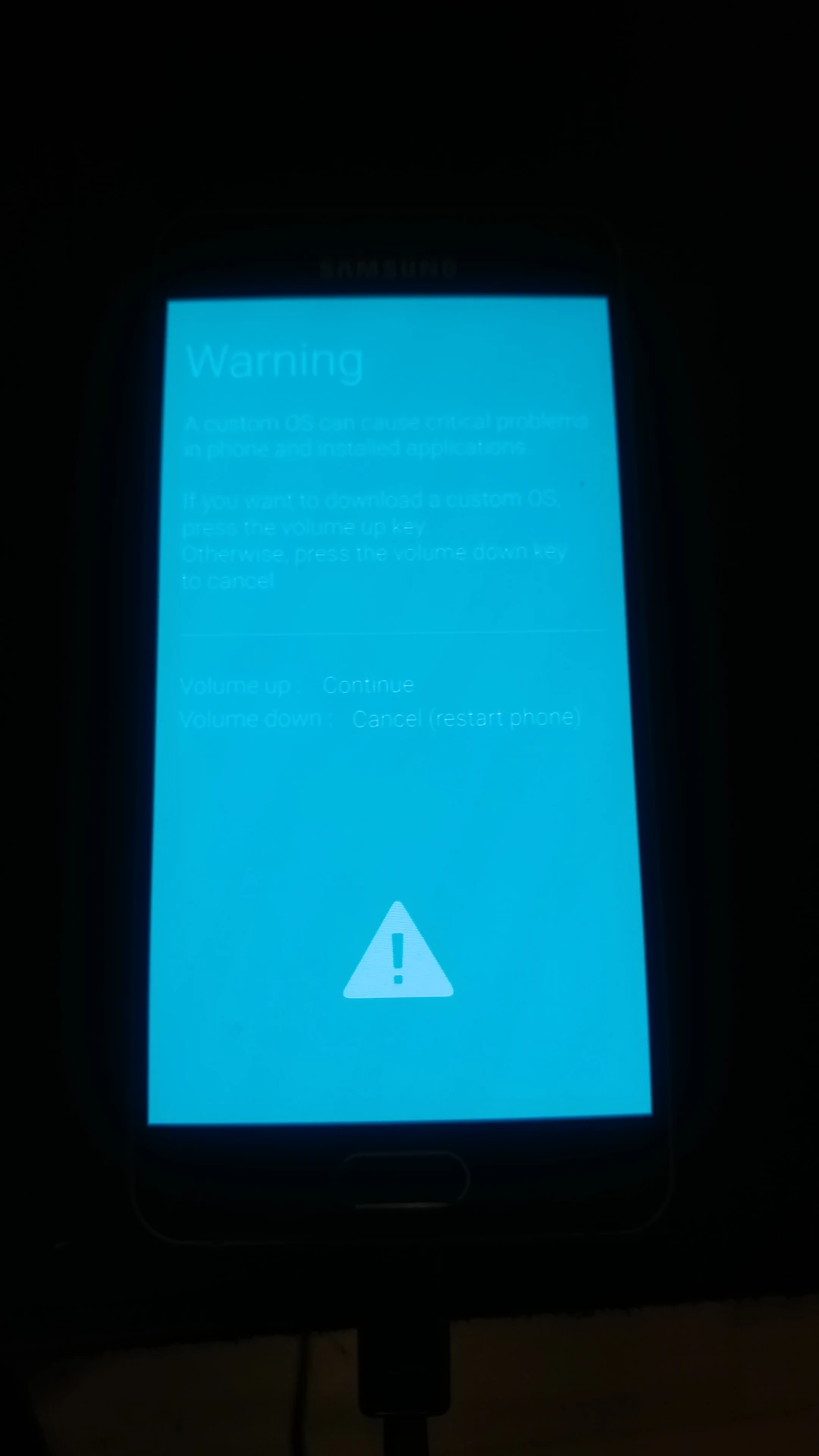
Man sollte sich also gut fragen ob der Aufwand lohnt. Ich las zwar auch Berichte von Leuten, bei denen das A3 problemlos mit einer neuen Androidversion zu flashen war. Aber Fehlerberichte gibt es ebenfalls Unmengen. Und das alles wofür? Das A3 ist zwar hübsch klein, der Bildschirm und die Kamera wirkt auf dem ersten Blick nicht schlecht, der Speicher ist sogar erweiterbar. Aber der Prozessor ist langsamer als z.B. der des LG G5 aus der gleichen Zeit, der Lautsprecher ist schrottig, vor allem aber ist der Akku nicht einfach auswechselbar. Wenn man aber schon bei Telefonen mit nicht einfach auswechselbarem Akku ist, dann gibt es Unmengen an stärkeren Alternativen mit besserer Romversorgung (z.B. das OnePlus 7 Pro).
Doch andererseits: Das alte A3 wird ja eher deswegen gewählt, weil es schon da ist und nicht im Schrank versauern soll, es wird ja wohl nicht extra gekauft. Dann lohnt es sich in jedem Fall, die folgende Anleitung nachzuvollziehen.
Installation
Die Kurzfassung: Das A3 muss erst vorbereitet werden, dann wird mit Odin (Windows) oder Heimdall (Linux) TWRP als Recovery installiert, womit dann das Rom geflasht werden kann. Ich wählte hier LineageOS 18.1, es gibt aber im xda-Forum auch eine Alpha von LineageOS 20. Lokale Daten wie installierte Apps werden dabei gelöscht!
Ich nutze Linux, also ist auch die Anleitung auf Linux ausgerichtet. Für Windows habe ich aber jeweils dazugeschrieben wie es gehen sollte – üblicherweise sind solche Anleitungen für Windows (und der Windowssoftware Odin) geschrieben, daher findet man anderswo auch alles nochmal zum nachlesen. Statt Heimdall unter Linux ebenfalls Odin (mit Wine) zu benutzen wäre eine testenswerte Alternative, vor allem wenn man sich die Kompilierung des Heimdall-Forks sparen will.
0. PC vorbereiten
Auf dem PC sollte adb installiert sein, das liegt unter Linux in den Quellen, für Windows möge man dieser Anleitung folgen. Unter Windows könnten auch Samsungs USB-Treiber gebraucht werden.
1. Telefon vorbereiten
Zuerst alle Updates durchlaufen lassen, insbesondere die für das System selbst. Da gab es 2020 das letzte, das auf meinem Gerät z.B. noch fehlte.
Sicher nun die Daten auf dem Gerät, die du behalten willst, irgendwo extern.
Dann muss der Entwicklermodus aktiviert werden. In den Einstellungen auf "About Phone" und dort siebenmal auf den Eintrag "Build Number" drücken. Eine kleine Einblendung sollte die Aktion bestätigen.
Dadurch gibt es in den Einstellungen einen neuen Eintrag mit den Entwickleroptionen. Dort müssen zwei aktiviert werden:
- OEM Unlock
- USB Debugging
2. Linux: Heimdall installieren & Recovery installieren
Jetzt kann das A3 in den Downloadmodus gesetzt werden, indem zum Start gleichzeitig die Knöpfe Power + Home + Lautstärke runter gedrückt und gehalten werden.
Unter Linux könnte man nun mit Heimdall die Recovery-Software aufspielen. Doch leider ist Heimdall nicht ohne weiteres mit dem A3 kompatibel, die in den Quellen verfügbare Version wird nicht funktionieren. Stattdessen kompilieren wir diese Version selbst, die einen Workaround eingebaut hat. Dafür braucht es die Pakete git, build-essential und cmake sowie ein paar weitere, die auch der Readme entnommen werden können (zlib1g-dev, qt5-default, libusb-1.0-0-dev. libgl1-mesa-glx, libgl1-mesa-dev; Paketnamen können abweichen). Dann:
git clone https://github.com/changlinli/Heimdall cd Heimdall mkdir build cd build cmake -DCMAKE_BUILD_TYPE=Release .. make cd bin/
Als Test ziehen wir nun die PIT-Datei, mit der das Telefon später vielleicht gerettet werden könnte falls etwas schiefginge:
sudo ./heimdall print-pit --file a310f_orig.pit
Das Telefon sollte nun neustarten, mit der Tastenkombination direkt wieder in den Downloadmodus setzen.
Kommen wir zur Recovery. TWRP kann von der TWRP-Seite heruntergeladen werden. Allerdings funktionierte die derzeit aktuelle 3.7.0 bei mir nicht. Stattdessen sollte die twrp-3.4.0-0-a3xelte.img gewählt werden, die ging.
Mit dem Telefon im Download-Modus, verbunden mit dem PC via eines USB-Kabels, kann das frisch kompilierte Heimdall nun die Recovery installieren:
sudo ./heimdall flash --RECOVERY twrp-3.4.0-0-a3xelte.img --no-reboot
oder 2. Windows: Odin installieren & Recovery installieren
Ich habe die Installation unter Linux durchgeführt. Unter Windows würde man statt Heimdall Odin benutzen. Ich verweise auf netzwelts Android: So führt ihr ein Custom Recovery auf Samsung-Smartphones durch. Auch hier würde ich von TWRP die 3.4.0 installieren.
3. LineageOS flashen
TWRP ist frisch installiert, würde aber entfernt werden, wenn das Telefon regulär neustartet. Stattdessen beenden wir den Downloadmodus mit Power + Lautstärke runter und drücken und halten direkt die Kombination für den Recovery-Modus: Power + Home + Lautstärke hoch. Es startet TWRP.
Auf dem PC laden wir LineageOS 18.1 aus dem xda-Forum herunter.
In TWRP geht es zu Wipe -> Advanced Wipe, dort Cache, Data und System auswählen und wipen.
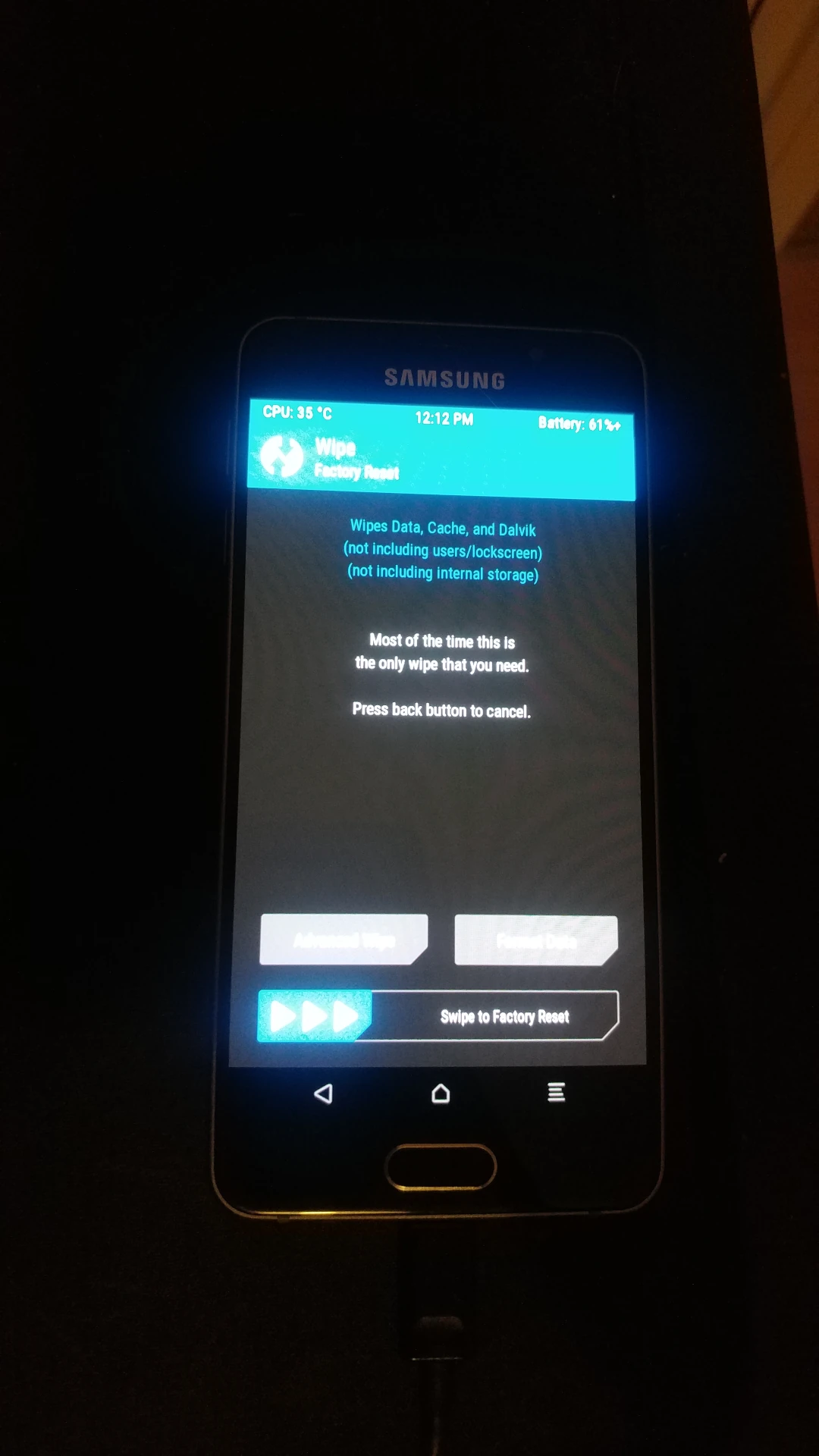
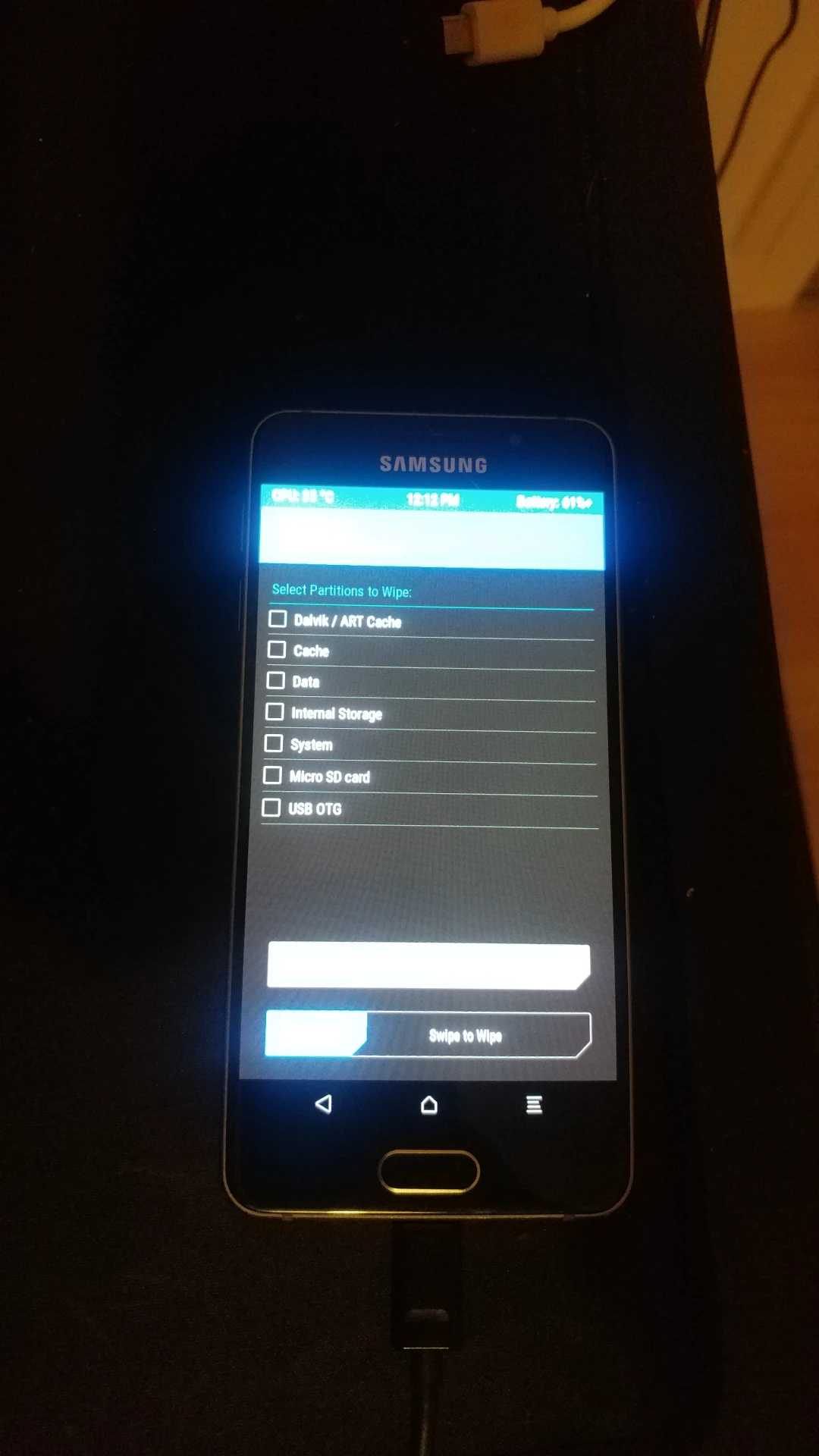
Dann zu Advanced -> Sideload, durch swipe bestätigen. Das gerade heruntergeladene zip kann nun installiert werden:
adb sideload lineage-18.1-20230118-UNOFFICIAL-a3xelte.zip
Wer mag installiert jetzt noch genauso die Open GApps (ARM64, Android 11), ich verzichtete.
Wenn TWRP eine TWRP-App installieren will sollte das verneint werden.
Jetzt neustarten und das A3 sollte direkt LineageOS laden.
Mit LineageOS soll das A3 komplett funktionieren. Ich testete den Lautsprecher, Anrufe und die Kamera, schien zu passen, auch der Akku hielt ordentlich.
Wer keine GApps installiert hat und das nicht gewöhnt ist, dem empfehle ich direkt F-Droid herunterzuladen. Von dort bezieht man dann Firefox (Fennec) mit Ublock und alles andere was man braucht, wenn es Apps aus dem Play Store sein müssen kann Aurora die installieren (nicht alle gehen dann auch ohne GApps, aber viele). Vielleicht ist ansonsten meine eigene App-Liste eine Orientierungshilfe.
Verbesserungen für sustaphones: Ankerlinks, Design, Romauswahl
Wednesday, 18. January 2023
Sustaphones, meine Webseite zum Finden reparierbarer und von Android-Roms unterstützten Telefonen, hat ein paar Updates bekommen.
Diese beiden Screenshots zeigen den Unterschied (die alte Version zuerst):
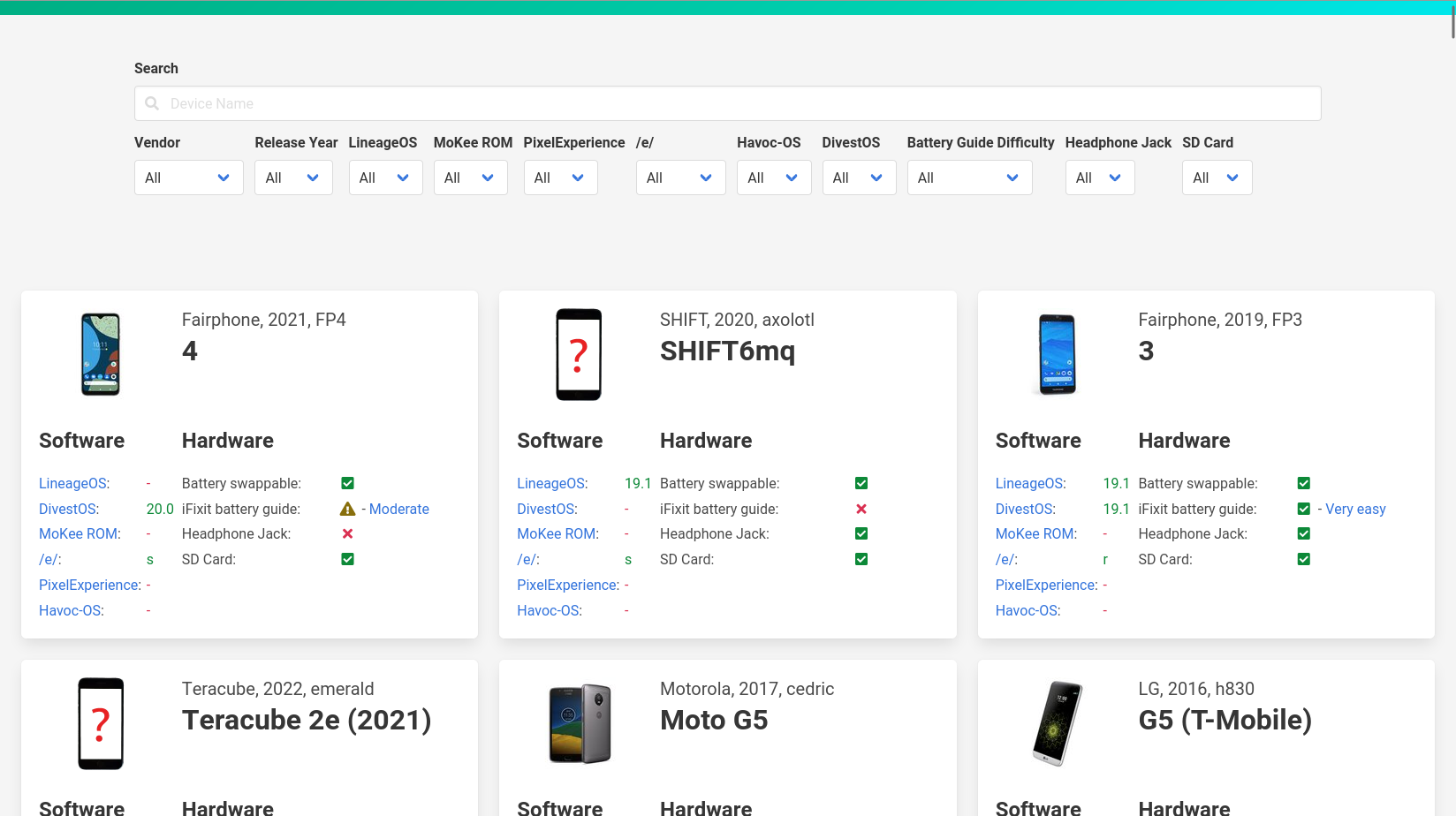
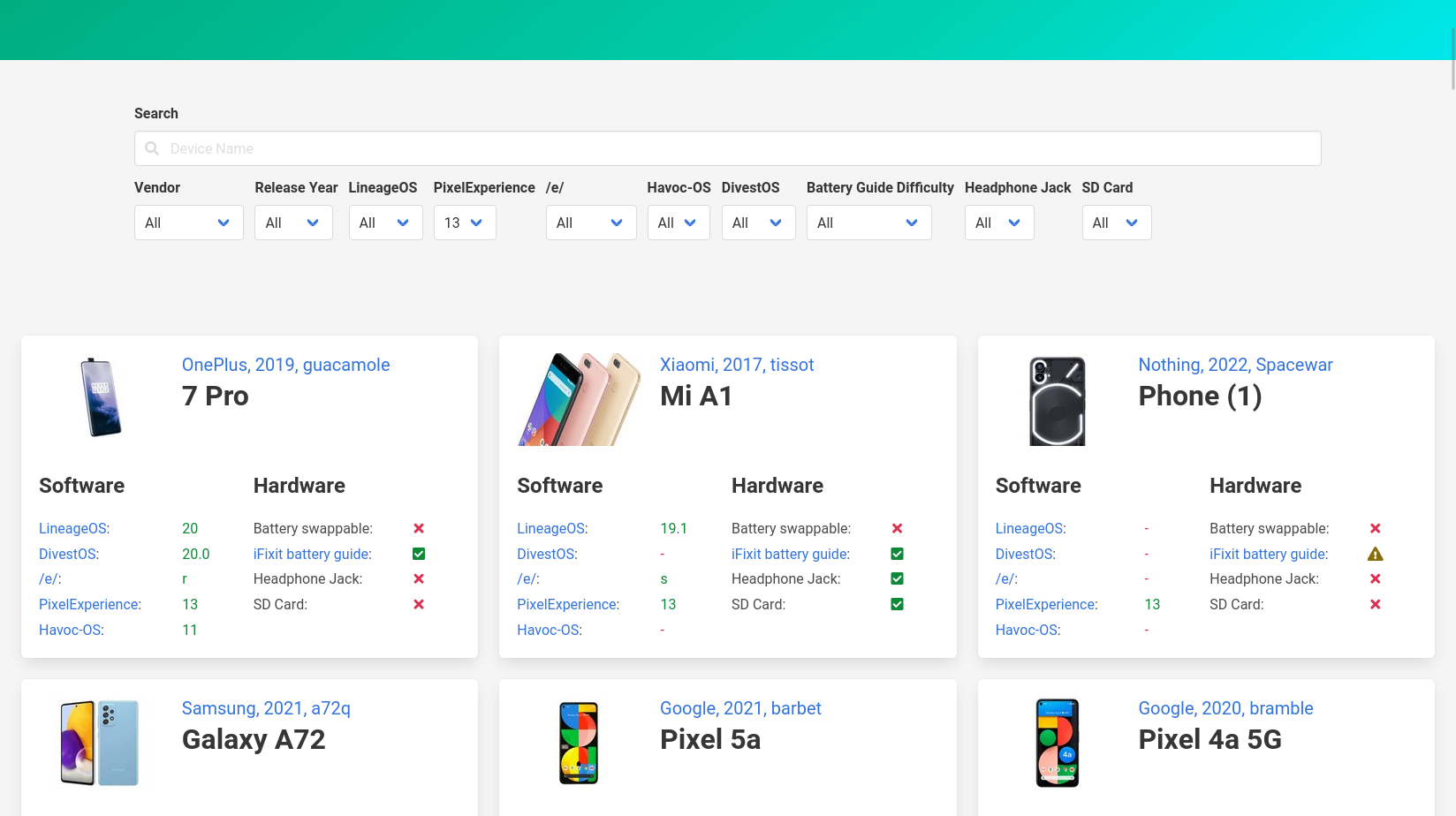
Kein großer Umbau, aber praktische Änderungen sind dabei:
- Die einzelnen Boxen haben nun oben einen Ankerlink, der die Seite an die jeweilige Stelle scrollt. Anlass dazu war dieser gnulinux.ch-Artikel zum Fairphone 2, der seine Erkenntnisse über ein spezielles Telefon nicht verlinken konnte. Jetzt ginge das.
- Um das Design etwas symmetrischer zu machen ist der Link zur iFixit-Akkuwechselanleitung nach vorne in das Label gerutscht und steht nicht mehr extra hinter dem Icon. Dadurch konnten die Software- und Hardwarebereiche in der Box gleich groß werden. Das trennt gleichzeitig den unteren Bereich visuell besser vom oberen Bereich ab, bei dem Bild und Titel immer noch 33% und 66% des Platzes einnehmen.
- MoKee gibt es nicht mehr, dementsprechend wurde es aus der Liste genommen.
- Da LineageOS so betont hat, dass die neue Version 20 und nicht 20.0 sei, habe ich auch bei den anderen Roms die Versionsnummern angepasst (zumindest wo das jeweilige Projekt sie nicht eindeutig als X.0 benennt, wie bei DivestOS).
- Generell lief ein Update aller Parser, insbesondere bei PixelExperience war das überfällig. Darüber wurden auch ein paar neue Telefone hinzugefügt, wie das Nothing Phone(1).
Ich möchte noch erwähnen, dass Havoc-OS auf meiner Abschussliste steht, dem Changelog zufolge ist das Projekt ziemlich inaktiv und auch bei ihrer Geräteliste hat sich nichts getan. Aber das werde ich noch etwas beobachten.
Änderungswünsche (die per Gitlab auch selbständig umgesetzt werden könnten) sind gern gesehen, ebenso Vorschläge zum Einbinden anderer Android-Projekte.

