Mit Easy Effects und AutoEq den Kopfhörerklang verbessern
Monday, 5. June 2023
Durch PipeWire wird es einfach, einen systemweiten Equalizer zu setzen und damit potentiell den Ton des eigenen Ausgabegerätes anzupassen. Easy Effects ist (unter anderem) ein solcher Equalizer, ist in den Quellen von Void Linux und funktionierte bei mir auf Anhieb. Doch was genau soll man einstellen? Da kommt die Webanwendung AutoEq ins Spiel. Mit ihr kann man für viele Kopfhörer passende Voreinstellungen abrufen und in Formate für verschiedene Equalizer umwandeln, darunter auch Easy Effects. Ich habe das für meinen ATH-M50x durchgespielt und beschreibe im Folgenden mein Vorgehen.
Mit AutoEq Konfiguration herunterladen
In der Suchleiste oben auf der Webseite kann nach dem eigenen Kopfhörermodell gesucht werden.
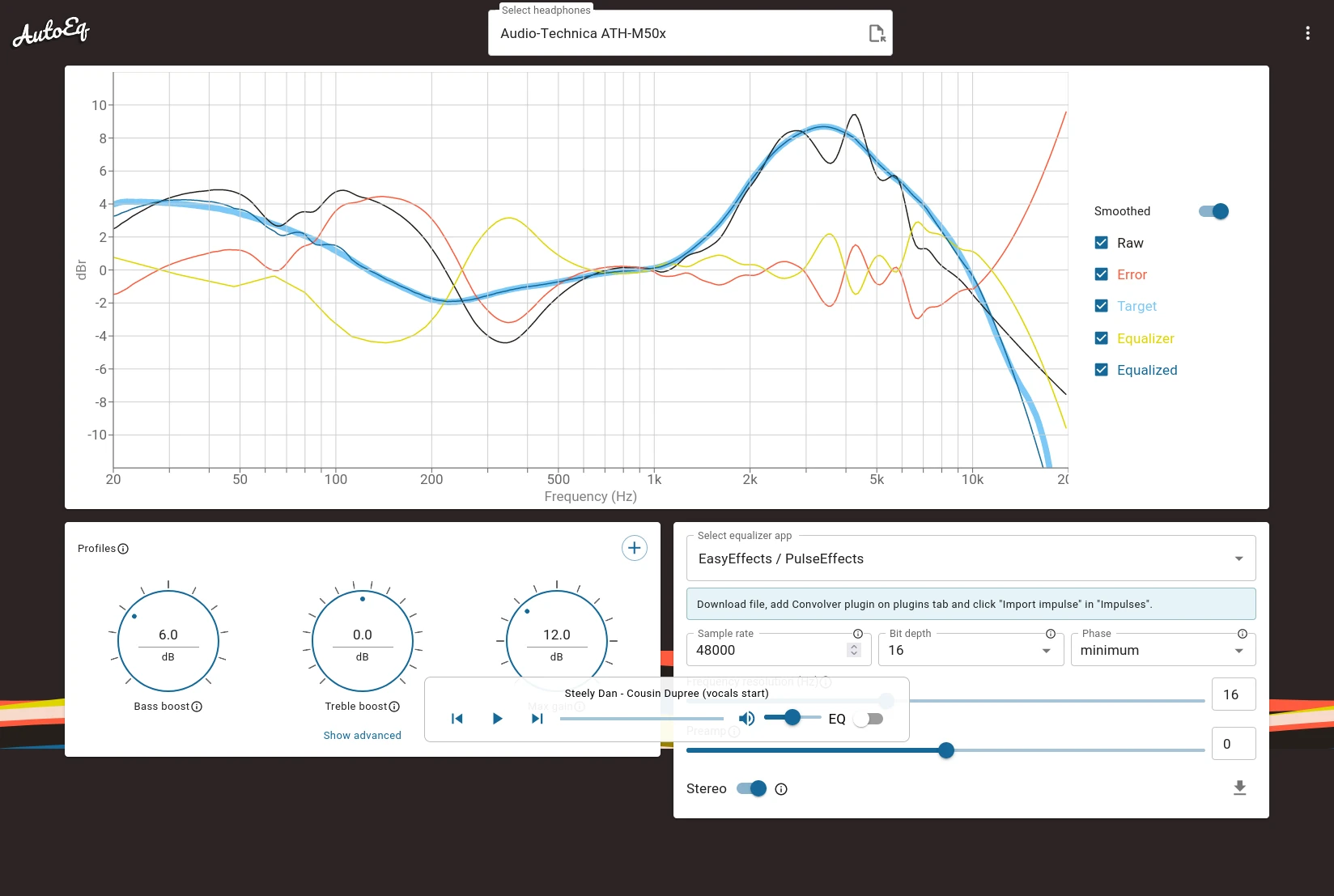
Einmal gefunden geht die Vorschau der Einstellungen auf. Rechts kann das Zielprogramm ausgesucht werden, Easy Effects ist als EasyEffects / PulseEeffects in der Liste. Bei der nun aufgehenden Konfiguration muss der Schalter für Stereo aktiviert werden. Ob 44.1kHz, 48kHz oder gar 96kHz richtig ist sollte an der Pipewire-Konfiguration hänge, im Zweifel ist es 44.1. Unten rechts versteckt sich der Download-Button als schwer zu erkennendes Icon.
Man kann die Konfiguration hier auch ändern. Hat jemand Hinweise, was man versuchen sollte?
Mit Easy Effects Konfiguration laden
Jetzt installieren wir Easy Effects. Unter Void ging das einfach mit
sudo xbps-install easyeffects
Das Programm startet der gleichnamige Befehl easyeffects.
In Easy Effects folgen wir nun den Anweisungen der AutoEq-Webseite:
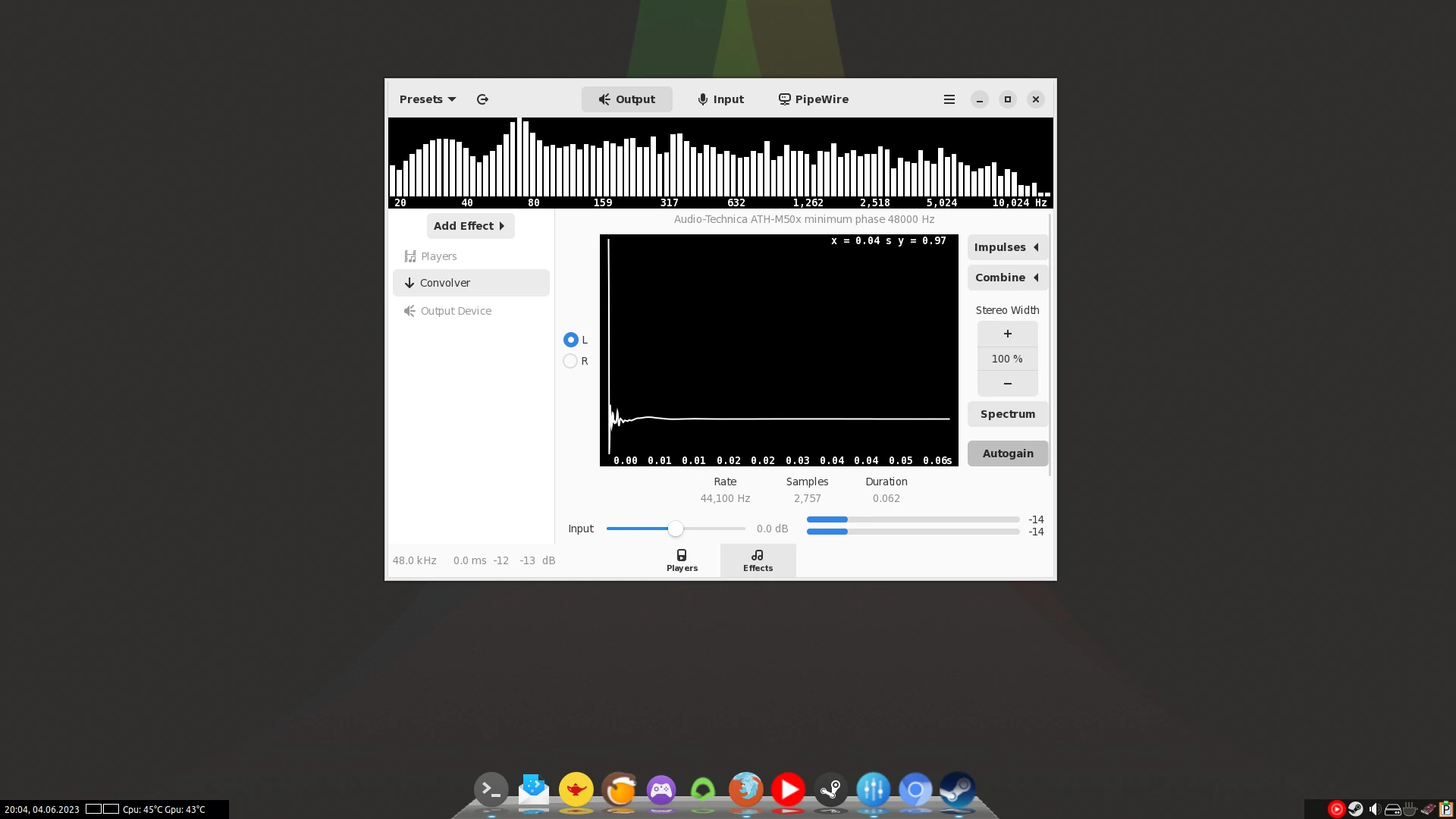
Wechsel in die Effektliste und füge das Plugin Convolver hinzu. Dort auf der rechten Seite auf den Button "Impulses" klicken. Darüber kann die eben heruntergeladene .wav-Datei importiert werden. Danach fehlt noch ein Klick auf "Load", wieder unter Impulses und neben dem eben hinzugefügten Eintrag, nun sollte der veränderte Klangeffekt direkt eintreten.
Wieviel dieser Ansatz bringt variiert natürlich extrem, je nach Kopfhörer und auch je nach Musik. Bei meinem M50x scheint mir der Effekt relativ dezent – was gut ist, sind seine Messwerte doch auch ohne jede Anpassung gut. Manche Instrumente werden leichter hörbar, auch der Sänger von Greta Van Fleet. Das war zumindest bisher nicht unangenehm, aber ich werde es mit mehr Musik testen, bevor ich entscheide ob ich dieses Profil dauerhaft aktiviere.
Aber vom M50x mal abgesehen: Generell ist es nett, die Möglichkeit zu haben den Klang zu konfigurieren. Ich frage mich, ob es neben dieser AutoEq-Anpassung an ein Zielklangprofil noch andere interessante Effekte gäbe? Dass neben der Ausgabe auch das Mikrofonsignal mit bearbeitet werden kann, inklusive Lärmfilter (wie unter Alsa, aber einfacher zu konfigurieren), kann definitiv praktisch sein. So spielt PipeWire langsam ein paar Stärken aus.
Update 05.08.2023: Ich habe Easy Effect gerade aus dem Autostart genommen. Zwei Probleme nervten mich: Gelegentlich konnte das System plötzlich keinen Ton mehr ausgeben, bis in pavucontrol zwischen dem echten und dem virtuellen Output gewechselt wurde. Und heute war auf einmal nur noch Ton auf der linken Seite des Kopfhörers, bis zum Reboot. Solche Probleme gab es vorher nicht, daher vermute ich die Schuld bei Easy Effect und verzichte zumindest eine Weile auf den Equalizer.
Mein neuer PC
Tuesday, 9. May 2023
Dass ich kürzlich über Hardwareupgrademöglichkeiten schrieb lag natürlich an meinen eigenen Upgradeplänen. Mein PC war angestaubt, dass die Radeon RX 6600 unter 250€ fiel hatte ich mir als Signal für ein Upgrade gesetzt. Zwar reichte mein altes System noch für alles wichtige, doch ich wollte moderne Spiele wie Cyberpunk auf ordentlichen Einstellungen spielen können.

Das alte System
Vorher hatte ich im PC einen 2019 gebraucht gekauften Intel Core i5-5675C, zusammen mit einer Radeon RX 570 (4GB). Der Prozessor ist etwas besonderes gewesen, der wenig verkaufte Broadwell-Chip hat einen L4-Cache – ähnlich wie jetzt der Ryzen 7 5800X3D – und eine besonders starke Grafikeinheit, die Intel ansonsten nur in Laptops verbaute. Der Cache machte den Prozessor in manchen Spielen besonders stark, als ich zwischendurch gar keine Grafikkarte hatte war die Grafikeinheit Gold wert. Doch da der i5 nichtmal Hyperthreading hat erreichte der Vierkerner nun seine Grenze.
Die Radeon RX 570 war nichts besonderes. Bestechend war damals nur ihr absurd gutes Preis-Leistungs-Verhältnis im Vergleich zu den Nvidia-Karten, die unter Linux aber sowieso keine Option gewesen wären. Auch bei ihr war für moderne AAA-Spiele die Leistung inzwischen etwas gering.
Der alte Rechner hatte ordentliche 24GB Ram, da aber DDR3 konnte das nicht weiterbenutzt werden. Dafür sollte Gehäuse, Netzteil, SSDs und Backupfestplatte erhalten bleiben, ebenso wie der Corsair H90 als Prozessorkühler – hatte ich das alles doch gerade erst dank fan2go leise bekommen.
Die neue Hardware
Das Upgrade lief in zwei Phasen, um zu schauen ob der Prozessor nicht doch ausreichen würde.
Also fing ich mit der Grafikkarte an. Es wurde eine Radeon RX 6600, die ASRock Challenger D. Sie kostete 229€ und war damit die günstigste der verfügbaren 6600er. Ich hatte von dem Modell wenig gelesen, aber dass der Lüfter sich im Leerlauf abschalten würde beruhigte mich. Dazu kamen positive Nutzerreviews und eine ebenfalls positive Besprechung bei OCinside.
Die Intel Arc A750 wäre die Alternative gewesen. Aber dann hätte ich auf jeden Fall das Prozessorupgrade gebraucht. Und ich fand dieses Review, demnach selbst unter einem aktuellen Kernel die Intel-Karten unter Linux deutlich hinter den AMD-Optionen liegen. Das ist unter Windows anders, aber ich spiele ausschließlich unter Linux.
Die 6600 würde mehr als doppelt so schnell wie meine alte Karte sein, das war vorab klar (die Bewertung im Benchmark entspricht nicht direkt dem gesehenen FPS-Unterschied):
Tatsächlich lief schon mit dem Grafikkartenupgrade dann auch Cyberpunk 2077 auf hohen Einstellungen und war spielbar. Aber die sehr hohe Prozessorauslastung und das generell niedrige FPS-Niveau machte klar, dass ein Prozessorupgrade doch sinnvoll wäre.
Da recherchierte ich sogar nochmal, blieb aber letzten Endes bei meiner eigenen momentanen Standardempfehlung: Ein Ryzen 5 5600 auf einem B450-Board. Mein Gehäuse ist mATX, also war bei den Mainboards die Auswahl begrenzt; Ich griff zum günstigsten mit vier Ramslots, dem MSI B450M PRO-VDH Max. Das kostete 72€. Der Prozessor kostete 119€. Dazu fehlte noch der Arbeitsspeicher, das wurde das günstige G.Skill Aegis DDR4-3000 32GB Kit für 58€.
16GB hätten zum Spielen gereicht, aber als Entwickler reichte mir das schon mehrfach nicht aus und ich wollte mich bei der Speichermenge nicht verschlechtern.
Um meinen Corsair H90 weiterverwenden zu können hatte ich mir vorab eine AM4-Halterung gekauft. Die kostete nur 8€.
Als die gesamte Hardware dann da war klappte alles. Das B450-Board brauchte wie erwartet kein BIOS-Update, um mit dem Ryzen 5 5600 zu starten – dafür ist der Prozessor viel zu lange draußen, die Boards im Handel sind alle bereits aktualisiert, aber die minimale Gefahr hatte mich doch nervös gemacht. Der XMP-Modus des Arbeittsspeichers griff direkt. Nur rBar konnte ich nicht aktivieren, weil dafür Secure-Boot und der UEFI-Bootmodus gebraucht würde, womit meine alte Void-Installation nicht starten wollte. Gut, dass ich nicht doch die Arc-Karte gekauft hatte.
In Cyberpunk war der Prozessor dann ein großes Upgrade. Die Radeon RX 6600 hatte im eingebauten Benchmark und niedrigen Einstellungen mit dem i5-5675C vorher 43 FPS geliefert, mit dem Ryzen-Prozessor wurden es 74 – und da war VSYNC an.

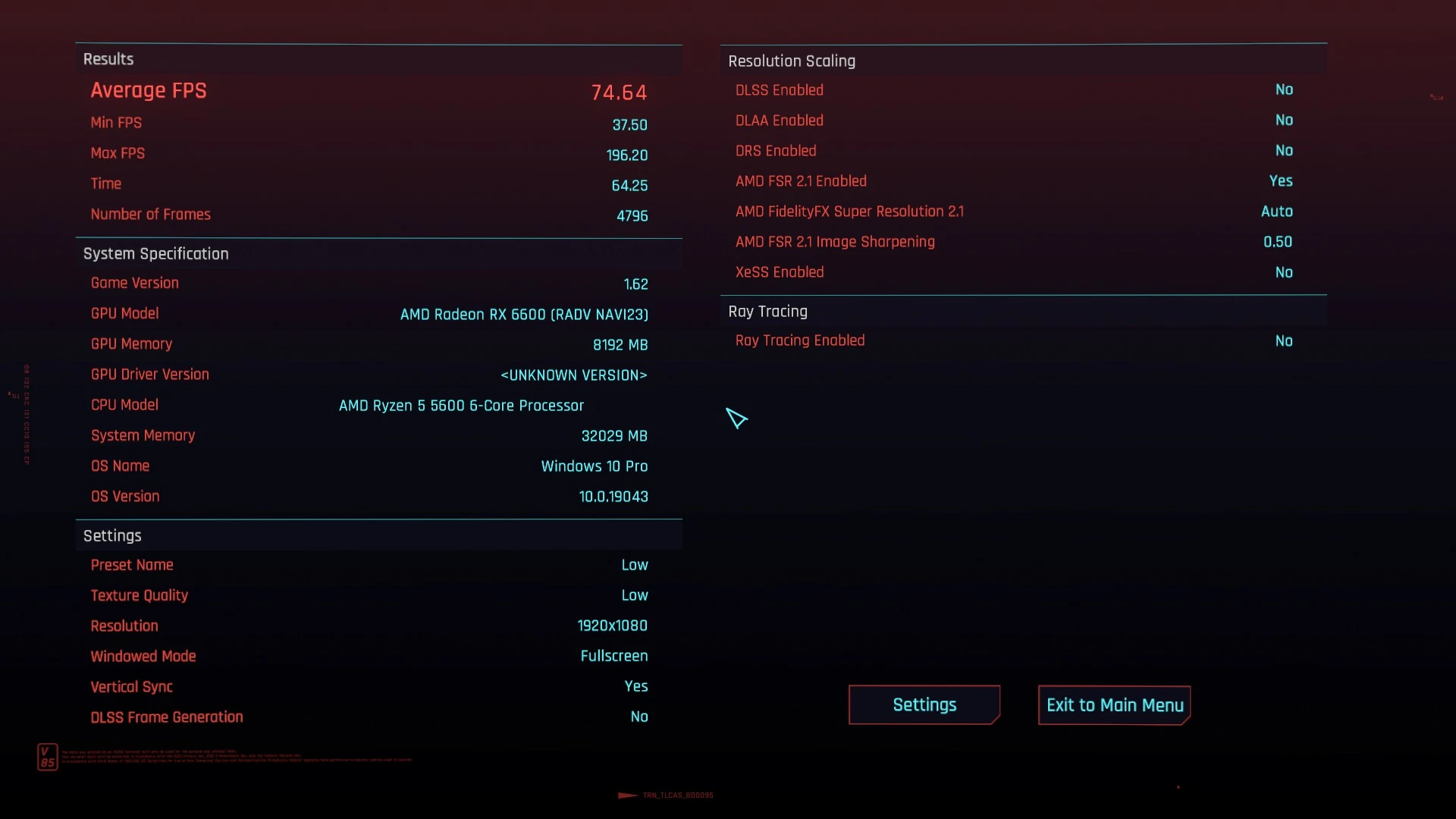
Im Spiel verschwanden einige Ruckler bei Kameraschwenks und mit meinen optimierten, generell hohen Einstellungen liegen die FPS je nach Szene zwischen 60 und 75 FPS. Davor waren die durchaus mal auf 30 gerutscht.
Das Upgrade lief gut und ich kann es empfehlen, die bessere Performance in Spielen ist schon angenehm. Mich freut es besonders, dass sich an der Lautstärke des Systems nichts negativ verändert hat – die Grafikkarte ist unter Last wohl sogar leiser als die auch schon dezente vorherige. Außerhalb von Spielen bemerkte ich bisher aber keinen Geschwindigkeitsgewinn, dafür war der i5-5675C wohl zu stark.
Mein System ist damit auf das Niveau von 2022 gerutscht. Das dürfte jetzt wieder für ein paar Jahre reichen.
Welche Hardwareupgrades gerade eine gute Idee sind
Tuesday, 25. April 2023
Android 12 für das LG G5 via LineageOS 19.1
Monday, 17. April 2023
Überraschenderweise ist für das LG G5 eine neue Version von LineageOS veröffentlicht worden. LineageOS 19.1 basiert auf Android 12L. Das ist überraschend, weil der alte Kernel des Telefons ein Upgrade über Android 11 hinaus vorher verhinderte. Doch es wurde jetzt schlicht eine neuere Kernelversion (4.4) auf das Gerät portiert, selbst Android 13 erscheint nun möglich.
Eine gute Neuigkeit für alle, die bereits LineageOS oder ein anderes Custom-ROM auf dem Gerät am Laufen haben. Wer bis jetzt noch auf die Originalversion setzte geht dagegen leer aus – denn LG hat mit ihrer Mobilabteilung auch den Server abgeschaltet, mit dem der Bootloader des Telefons freigeschaltet werden konnte, was für ein Einspielen des Updates aber nötig ist. Sympathische Firma das.
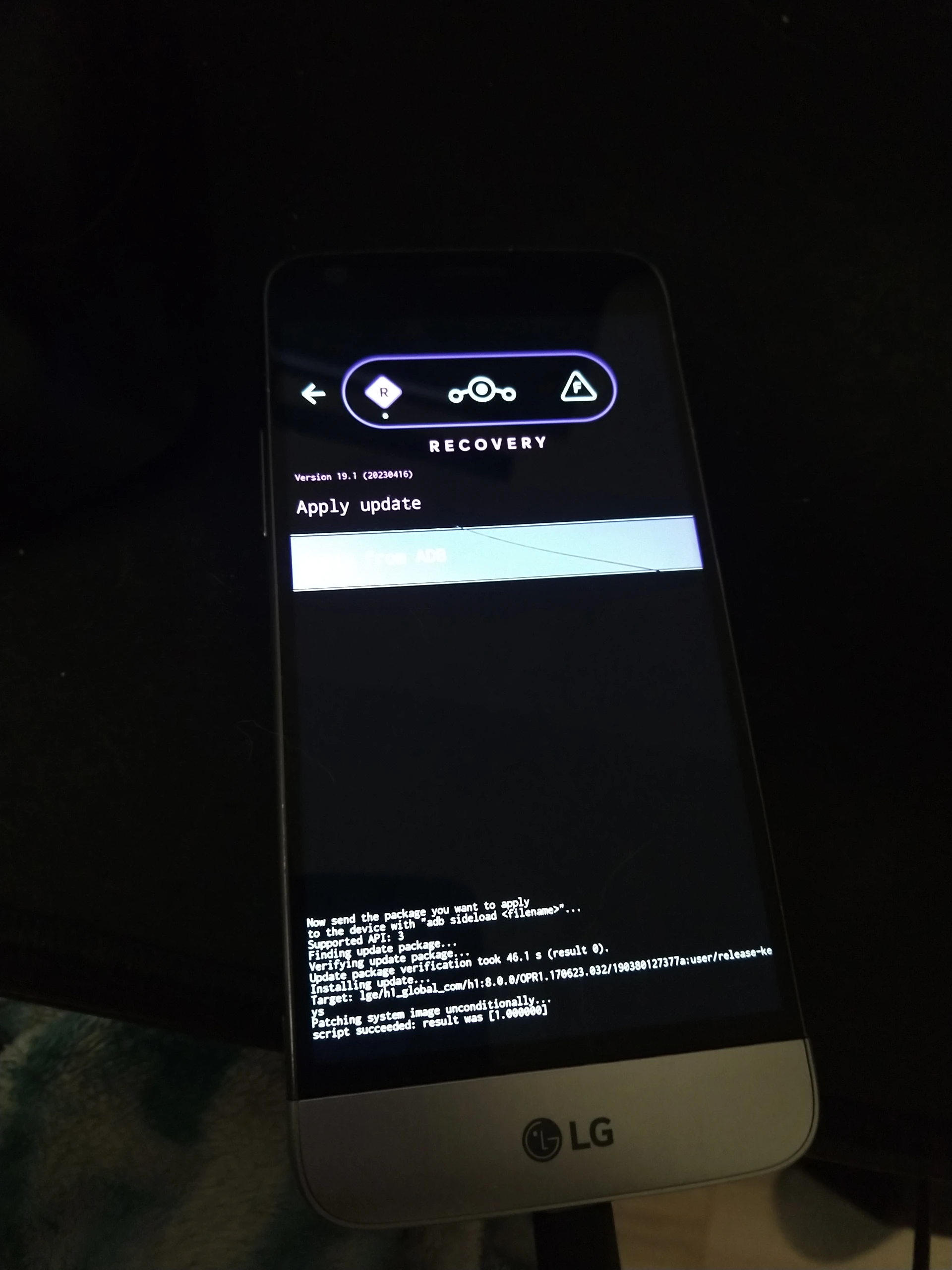
Um von LineageOS 18.1 auf 19.1 zu aktualisieren lädt man von der Downloadseite das Lineage-Ziparchiv und die recovery.img herunter. Eine Verschlüsselung auf dem Gerät muss laut meinem Test deaktiviert werden! Bei der Updateaktion sollten dann die eigenen Daten erhalten bleiben, aber man muss definitiv ein Backup parat haben.
Danach das Telefon verbinden, den Entwicklermodus freischalten, USB-Debugging aktivieren und der Rest geht am PC:
adb reboot bootloader sudo fastboot flash recovery Downloads/recovery.img sudo fastboot reboot
Das Telefon startet jetzt nochmal die alte Version von Lineage, das ist kein Problem. Nach diesem Neustart schicken wir das Gerät in den frisch installierten Recovery-Modus:
sudo adb reboot recovery
Das wäre alternativ auch per Tastenkombination gegangen (und so hätte der Lineagestart verhindert werden könnten), theoretisch, in der Praxis funktionierte bei mir nur dieser Weg über adb.
Im Lineage-Recovery-Programm Apply Updates auswählen und 19.1 kann installiert werden:
adb sideload Downloads/lineage-19.1-*-nightly-h850-signed.zip
Waren vorher die Google-Apps installiert müsste man sie jetzt wieder installieren, wie in der Upgradeanleitung beschreiben.
Nach dem nächsten Neustart sollte LineageOS 19.1 auf dem G5 starten.
Nie wieder Drift: Gulikits Hall-Joysticks für Joycons
Wednesday, 8. March 2023
Wenn eine Sache den Spaß an Nintendos Switch vermiesen kann, dann sind es die Joycons. Die sind teuer genug um sie nicht einfach ersetzen zu wollen, gehen aber schnell kaputt und fangen dann an zu driften. Das heißt, selbst ohne Druck geht die Spielfigur in eine Richtung, was viele Spiele unmöglich unangenehm macht. Würden neue Joycons wenigstens dauerhaft das Problem lösen wäre das halbwegs verzeihlich, sind das doch noch die Originalgeräte von kurz nach Release der Konsole… aber das tun sie nicht. Weil es an der genutzten Technik liegt (unweigerlich die Kalibrierung verlierende Widerstände) ist das Kaputtgehen immer nur eine Frage der Zeit.

Mit den Hall-Joysticks von GuliKit soll das anders sein. Die benutzen intern Magnete, was niemals driften soll. Der Hersteller verspricht zudem verbesserte Akkulaufzeiten. Theoretisch kann die Technik auch Deadzones unnötig machen, las ich, ich weiß nicht ob das hier geschieht. Die Lösung ist also ein Einbaukit, man ersetzt die defekten Joysticks der Originaljoycons mit diesen Alternativen.
Der (beim Draufschauen) linke Joycon der Switchbesitzerin an meiner Seite war am Driften, also hatte ich fast direkt bei Veröffentlichung das Ersatzkit bei AliExpress bestellt. Die Lieferung dauerte nicht lange (dieser Artikel erscheint mit deutlicher Verspätung).
Paketinhalt
Das hier kam an:

Ein Paket mit den beiden Ersatz-Joycon-Joysticks. Dazu einige Schrauben, zwei Schraubendreher, ein Plastik-Pick zum Öffnen und ein Gummi-Überzieher. Von dem Zubehör wäre nichts unbedingt nötig gewesen, aber gerade die Schraubendreher können praktisch sein wenn keine eigenen im Haus sind, die Schrauben wenn bei der Montage die Originalschrauben verlorengehen. So ein Plastikdreieck zum Öffnen fehlte sogar noch in meiner Werkzeugsammlung und die Gummi-Überzieher sind hübsch griffig.
Es wirkt schon nett, wenn statt einem notdürftig verpackten Einzelteil solch ein Sammlung ankommt. Auch wenn es verschwenderisch ist. Macht die Idee der umweltfreundlicheren Reparatur statt Neukauf etwas kaputt. Aber solange neue Joycons definitiv kaputtgehen würden, ist das Gulikit-Kit auf jeden Fall die bessere Alternative.
Aber eigentlich geht es ja um die unauffällig aussehenden Joysticks. Die mussten jetzt eingebaut werden.
Einbau
Der Einbau war nicht sehr schwierig, aber auch nicht supereinfach. Die Joycons haben Schrauben, die muss man lösen. Danach gehen sie auf, wobei die Schultertaste oben rausfallen kann. Das eigentliche Problem sind die Flachbandkabel, die einzelne Komponenten der Joycons verbinden. Die sind teils schwer zu lösen, friemelig wieder zu verbinden und sie können nur zu leicht reißen. Ich war froh, dass die Switchbesitzerin das alles selbst machen wollte.
Ich empfehle das Folgen eines Videos, z.B. diesem:
Bei uns sah die Montage in etwa so aus:















Dabei riss am Ende leider ein Kabel, das aber schon vorher einen Wackler hatte. Es wäre reparierbar, bis dahin kann der Joycon-Controller nicht mehr einzeln benutzt werden. Kein Riesenverlust.
Fazit: Funktioniert
Tatsächlich ist der neue Joystick eine riesige Verbesserung. Ich habe danach direkt eine Runde Fast RMX gespielt und wirklich reihenweise neue Bestzeiten gefahren. Was teilweise an der gewonnenen Erfahrung in Versus-Runden gelegen haben mag, doch die Steuerung des Fahrzeugs war einfach deutlich besser als zuvor. Aber ist ja auch klar, wenn man mit direkt vor der Reparatur vergleicht, wenn das Ding nicht mehr die ganze Zeit von alleine in die Wand fahren will. Doch hatte ich die vorherigen Rekorde aufgestellt als die Joycons recht neu waren und noch keinen wahrnehmbaren Drift hatten. Für mich ein Hinweis, dass die Gulikit-Joysticks besser funktionieren als die Originalteile, super belastbar ist diese Einschätzung aber nicht (dafür spielte ich mit beiden Varianten zu wenig).
Seitdem hat die Switchbesitzerin einiges selbst gespielt und ebenfalls keine Klage gehabt. Für sie funktioniert der Joycon jetzt eben, driftlos.
Ob wirklich der Energieverbrauchs des Joycons besser ist kann ich nicht messen, ich kann auch die Langzeithaltbarkeit nicht bewerten. Dass die Technik niemals driften solle, das stimmt wohl. Aber es kann ja sonstwas kaputt gehen. Und hätte ich es gemerkt, wenn das einfach nur ein neuer gewöhnlicher Joycon-Joystick gewesen wäre? Nein. Aber Gulikits andere Produkte mit dieser Technik wurden publikumswirksam besprochen, für solche Zweifel gibt es keinen Grund.
Ich finde es toll, endlich eine dauerhafte Lösung für das Joycon-Driftproblem zu haben.
Skyrim mit Mods unter Linux
Monday, 27. February 2023
Skyrim funktioniert mit Steams Proton unter Linux, das Spiel läuft sogar gut. Aber beim Modden ist fast die gesamte Dokumentation auf Windows ausgerichtet. So gibt es keinen nativ unter Linuxs laufenden Modmanager – abgesehen von modsquad, dessen Dokumentation mir aber ungenügend war. Doch das tolle: Es ist alles lösbar.

0. Die Erweiterungen kaufen
Das betrifft nur jene, die wie ich auch das originale Skyrim haben und nicht die neue Special Edition kaufen wollen. Das Problem ist: Das alte Spiel (auch Oldrim oder Skyrim LE genannt) ist samt seinen Erweiterungen von Bethesda im Steam-Shop versteckt worden. Und während die SE gerade reduziert war, blieb das Originalspiel und die DLCs sicher mit voller Absicht beim vollen Preis. Aber ohne die DLCs sind viele Mods nicht installierbar.
Als Lösung kaufe man die Skyrim Legendary Edition für Steam außerhalb von Steam. Auf CDKeys.com kostete sie ~7€ (kein Affiliate-Link, auch kannte ich die Seite vorher nicht). Ich hatte zuvor nur das Grundspiel, durch den Kauf wurden die Erweiterungen dem hinzugefügt.
Die alte Version hat Nachteile zur neuen: Sie sieht wohl (ohne Mods) schlechter aus und viele neue Mods werden nur noch für die SE veröffentlicht. Vorteil der LE sei die bessere Performance, zudem ist derzeit die Modauswahl für diese Version noch größer; Außerdem ist sie beim Kauf über CDKeys günstiger.
Wer SSE schon hat oder lieber damit spielen will sollte diesem Artikel trotzdem folgen können. Am Modden ändert sich nichts grundlegendes, eigentlich ist nur die Modauswahl etwas anders.
1. SKSE ist per Steam installierbar
SKSE ist fast unabdingbar. Die Software erweitert Skyrim um Skriptmöglichkeiten, die von einigen Mods gebraucht werden. Und da sind fundamentale dabei. SKSE kann dabei für das original Skyrim einfach per Steam installiert werden, per Shopseite. Spieler der SE laden es dagegen vom Nexus.
Wer die LE hat kann hier abbrechen. Oldrim hat einen Steam-Workshop mit einer gar nicht mal so geringen Auswahl. Zusammen mit SKSE lässt sich das Spiel jetzt schon deutlich verbessern. Wer aber Mods aus dem Nexus installieren will (oder muss, weil er auf die SE gesetzt hat) sollte weitermachen.
2. Mod Organizer 2 hat einen Linuxinstaller
Die Nexusmods lassen sich auch manuell installieren – dann werden die Texturen und .esps per Hand in den Data-Ordner von Skyrim geschoben. Aber das bricht natürlich irgendwann zusammen, vor allem wenn ein inkompatibler Mod wieder entfernt werden soll. Besser ist ein Modverwalter wie Mod Organizer 2.
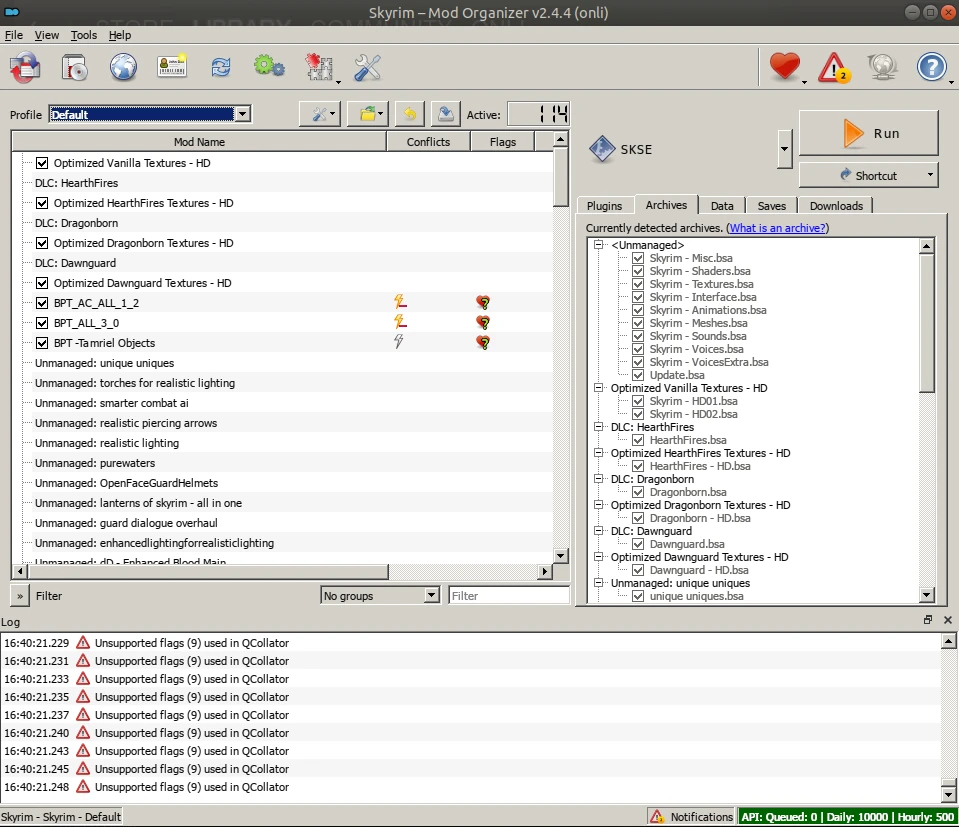
Und der lässt sich per diesem Repo unter Linux installieren. Die in der Readme beschriebenen Installationsschritte sind dabei nicht kompliziert:
- Das Spiel in Steam installieren.
- Den Installer des letzten stabilen Release herunterladen.
- Das heruntergeladene Archiv entpacken.
- Im Ordner
./install.shausführen. - Dem Installer folgen.
- Wenn danach in Steam Skyrim gestart wird, startet stattdessen der Mod Organizer 2. Neben der Modverwaltung dort kann von hier aus das Spiel selbst gestartet werden.
Die Installation forderte eine bestimmte Proton-Version, die in den Steam-Einstellungen von Skyrim gesetzt werden sollte. Bei mir war das Proton-6.3 und ich habe mich dran gehalten.
3. ENBoost (Teil von ENBseries) wird irgendwann gebraucht
Jetzt läuft Skyrim mit vollem Modsupport, was ich richtig nutzen wollte. Was anfangs gut lief kippte irgendwann: Das Spiel wurde instabil. An diesem Punkt war die einzige Lösung ENBseries. Auch wenn der obere ModOrganizer-Installer auf Github dagegen empfiehlt.
Die Installation von ENBseries ist wieder leicht, es wird nur durch eine vermurkste Webseite erschwert. Das Modprojekt Step erklärt es aber eigentlich ganz gut. Man geht über die News-Sektion der Webseite auf Download, klickt dann auf den Spielnamen und landet dadurch auf der Release-Seite. Die Versionsnummern ganz unten sind entgegen ihrer Darstellung klickbar. Auf der folgenden Seite ganz unten ist der Downloadlink.
Das heruntergeladene Archiv entpacken und manuell die d3d9*.dll-Dateien, enbhost.exe und enblocal.ini in den Skyrim-Ordner schieben.
Jetzt kann man wieder der Step-Seite folgen um ENBoost zu aktivieren. Ich werde dazu allerdings noch meine eigenen Konfigurationshinweise nachliefern.
Und auch wenn Step und das Crashfixplugin davor warnten muss ich zwischendurch in der enblocal.ini ExpandSystemMemoryX64=true setzen. Danach aber entfernte ich ein paar Texturenmods und ich konnte das wieder entfernen, tatsächlich lief Skyrim mit de Einstellung nicht super stabil (aber besser als vorher), es ist besser sie nicht zu brauchen.
Ich war übrigens sicher, dass ENBSeries unter Linux nicht laufen würde, zu oft hatte ich das früher gelesen. Aber früher ist da wohl das Stichwort. Tatsächlich läuft ENBSeries gut und Skyrim damit stabiler als vorher. Sogar Grafikerweiterungen scheinen zu funktionieren, wobei ich angesichts der Performancekosten damit nur ganz kurz experimentiert habe.
4. Das High Poly Project ist ein Performancekiller
Thema Performance: Es gibt im Nexus das High Poly Project. Objekte bekommen mehr Polygone, dadurch werden Rundungen erstmals wirklich rund. Doch zumindest unter Linux, oder unter Linux mit meiner Radeon RX 570, tut der Mod der Performance gar nicht gut.
Das war nicht unbedingt absehbar, weil der Autor keine Performanceprobleme beobachtete und es auch sonst in den Kommentaren keine direkt sichtbaren Warnungen gab. Also, Finger weg, oder sorgfältig testen.
5. Schatten können gut aussehen
Das größte Problem nach der Installation waren für mich auch gar nicht die Texturen oder fehlende Rundungen der Objekte, es waren total kantige Schatten. Ich musste erst nachlesen um zu glauben, dass Skyrim schon damals da so kaputt war, ich dachte das lag an Linux (und nehm es deswegen hier auf). Um die Schatten zu reparieren muss die .ini angepasst werden. Doch Vorsicht, die im Dateisystem platzierte wird durch den Mod Organizer 2 ignoriert. Stattdessen muss man den INI-Editor der Software nutzen.
Die wichtigste Einstellung war für mich in der skyrimprefs.ini: iShadowMapResultion=8192. Später reduzierte ich das auf 4096, zugunsten der Performance. Wieder ist Step hier hilfreich.
2023 Skyrim mit seinen vielen Mods zu spielen macht mir das Spiel wesentlich sympathischer. Denn meine Erinnerungen an meinen ersten Durchlauf vor einigen Jahren sind gemischt – das Spiel hat was, aber einiges störte mich auch, ich vermisste Morrowind. Einige der Schwachstellen sind durch Mods mittlerweile verbesserbar und Modden selbst ist ja auch ein interessantes Spiel. Dadurch läuft meine Zeit mit Skyrim diesmal deutlich besser.
Ich plane zwei Folgeartikel: Einmal möchte ich näher auf die verschiedenen Konfigurationsänderungen und Mods eingehen, die das Spiel mit vielen Mods unter Linux stabiler machen. Der zweite soll alle anderen Mods vorstellen, die mir diesmal das Spiel verbessern, als Update zu meinem Modartikel von 2016.
Samsung A3 (2016) auf Android 11/LineageOS 18.1 updaten
Monday, 30. January 2023
Das A3 (SM-A310F, oder: a3xelte) bekam von Samsung nur Android 7. Mit LineageOS als Custom Rom geht mehr, es wäre schade das kleine Telefon nicht damit zu versorgen.

Wer einfach nur die Anleitung haben will sollte unter Installation weiterlesen. Ich werde nämlich jetzt erstmal erklären, was ich von dem Gerät halte und wie meine Erfahrung mit dem Flashen war. Denn es lief diesmal nicht problemlos.
Kontext und Einschätzung
Es gibt mehrere verschiedene A3. Dieses "A3 (2016)" ist tatsächlich von Ende 2015 und ist damit nicht besonders neu. Bei sustaphones ist es gelistet, weil es früher offiziell von LineageOS 17.1 unterstützt wurde. Das ist leider vorbei, keines der größeren Projekte unterstützt das Telefon noch, die von mir installierte war eine inoffizielle Version. Vielleicht spielt da eine Rolle: Das Telefon war superzickig. Lief die erste Installation der TWRP-Recovery-Software noch durch, musste ich sie wiederholen (weil ich nicht schnell genug reagierte und Samsungs Androidversion sie beim Start löscht), was dann leider nicht mehr klappte. Daraufhin startete das Telefon nicht mehr, sondern blieb immer beim ersten Schritt im Bootvorgang mit dem "Galaxy A3[6]"-Logo hängen. Da der Odin-Download-Modus noch startete war das lösbar, aber nur mit einer speziellen Kombination aus einem Heimdall-Fork und einer älteren TWRP-Version, dazu unten mehr. Zwischendurch war ich sicher, das Gerät nur noch wegwerfen zu können.
Man sollte sich also gut fragen ob der Aufwand lohnt. Ich las zwar auch Berichte von Leuten, bei denen das A3 problemlos mit einer neuen Androidversion zu flashen war. Aber Fehlerberichte gibt es ebenfalls Unmengen. Und das alles wofür? Das A3 ist zwar hübsch klein, der Bildschirm und die Kamera wirkt auf dem ersten Blick nicht schlecht, der Speicher ist sogar erweiterbar. Aber der Prozessor ist langsamer als z.B. der des LG G5 aus der gleichen Zeit, der Lautsprecher ist schrottig, vor allem aber ist der Akku nicht einfach auswechselbar. Wenn man aber schon bei Telefonen mit nicht einfach auswechselbarem Akku ist, dann gibt es Unmengen an stärkeren Alternativen mit besserer Romversorgung (z.B. das OnePlus 7 Pro).
Doch andererseits: Das alte A3 wird ja eher deswegen gewählt, weil es schon da ist und nicht im Schrank versauern soll, es wird ja wohl nicht extra gekauft. Dann lohnt es sich in jedem Fall, die folgende Anleitung nachzuvollziehen.
Installation
Die Kurzfassung: Das A3 muss erst vorbereitet werden, dann wird mit Odin (Windows) oder Heimdall (Linux) TWRP als Recovery installiert, womit dann das Rom geflasht werden kann. Ich wählte hier LineageOS 18.1, es gibt aber im xda-Forum auch eine Alpha von LineageOS 20. Lokale Daten wie installierte Apps werden dabei gelöscht!
Ich nutze Linux, also ist auch die Anleitung auf Linux ausgerichtet. Für Windows habe ich aber jeweils dazugeschrieben wie es gehen sollte – üblicherweise sind solche Anleitungen für Windows (und der Windowssoftware Odin) geschrieben, daher findet man anderswo auch alles nochmal zum nachlesen. Statt Heimdall unter Linux ebenfalls Odin (mit Wine) zu benutzen wäre eine testenswerte Alternative, vor allem wenn man sich die Kompilierung des Heimdall-Forks sparen will.
0. PC vorbereiten
Auf dem PC sollte adb installiert sein, das liegt unter Linux in den Quellen, für Windows möge man dieser Anleitung folgen. Unter Windows könnten auch Samsungs USB-Treiber gebraucht werden.
1. Telefon vorbereiten
Zuerst alle Updates durchlaufen lassen, insbesondere die für das System selbst. Da gab es 2020 das letzte, das auf meinem Gerät z.B. noch fehlte.
Sicher nun die Daten auf dem Gerät, die du behalten willst, irgendwo extern.
Dann muss der Entwicklermodus aktiviert werden. In den Einstellungen auf "About Phone" und dort siebenmal auf den Eintrag "Build Number" drücken. Eine kleine Einblendung sollte die Aktion bestätigen.
Dadurch gibt es in den Einstellungen einen neuen Eintrag mit den Entwickleroptionen. Dort müssen zwei aktiviert werden:
- OEM Unlock
- USB Debugging
2. Linux: Heimdall installieren & Recovery installieren
Jetzt kann das A3 in den Downloadmodus gesetzt werden, indem zum Start gleichzeitig die Knöpfe Power + Home + Lautstärke runter gedrückt und gehalten werden.
Unter Linux könnte man nun mit Heimdall die Recovery-Software aufspielen. Doch leider ist Heimdall nicht ohne weiteres mit dem A3 kompatibel, die in den Quellen verfügbare Version wird nicht funktionieren. Stattdessen kompilieren wir diese Version selbst, die einen Workaround eingebaut hat. Dafür braucht es die Pakete git, build-essential und cmake sowie ein paar weitere, die auch der Readme entnommen werden können (zlib1g-dev, qt5-default, libusb-1.0-0-dev. libgl1-mesa-glx, libgl1-mesa-dev; Paketnamen können abweichen). Dann:
git clone https://github.com/changlinli/Heimdall cd Heimdall mkdir build cd build cmake -DCMAKE_BUILD_TYPE=Release .. make cd bin/
Als Test ziehen wir nun die PIT-Datei, mit der das Telefon später vielleicht gerettet werden könnte falls etwas schiefginge:
sudo ./heimdall print-pit --file a310f_orig.pit
Das Telefon sollte nun neustarten, mit der Tastenkombination direkt wieder in den Downloadmodus setzen.
Kommen wir zur Recovery. TWRP kann von der TWRP-Seite heruntergeladen werden. Allerdings funktionierte die derzeit aktuelle 3.7.0 bei mir nicht. Stattdessen sollte die twrp-3.4.0-0-a3xelte.img gewählt werden, die ging.
Mit dem Telefon im Download-Modus, verbunden mit dem PC via eines USB-Kabels, kann das frisch kompilierte Heimdall nun die Recovery installieren:
sudo ./heimdall flash --RECOVERY twrp-3.4.0-0-a3xelte.img --no-reboot
oder 2. Windows: Odin installieren & Recovery installieren
Ich habe die Installation unter Linux durchgeführt. Unter Windows würde man statt Heimdall Odin benutzen. Ich verweise auf netzwelts Android: So führt ihr ein Custom Recovery auf Samsung-Smartphones durch. Auch hier würde ich von TWRP die 3.4.0 installieren.
3. LineageOS flashen
TWRP ist frisch installiert, würde aber entfernt werden, wenn das Telefon regulär neustartet. Stattdessen beenden wir den Downloadmodus mit Power + Lautstärke runter und drücken und halten direkt die Kombination für den Recovery-Modus: Power + Home + Lautstärke hoch. Es startet TWRP.
Auf dem PC laden wir LineageOS 18.1 aus dem xda-Forum herunter.
In TWRP geht es zu Wipe -> Advanced Wipe, dort Cache, Data und System auswählen und wipen.
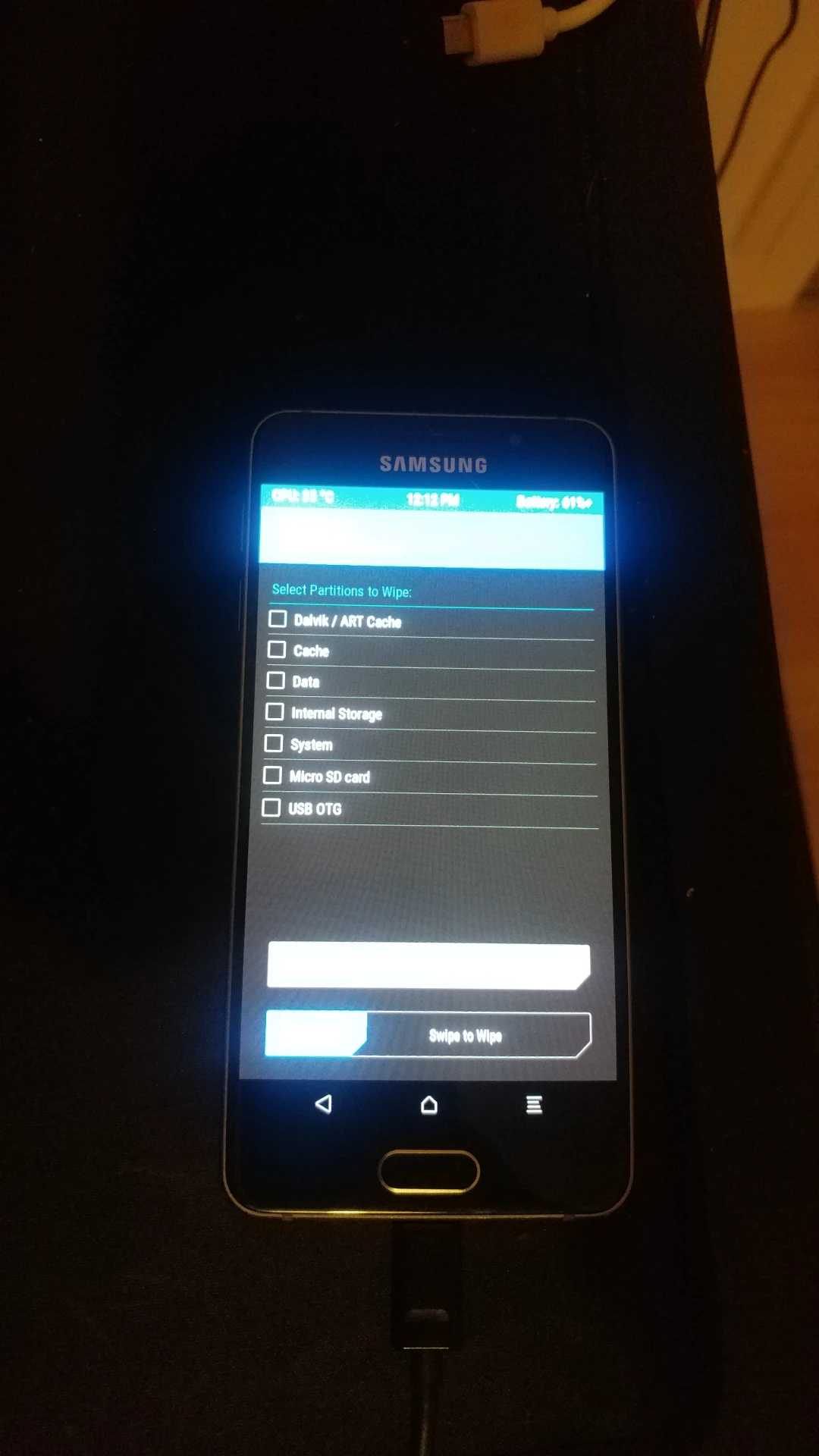
Dann zu Advanced -> Sideload, durch swipe bestätigen. Das gerade heruntergeladene zip kann nun installiert werden:
adb sideload lineage-18.1-20230118-UNOFFICIAL-a3xelte.zip
Wer mag installiert jetzt noch genauso die Open GApps (ARM64, Android 11), ich verzichtete.
Wenn TWRP eine TWRP-App installieren will sollte das verneint werden.
Jetzt neustarten und das A3 sollte direkt LineageOS laden.
Mit LineageOS soll das A3 komplett funktionieren. Ich testete den Lautsprecher, Anrufe und die Kamera, schien zu passen, auch der Akku hielt ordentlich.
Wer keine GApps installiert hat und das nicht gewöhnt ist, dem empfehle ich direkt F-Droid herunterzuladen. Von dort bezieht man dann Firefox (Fennec) mit Ublock und alles andere was man braucht, wenn es Apps aus dem Play Store sein müssen kann Aurora die installieren (nicht alle gehen dann auch ohne GApps, aber viele). Vielleicht ist ansonsten meine eigene App-Liste eine Orientierungshilfe.
Mein Ärger mit dem Kobo Glo HD
Monday, 23. January 2023
Mein Hauptproblem mit dem Kobo Glo HD – gekauft vor einigen Jahren nach dem Ableben des Kobo Touch – ist, dass er nicht zuverlässig ist. Er war es nie. Das fängt damit an, dass ich ihn desöfteren aufladen musste als ich eigentlich einen vollen Akku erwartete. Es kann sein, dass das einfach ein Konzeptproblem ist, der Leser sich nicht komplett abschaltet damit ein Öffnen der Hülle ihn aktivieren kann und er dabei mehr verbraucht als ich erwartete, aber so oder so überraschte mich das mehrmals negativ.
Dann das Wlan: Eben verband er sich, vorher ging das mehrmals nicht. Aber es ist auch nicht so, dass die Wlan-Verbindung irgendwas brächte – nur ein Netzwerkfehler begrüßt mich bei der Entdeckenfunktion, genauso funktioniert die Synchronisation (die auch Geräteupdates finden sollte) einfach nicht. Das ist auch deswegen bemerkenswert, weil ich das Gerät vor nicht allzulanger Zeit sich habe updaten lassen. Im August war das wohl (da war laut Anzeige die letzte Synchronisation), völlig veraltet ist die Software also nicht. Und ja, der Leser wird nicht mehr verkauft, aber dass die Serverinfrastruktur abgeschaltet wurde lese ich nirgends. Wäre auch überraschend, dürfte die Anbindung an den Büchershop doch die Haupteinnahmequelle Rakutens Kobo-Sparte sein.
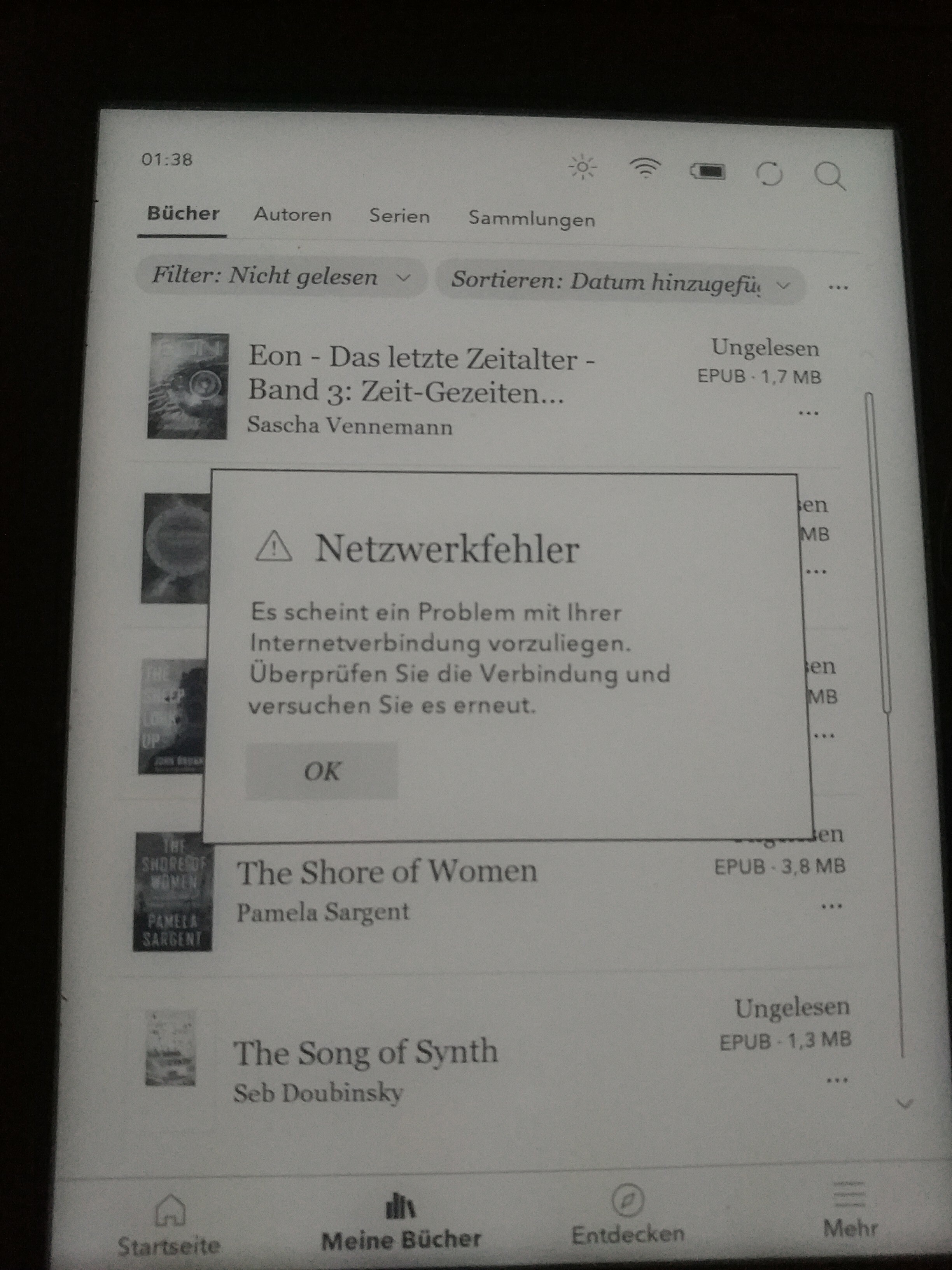
Gut, so schlimm ist dieser Fehler für mich nicht, da ich nie besonders am Kobo-Shop mit seinen DRM-verseuchten Büchern interessiert war. Den Kobo habe ich ja gerade deswegen gewählt, weil er (wie schon sein Vorgänger) sich wie ein USB-Stick mit dem PC verbinden kann und dann durch Rüberkopieren regulärer .epubs einfach zu befüllen ist. Aber immer wieder funktioniert das nicht. Manchmal kann er gar nicht eingehangen werden, andermal erscheint nach dem Abhängen und nach dem Importvorgang das herüberkopierte Buch einfach nicht in der Oberfläche. Stattdessen zeigt mir dmesg auf meinem Rechner solche Fehlermeldungen:
[ 178.944701] device offline error, dev sdc, sector 527 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 2 [ 178.944707] Buffer I/O error on dev sdc, logical block 527, async page read [ 178.945458] udevd[13079]: inotify_add_watch(7, /dev/sdc, 10) failed: No such file or directory [ 178.960589] sd 4:0:0:0: [sdc] Synchronizing SCSI cache [ 178.960620] sd 4:0:0:0: [sdc] Synchronize Cache(10) failed: Result: hostbyte=0x01 driverbyte=DRIVER_OK [ 180.858826] usb usb3-port2: attempt power cycle [ 182.705765] usb usb3-port2: unable to enumerate USB device
Die sind höchst bedenklich. Nach einigen Wiederholungen funktionierte der Büchertransfer bisher immer doch, aber komfortabel ist anders. Das Befüllen über eine Netzwerkfreigabe scheint als Alternative nicht zu existieren (selbst wenn das Wlan funktionieren würde). Ich habe nie wirklich verstanden wie die Kobo-Softwarewelt eigentlich funktionieren soll (gibt es da einen Online-Account, dem ich woanders gekaufte Bücher auch hinzufügen könnte?), musste das über die USB-Laufwerksfunktion aber auch nicht. Wenn die aber nun nicht mehr ordentlich funktioniert wird die Kombination dieser beider Fakten zu einem Problem.
Wenn der erste Kobo komplett stabil gewesen wäre würde ich einfach an ein defektes Gerät glauben. Aber auch der Vorgänger hatte ähnliche Probleme, wollte sich manchmal nicht mit dem PC verbinden, brauchte gelegentlich sogar ein Komplett-Reset. Stabile Hardware sind meine beiden Kobos einfach nie gewesen.
Das finde ich derzeit ein bisschen trauriger als sonst, weil ich gerade viel Spaß damit hatte eine Science-Fiction-Buchreihe durchzulesen und dabei bemerkt habe, dass es mittlerweile DRM-freie .epubs im regulären Onlinehandel gibt. Nachdem die Humblebundles mich vergrault haben wäre anderswo Bücher zu kaufen daher vielleicht eine Option gewesen. Zudem bietet die lokale Bücherei auch ebooks zum Ausleihen an und ihre neue Webseite sieht sogar halbwegs benutzbar aus. Aber ob ich das mit einem so unzuverlässigem Gerät machen will weiß ich nicht, wahrscheinlich höchstens bei der nächsten längeren Reise.
Ansonsten ist der Kobo Glo HD übrigens bisher kein schlechtes Gerät gewesen. Ich mag die eingebaute Hintergrundbeleuchtung und das Gerät ist zwar nicht schnell, aber beim Umblättern schnell genug. Beim Verkleinern und Vergrößern von Text ist er unangenehm langsam, aber das macht man ja pro Buch meist nur einmal. Keinen Knopf zum Umblättern zu haben hat mich schon beim ersten Kobo nicht gestört. Texte sehen auf dem Bildschirm gut aus, die mitgelieferten Fonts sind hübsch. Ein ordentliches Wörterbuch fehlte allerdings, das eingebaute hat mir nie helfen können, aber gut, meist hat man ja doch ein Telefon mit Suchmaschine zur Hand.
Insgesamt habe ich mit diesem Leser über die Jahre einige Bücher gelesen, ein kompletter Fehlkauf war er nicht. Aber wenn er ganz kaputt geht wird angesichts der oben beschriebenen Probleme der Nachfolger nur bei völliger Alternativlosigkeit wieder ein Kobo.
Verbesserungen für sustaphones: Ankerlinks, Design, Romauswahl
Wednesday, 18. January 2023
Sustaphones, meine Webseite zum Finden reparierbarer und von Android-Roms unterstützten Telefonen, hat ein paar Updates bekommen.
Diese beiden Screenshots zeigen den Unterschied (die alte Version zuerst):
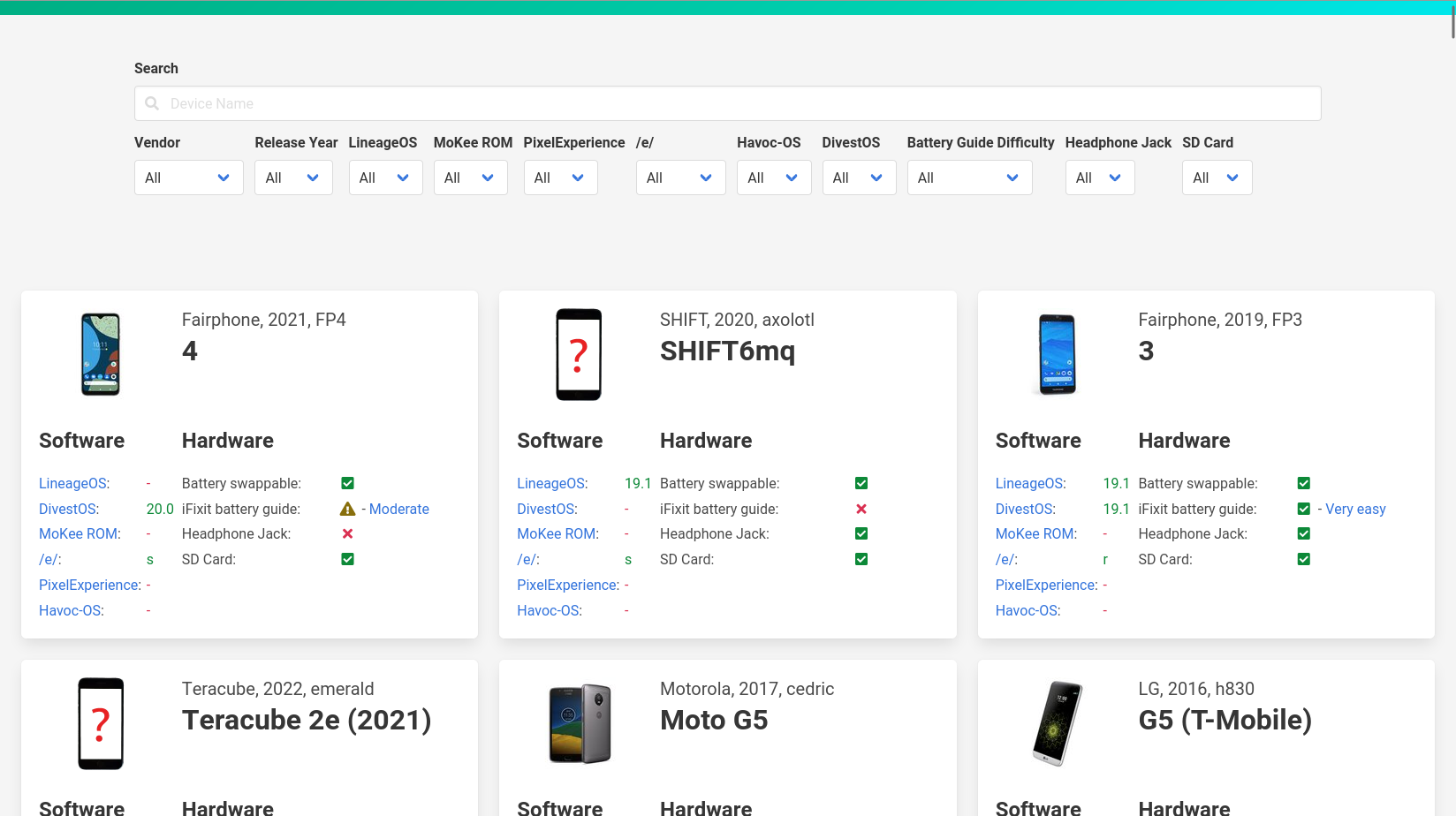
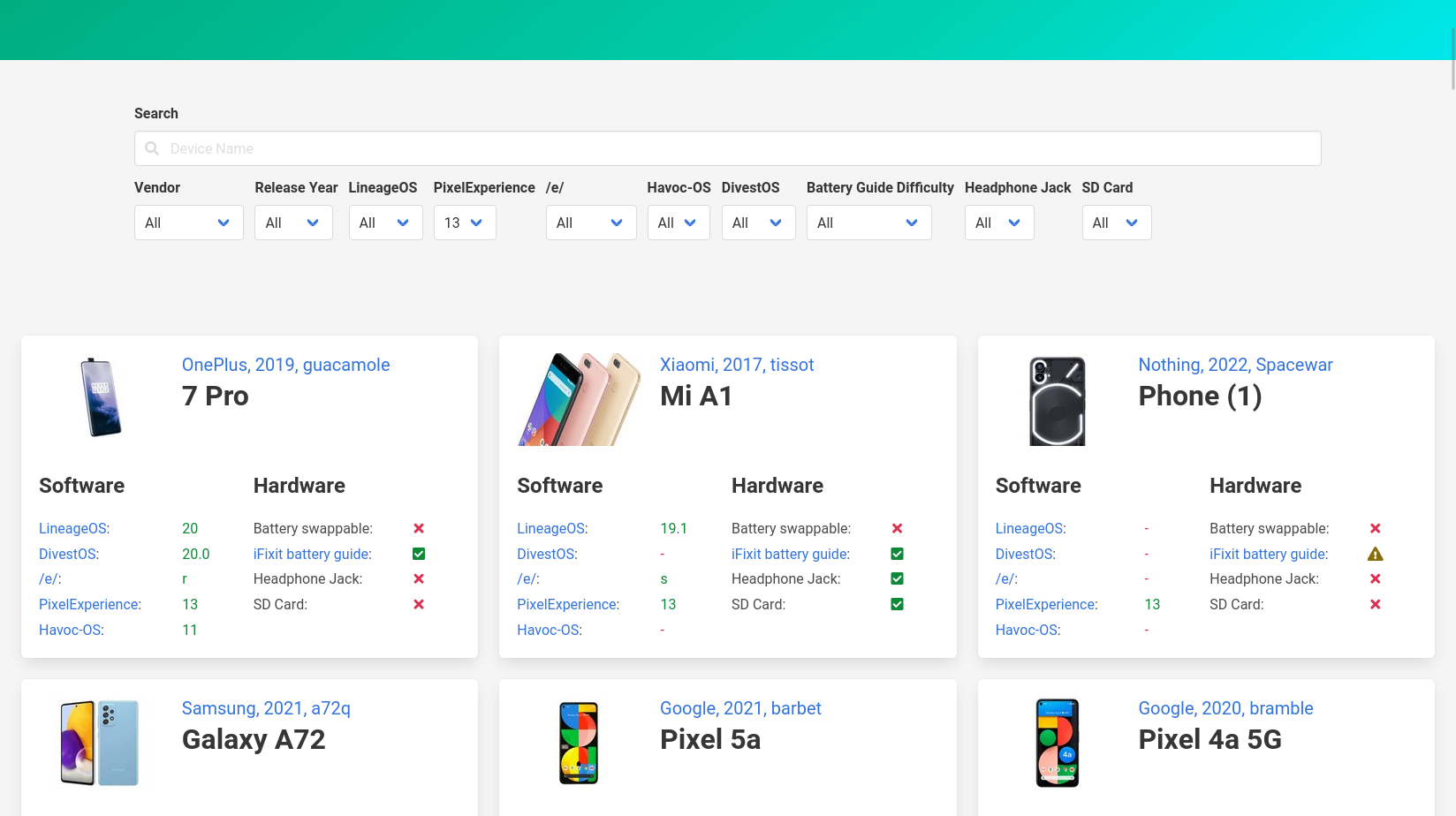
Kein großer Umbau, aber praktische Änderungen sind dabei:
- Die einzelnen Boxen haben nun oben einen Ankerlink, der die Seite an die jeweilige Stelle scrollt. Anlass dazu war dieser gnulinux.ch-Artikel zum Fairphone 2, der seine Erkenntnisse über ein spezielles Telefon nicht verlinken konnte. Jetzt ginge das.
- Um das Design etwas symmetrischer zu machen ist der Link zur iFixit-Akkuwechselanleitung nach vorne in das Label gerutscht und steht nicht mehr extra hinter dem Icon. Dadurch konnten die Software- und Hardwarebereiche in der Box gleich groß werden. Das trennt gleichzeitig den unteren Bereich visuell besser vom oberen Bereich ab, bei dem Bild und Titel immer noch 33% und 66% des Platzes einnehmen.
- MoKee gibt es nicht mehr, dementsprechend wurde es aus der Liste genommen.
- Da LineageOS so betont hat, dass die neue Version 20 und nicht 20.0 sei, habe ich auch bei den anderen Roms die Versionsnummern angepasst (zumindest wo das jeweilige Projekt sie nicht eindeutig als X.0 benennt, wie bei DivestOS).
- Generell lief ein Update aller Parser, insbesondere bei PixelExperience war das überfällig. Darüber wurden auch ein paar neue Telefone hinzugefügt, wie das Nothing Phone(1).
Ich möchte noch erwähnen, dass Havoc-OS auf meiner Abschussliste steht, dem Changelog zufolge ist das Projekt ziemlich inaktiv und auch bei ihrer Geräteliste hat sich nichts getan. Aber das werde ich noch etwas beobachten.
Änderungswünsche (die per Gitlab auch selbständig umgesetzt werden könnten) sind gern gesehen, ebenso Vorschläge zum Einbinden anderer Android-Projekte.
Zur Verteidigung von LibreWolf
Wednesday, 2. November 2022
Sören kritisiert in seinem Blog LibreWolf, eine dieser alternativen Firefoxkonfigurationen. Er hat nicht völlig unrecht mit seiner Kritik, ich möchte aber zweien seiner Argumente dagegenhalten.

Das fehlende Projektimpressum
Sören schreibt:
Nun wirbt also ein Projekt um Vertrauen, welches nicht einmal ein Impressum auf der eigenen Website hat. Die Argumentation, dass im Land des Betreibers ggfs. keine gesetzliche Impressumspflicht besteht, könnte zu kurz greifen, da hier ein Produkt auch innerhalb der Europäischen Union angeboten wird. Letztlich schafft es aber auch vollkommen unabhängig von der rechtlichen Perspektive nicht unbedingt Vertrauen, wenn darauf verzichtet wird. Denn auch wenn es sich hier um ein Community-Projekt handelt, so muss es am Ende des Tages eine Person geben, welche gesamtverantwortlich für den Browser sowie Inhalte der Website ist.
Er verkennt hier in welcher Softwarewelt wir uns bewegen. Jeder von uns benutzt täglich Software, dessen Autor wir nicht kennen. Ist das tatsächlich mal anders, benutzen trotzdem die Entwickler der Software Abhängigkeiten deren Autor sie nicht kennen. Die FOSS-Welt ist auf eine andere Basis aufgestellt als die einer Internet-Impressumspflicht, einer rein deutschen Erfindung deutscher Weltregulierungsbürokraten. Schon bei Webseiten ist diese lächerlich, bei FOSS-Softwareprojekten völlig unbekannt. Klar, viele große Softwareprojekte lassen sich einzelnen Firmen oder speziell für sie gegründeten Vereinigungen zuordnen, die Regel ist das aber nicht.
Dementsprechend ist es keinesfalls so, dass für Browser oder Webseite des Projekts eine einzelne Person gesamtverantwortlich sein muss. Selbst wenn gewisse Juristen und Politiker das gerne so hätten.
Nebenbei, eine gesetzliche Impressumspflicht für solch eine private Hobbyseite besteht auch in Deutschland nicht. Edit: Diese meine Auffassung wird in den Kommentaren von fachkundiger Seite allerdings bestritten. Ich bleibe dabei, dass ein Projekt an solchen juristisch-bürokratischen Maßstäben zu messen keine gewinnende Strategie ist.
Das harmlose DRM
Sören schreibt:
Interessant ist auch die Begründung, mit der LibreWolf standardmäßig Digital Rights Management (DRM) abgeschaltet hat: Dies sei eine Limitierung der Nutzer-Freiheit. Das ist natürlich völliger Quatsch, denn im Gegenteil erlaubt DRM dem Nutzer den Konsum von Filmen, Serien und Sportveranstaltungen, sowohl kostenlos als auch kostenpflichtig, die anders überhaupt nicht angeboten werden könnten und was für den Nutzer auch überhaupt keinen Nachteil besitzt, während es das LibreWolf-Projekt ist, welches sich hier eine standardmäßige Einschränkung seiner Nutzer anmaßt – wohlgemerkt während gleichzeitig groß mit Freiheit geworben wird.
Die Aktivierung von DRM (Digital Restriction Management) in Browsern wie Firefox ist keinesfalls ohne Nachteile für die Nutzer, denn es propagiert die Nutzung dieser Technologie. Mit DRM aber kontrollieren Firmen, was die Menschen mit ihren Rechnern machen können. Dann werden Bücher aus der Ferne gelöscht, das Abspielen auf dem gewünschten Anzeigegerät verboten, das Anfertigen von Screenshots für Kritiken verhindert, das völlig legale Verleihen unterbunden; Kurz: Jedwede nicht komplett vorgesehene Nutzung der Inhalte wird verhindert. Als Firefox damals DRM aktivierte war es eine Niederlage für die Freiheitsrechte von uns allen, es in einem relevanten Browser nicht aktivieren zu können wirkte vorher gegen die weitere Verbreitung.
Natürlich kann jeder für sich abwägen, ob in einem bestimmten Kontext wie z.B. für Netflix das DRM nicht doch akzeptabel ist. Aber das sollte definitiv ein Opt-In und nicht standardmäßig an sein und ist wie ausgeführt nicht grundsätzlich eine nachteilslose Geschichte.
Das waren nur die zwei Argumente, die bei mir den größten Widerspruch provozierten. Mit den anderen Argumenten haben ich weniger Probleme, aber die Gesamtkritik findet mein Gefallen nicht.
Denn ich denke zwar insgesamt auch, dass ein Projekt wie LibreWolf natürlich Nachteile hat. Gerade Updates etwas später zu erhalten ist nicht ideal. Dazu laufen solche Projekte tatsächlich in die Gefahr, Sachen zu deaktivieren, die im Großen und Ganzen positiv sind. In diese Richtung geht der Großteil Sörens Kritik. Aber sie ist mir zu negativ, zu einseitig, das Projekt wegen seiner vermeintlichen Gefährlichkeit sogar nicht zu Verlinken empfinde ich als überzogen und wirkt auf mich kindisch. Denn erstmal ist es doch eine gute Sache, wenn alternative Konfigurationen von Firefox ausprobiert werden, wenn es ein Korrektiv für Mozillas teils eben durchaus fragwürdige Entscheidungen gibt.
Das ist immerhin die Firma, die bei der Überarbeitung der Androidversion Erweiterungen unter großem Protest deaktivierte und forkverhindernd ihre rasche Wiedereinführung versprach, was mittlerweile jahrelanges Verschleppen als Lüge entlarvt hat und nichtmal den eigenen Entwicklern erklärt wird. Besonders bei einem solchen Akteur ist Diversität eine Stärke, so ist auch LibreWolfs Existenz zu begrüßen. Ich vermute daher auch, dass die heftige Kritik weniger gegen das Projekt geht als gegen das durch das Projekt durchscheinende negative Bild von Mozilla – ob dem Autor das jetzt bewusst ist oder nicht.
Hacktoberfest 2022 und meine vier Paketupdates für Void Linux
Monday, 10. October 2022
Das Hacktoberfest belohnt Beiträge zu FOSS-Projekten, Ausrichter ist der US-Hoster Digitalocean. Void Linux macht dabei mit und ich empfand deren Beschreibung als sehr einladend: Die Ziele sinnvoll, klarer Einstiegspunkt und alle wichtigen Informationen wurden verlinkt. Wie war es dann, vier verwaiste Pakete für alle Void-Nutzer zu aktualisieren?
Das Prinzip

Das Hacktoberfest funktioniert so: Man meldet sich auf der Webseite an und gibt Leserechte auf den Github/Gitlab-Account. Projekte müssen über ihre Projektbeschreibung ihre Teilnahme signalisieren. Kommen dann im Projektzeitraum vier Pull-Requests an, bekommt der Teilnehmer ein T-Shirt oder es wird in seinem Namen ein Baum gepflanzt (beschränkt auf die 40.000 schnellsten erfolgreichen Teilnehmer). Der Fortschritt wird auf der Webseite in einer Übersicht angezeigt.
Void Linux hat auf seiner Webseite eine News veröffentlicht und da klar beschrieben, was sie brauchen:
- Updates für verwaiste Pakete, und zwar lieber als Rezepte für neue Pakete
- Upstream-Patches für Pakete, die nicht auf allen unterstützten Plattformen kompilieren
- Fixes für ihre eigene Infrastruktur
- Erweiterung der Dokumentation
Sie wollen also die Aktion nutzen um die anfallende Arbeit zu erleichtern, das fand ich super. Updates für verwaiste Pakete einzubringen sei zudem recht simpel.
Darüber kann man streiten, aber die Dokumentation dazu half auf jeden Fall. Zuerst gibt es eine Updateliste, die dort gelisteten Updates für Pakete von orphan@voidlinux.org sind die Ziele. Dann gibt es die Dokumentation, die etwas verteilt alles weitere erklärt: Das Readme des Paketrepos, die Anleitung und besonders hilfreich die Contributing-Hinweise.
Das Grundprinzip erklärt am besten die Readme: Klone das Git-Repo, führe darin ./xbps-src binary-bootstrap aus um Voids Paketinfrastruktur zu bauen. Aber wer Änderungen einbringen will liest sich besser durch Contributing, das erklärt neben dem Git-Drumherum das Vorgehen für Paketupdates: Editiere die Rezeptdatei ./srcpkgs/Paketname/template des Pakets (was oft einfach nur eine Anhebung der Versionsnummer sein wird), aktualisiere die Prüfsumme mit xgensum -i Paketname, baue das Paket mit ./xbps-src pkg <package_name>, dann installiere es mit xbps-install --repository hostdir/binpkgs <package_name>. Testen und einen PR mit einem einzelnem Commit an void senden. Das mit dem einen Commit wird oft bedeuten mit git rebase Commits zusammenzufügen, vor allem wenn nachträgliche Änderungen gefordert werden (was bei mir passierte).
Bei ihrem Github sind automatisierte Tests eingerichtet, die einen Syntaxcheck über die Rezeptdatei laufen lassen und zudem schauen, ob das Paket wirklich gebaut werden kann. Die sollten durchlaufen, ansonsten am besten direkt reagieren und den Fehler korrigieren.
Das musste ich teils auch bei meinen folgenden Paketupdates machen.
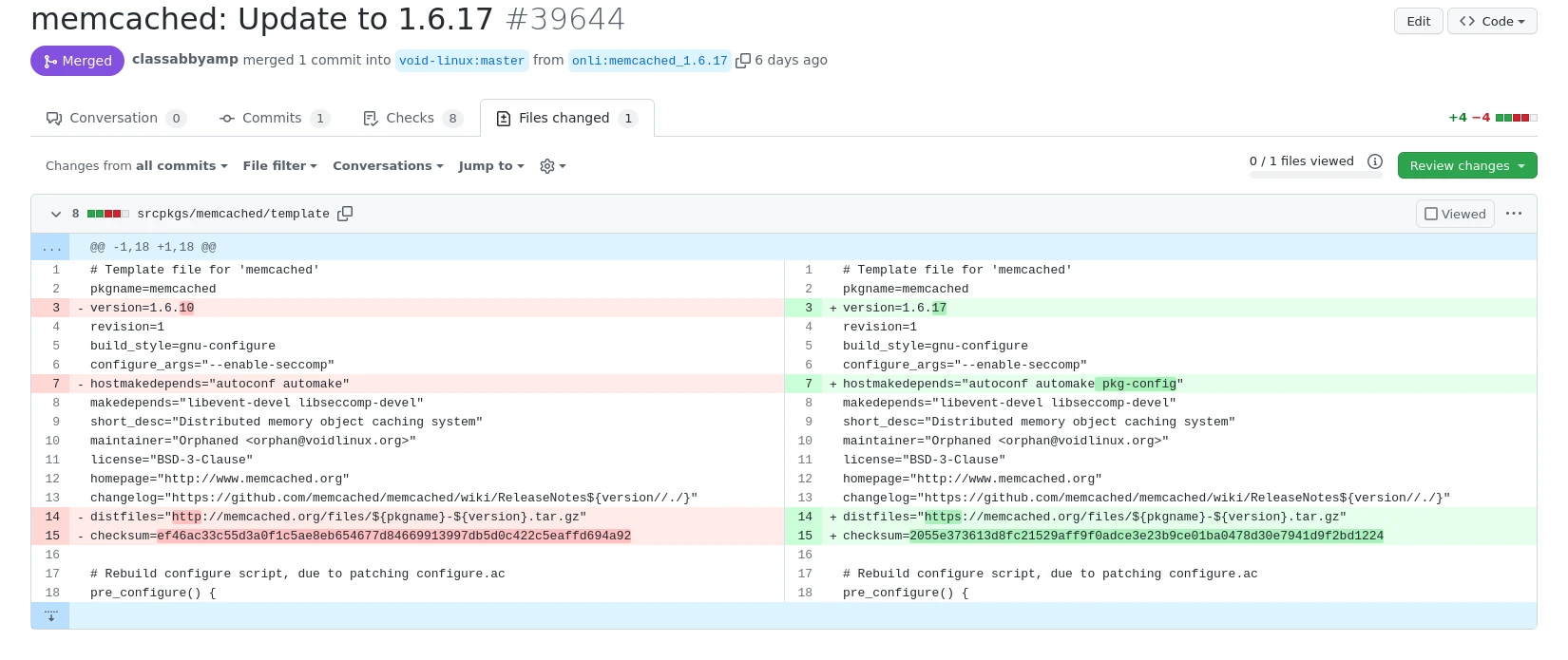
Update 1: memcached 1.6.10 -> 1.6.17
Memchached ist nicht Memcache, trotzdem fiel mit der Name wegen seiner Webentwicklerrelevanz auf. Das Update war nicht ganz so einfach: Erst wollte das Paket nicht bauen, dann wusste ich nicht wie ich es testen könnte.
Ich setzte also die Versionsnummer auf 1.6.17 und der Paketbau warf einen Fehler:
configure.ac:65: error: possibly undefined macro: AS_IF
If this token and others are legitimate, please use m4_pattern_allow.
See the Autoconf documentation.
Zum Glück war dafür ein Fehlerbericht bereits im memchached-Github, pkg-config würde gebraucht. Das zum Template hinzugefügt und der Bau lief durch. Hier als Beispiel ein Sreenshot der Änderungsübersicht, damit deutlich wird um wie wenige Codezeilen es letzten Endes geht:
Aber wie testet man memcached ohne herumliegenden Programmcode? Mit echo und nc ist die Antwort, wobei ich bei mir echo -e schreiben musste.
Daraufhin ging der PR durch.
Update 2: ruby-mime-types 3.3 -> 3.4.1
Eigentlich wollte ich ruby-httparty aktualisieren, aber das stolperte über diese Abhängigkeit. Das Gem mime-types war zu alt, um mit einer aktuellen Ruby-Version zu funktionieren. Ich musste da an mein altes Projekt music-streamer denken, das die MIME-Daten ausgelesen hat, wobei ich damals ruby-filemagic benutzte.
Hier war nur die Frage wie das Gem getestet werden kann, denn der Bau der neuen Version lief direkt durch. Die Antwort war irb, der Testcode entstammt der Projektreadme:
require 'mime/types' MIME::Types['text/plain']
Im PR kam dann nur der Vorschlag, die Changelog-Datei zu verlinken.
Update 3: ruby-mime-types-data 3.2019.1009 -> 3.2022.0105
Ich fand es naheliegend, ruby-mime-types-data direkt mitzuaktualisieren. So ein Datenpaket sollte keine Abhängigkeiten haben und ist daher einfach, aber es vermeidet im Zweifel Bugs in anderen Paketen wenn die Datenbank aktuell ist. Der Test war genau wie bei ruby-mime-types (das dieses Paket als Datenquelle lädt), nur dass beide neue Versionen installiert waren.
Im PR lief ich nur in ein Miniproblem mit einem Leerzeichen nach der Versionsnummer, was xlint nicht mochte. Das konnte ich mit commit -v --amend und einem folgendem git push --force reparieren, ohne rebase, wobei ich beim ersten mal vergessen hatte meine Änderung vorher auch mit git add sichtbar zu machen.
Update 4: minitube 3.9.1 -> 3.9.3
Ich hatte mir vor einer Weile mal einige Linux-Youtubeclients angeschaut, da fiel mir minitube direkt auf. Dem Versionsummersprung entsprechend war es ein kleines Update und lief problemlos durch, ich testete hier auch wieder die ARM-Crosskompilierung, was bei Void mit ./xbps-src -a armv6l pkg minitube einfach anzuleiern ist.
Funktionstest bei so einem Anwenderprogramm war dann viel einfacher als bei memcached, ich startete das Programm und schaute ob Videos abgespielt werden konnten.
Das wurde dann dieser PR.
Ein paar Gedanken zum Schluss: Das Hacktoberfest gefiel mir gut. Die früheren Probleme scheinen ausgeräumt. Natürlich wäre es noch cooler jemanden neu zur FOSS-Welt zur Teilnahme zu bringen, aber auch ich empfand den vom Void-Projekt bereitgestellten klaren Einstiegspunkt hilfreich. Manchmal ist ein klares "Wir wollen wirklich Hilfe, und zwar genau diese" sehr überzeugend.
Aber ohne mich zu sehr beweihräuchern zu wollen: Mir hat das auch nochmal vor Augen geführt, wie groß die Hürde eigentlich ist. Git mit seinen Konzepten ist schon nicht simpel, wenn dann noch rebase und Force-Push dazukommen wird es nicht einfacher. Ich erinnere mich zum Beispiel, dass mir sehr lange schlicht nicht klar war wie man PRs überhaupt aktualisieren kann, als ich git schon längst für meine eigene Versionsverwaltung nutzte. Jetzt scheint es simpel, damals fehlte mir einfach das mentale Modell dafür. Davon abgesehen, das Prüfen durch andere Entwickler machte mich anfangs nervös, alternativ genervt, wenn PRs ignoriert wurden (letzteres gilt immer noch, trifft mittlerweile aber weniger hart und bei Serendipity habe ich Vermeidungsstrategien entwickelt). Und das ist eine Hürde, die fast jede Code-Beisteuerung nehmen muss. Selbst man nicht direkt Linux-Paketmaintainer spielen will. Projekte tun gut daran möglichst viel davon zu dokumentieren, selbst wenn es redundant wirkt, einen ganzen Monat für diese Aktion zu geben ist ebenfalls angemessen.
Wie schwer bei Void das Aktualisieren von Paketen dann wirklich war hing natürlich stark vom Paket und vom jeweiligen Updatefehler ab. Ich wäre zum Beispiel ohne den existierenden Fehlerbericht über die nichtssagende Fehlermeldung bei memcached nie auf pkg-config als fehlende Abhängigkeit gekommen, und das obwohl ich pkg-config schon selbst bei simdock eingesetzt habe. Wer kein Ruby-Entwickler ist könnte das Testen vom Ruby-Gems schwierig finden. Überhaupt, dass man beim Kompilieren Fehlermeldungen wirklich lesen und interpretieren kann hat mir vor vielen Jahren Unki auf UbuntuUsers.de erst erklären müssen. Es baut alles aufeinander auf…
Der Blickwinkel macht für mich dann das Hacktoberfest nochmal wertvoller – wenn es bei einigen der Teilnehmern ein paar der benötigten Grundlagen schafft, ist das einfach eine gute Sache. Man kann es auf zwei Ebenen zwar auch kritisieren: Der Gamification-Ansatz ist manipulierend, via den T-shirts extrinsische Motivation einzuführen könnte intrinsische zerstören. Aber ich glaube, der Anreiz an Projekte die Unterstützbarkeit klar zu beschreiben wiegt das auf, und ein kleiner Motivationsanschub durch eine Aktion im Jahr dürfte auch langfristig wenig schädlich sein.
Mehr FPS für lau unter Linux: Proton, FSR und vkBasalt
Monday, 19. September 2022
Wer die technische Entwicklung bei Spielen nicht genau verfolgt könnte es verpasst haben, doch tatsächlich sind die Upscale-Techniken von AMD, Nvidia und jetzt Intel revolutionär. Mit ihnen laufen Spiele intern auf einer kleineren Auflösung – also z.B. 1477x831 – und die Grafikkarte skaliert das Bild dann eigenständig auf die Zielauflösung hoch – hier 1920x1080. Und die Ergebnisse sehen toll aus. Ursprünglich wurde dieser Ansatz als Lösung präsentiert um 4K-Auflösungen erreichbarer zu machen, doch mir ist das obere Szenario viel sympathischer. Denn so werden alte Grafikkarten entlastet, die dann auf einmal moderne AAA-Spiele besser bewältigen können. Das Hochskalieren mittels der GPU ist praktisch kostenlos, das Herunterregeln der internen Auflösung spart Unmengen an Aufwand.
Damit das perfekt läuft muss das Spiel diese Techniken unterstützen. Doch unter Linux haben sich Entwickler auf das freie FSR gestürzt, das Upscaling von AMD. Dessen erste Version lässt sich an jedes Spiel anheften! Die Ergebnisse sind teilweise erstaunlich gut, zumindest wenn man etwas nachhilft. Und da kommt vkBasalt ins Spiel.
In Kurz
Installiere Proton-GE und vkBasalt sowie optional Mangohud. Benutze für vkBasalt diese Konfiguration. Starte ein Windowsspiel so:
mangohud ENABLE_VKBASALT=1 WINE_FULLSCREEN_FSR=1 WINE_FULLSCREEN_FSR_MODE=ultra %command%
Setze die Auflösung im Spiel auf die FSR-Startauflösung für die native Zielauflösung deines Monitors (Tabelle hier). Fertig, das Spiel läuft schneller als zuvor.
Die ausführliche Anleitung folgt.
FSR aktivieren
Doch erstmal muss man FSR überhaupt ankriegen. Auf dem Steamdeck hat Valve das mitgeliefert, im regulären Proton nicht. Dafür braucht es bisher noch eine alternative Protonvariante, nämlich GloriousEggrolls Proton. Die Installation ginge so:
- Download a release from the Releases page.
- Create a ~/.steam/root/compatibilitytools.d directory if it does not exist.
- Extract the release tarball into ~/.steam/root/compatibilitytools.d/.
- tar -xf GE-ProtonVERSION.tar.gz -C ~/.steam/root/compatibilitytools.d/
- Restart Steam.
- Enable proton-ge-custom.
Doch ist das unnötig kompliziert, wenn ProtonUp-Qt das mit ein paar Klicks machen kann. Also: Zieh dir das AppImage davon, mach es ausführbar, lass es Proton-GE installieren.
Danach kann das in den Einstellungen von Steam unter Steam Play für alle Spiele aktiviert werden, oder du setzt die Protonversion für das jeweilige Spiel unter "Kompatiblität".
Um jetzt ein Spiel mit FSR zu starten müssen die Startparameter gesetzt werden. Rechtsklick in Steam aufs Spiel, Eigenschaften, dann sind die Startoptionen direkt rechts. Schreibe dort:
WINE_FULLSCREEN_FSR=1 WINE_FULLSCREEN_FSR_MODE=ultra %command%
Wenn jetzt das Spiel gestartet wird läuft alles normal, FSR tut noch nichts. Dafür muss erst die Auflösung gewechselt werden. Durch den Start samt FSR-Befehl sollte in den Einstellungen jetzt eine passende auftauchen. Bei meiner 1080p-Auflösung als Ziel ist das 1477x831, bei 1440p oder 4K als Ziel entsprechend mehr. Die beste Liste dafür findet sich hier. Wird jetzt diese Auflösung gewählt greift FSR. Das Bild sieht etwas ausgewaschener aus, aber viel besser als wenn die Auflösung nicht automagisch hochskaliert werden würde.
vkBasalt aktivieren
Diesem ausgewaschenem Bild kann vkBasalt auf die Sprünge helfen. Das Programm zeichnet Filter über die Ausgabe von Programmen. Besonders interessant für uns, dass es das Bild mittels zweier Methoden nachschärfen kann, und dass es nochmal zwei Kantenglättungsfilter kennt.
vkBasalt kann manuell installiert werden, das ginge so:
git clone https://github.com/DadSchoorse/vkBasalt.git cd vkBasalt meson --buildtype=release --prefix=/usr builddir ninja -C builddir install
Wieder sollte das nicht nötig sein, es ist in einigen Repos bereits vertreten und kann daher direkt über den Paketmanager installiert werden. Bei mir mit Void Linux:
sudo xbps-install vkBasalt
Die Konfiguration fehlt aber noch. Geht auch per Spiel, was in der Readme erklärt wird, ich würde stattdessen die Datei $HOME/.config/vkBasalt/vkBasalt.conf anlegen und hiermit füllen:
#effects is a colon seperated list of effect to use #e.g.: effects = fxaa:cas #effects will be run in order from left to right #one effect can be run multiple times e.g. smaa:smaa:cas #cas - Contrast Adaptive Sharpening #dls - Denoised Luma Sharpening #fxaa - Fast Approximate Anti-Aliasing #smaa - Enhanced Subpixel Morphological Antialiasing #lut - Color LookUp Table effects = smaa:dls reshadeTexturePath = "/path/to/reshade-shaders/Textures" reshadeIncludePath = "/path/to/reshade-shaders/Shaders" depthCapture = off #toggleKey toggles the effects on/off toggleKey = Home #enableOnLaunch sets if the effects are emabled when started enableOnLaunch = True #casSharpness specifies the amount of sharpning in the CAS shader. #0.0 less sharp, less artefacts, but not off #1.0 maximum sharp more artefacts #Everything in between is possible #negative values sharpen even less, up to -1.0 make a visible difference casSharpness = 0.3 #dlsSharpness specifies the amount of sharpening in the Denoised Luma Sharpening shader. #Increase to sharpen details within the image. #0.0 less sharp, less artefacts, but not off #1.0 maximum sharp more artefacts dlsSharpness = 0.5 #dlsDenoise specifies the amount of denoising in the Denoised Luma Sharpening shader. #Increase to limit how intensely film grain within the image gets sharpened. #0.0 min #1.0 max dlsDenoise = 0.8 #fxaaQualitySubpix can effect sharpness. #1.00 - upper limit (softer) #0.75 - default amount of filtering #0.50 - lower limit (sharper, less sub-pixel aliasing removal) #0.25 - almost off #0.00 - completely off fxaaQualitySubpix = 0.75 #fxaaQualityEdgeThreshold is the minimum amount of local contrast required to apply algorithm. #0.333 - too little (faster) #0.250 - low quality #0.166 - default #0.125 - high quality #0.063 - overkill (slower) fxaaQualityEdgeThreshold = 0.1 #fxaaQualityEdgeThresholdMin trims the algorithm from processing darks. #0.0833 - upper limit (default, the start of visible unfiltered edges) #0.0625 - high quality (faster) #0.0312 - visible limit (slower) #Special notes: due to the current implementation you #Likely want to set this to zero. #As colors that are mostly not-green #will appear very dark in the green channel! #Tune by looking at mostly non-green content, #then start at zero and increase until aliasing is a problem. fxaaQualityEdgeThresholdMin = 0.0312 #smaaEdgeDetection changes the edge detection shader #luma - default #color - might catch more edges, but is more expensive smaaEdgeDetection = luma #smaaThreshold specifies the threshold or sensitivity to edges #Lowering this value you will be able to detect more edges at the expense of performance. #Range: [0, 0.5] #0.1 is a reasonable value, and allows to catch most visible edges. #0.05 is a rather overkill value, that allows to catch 'em all. smaaThreshold = 0.05 #smaaMaxSearchSteps specifies the maximum steps performed in the horizontal/vertical pattern searches #Range: [0, 112] #4 - low #8 - medium #16 - high #32 - ultra smaaMaxSearchSteps = 32 #smaaMaxSearchStepsDiag specifies the maximum steps performed in the diagonal pattern searches #Range: [0, 20] #0 - low, medium #8 - high #16 - ultra smaaMaxSearchStepsDiag = 16 #smaaCornerRounding specifies how much sharp corners will be rounded #Range: [0, 100] #25 is a reasonable value smaaCornerRounding = 25 #lutFile is the path to the LUT file that will be used #supported are .CUBE files and .png with width == height * height lutFile = "/path/to/lut"
Die Steam-Startparameter des Testspiels ergänzen wir nun ebenfalls um ENABLE_VKBASALT=1, sodass sie so aussehen:
ENABLE_VKBASALT=1 WINE_FULLSCREEN_FSR=1 WINE_FULLSCREEN_FSR_MODE=ultra %command%
Die Home-Taste auf der Tastatur deaktiviert nun vkBasalt, der Effekt sollte deutlich sichtbar sein, nochmal Home aktiviert es wieder. Verschwunden ist das ausgewaschene der Standard-FSR-Hochskalierung.
MangoHud, optional
Wer den Bildunterschieden noch nicht ganz traut kann das ganze mit MangoHud überprüfen. Auch das war bei mir in den Quellen:
sudo xbps-install MangoHud
Die manuelle Installationsanleitung spare ich mir hier, sie ist ausführlich auf der Githubseite erklärt, samt vorkompilierten Releasedateien.
Auch Mangohud will konfiguriert werden. Setze in die $HOME/.config/MangoHud/MangoHud.conf diesen Inhalt:
### MangoHud configuration file ### Display the current GPU information gpu_stats ### Display the current CPU information cpu_stats ### Display FPS and frametime fps frametime ### Display the frametime line graph frame_timing ### Display GameMode / vkBasalt running status vkbasalt ### Display the current resolution resolution ### Disable / hide the hud by default no_display ################ WORKAROUNDS ################# ### Options starting with "gl_*" are for OpenGL ### Specify what to use for getting display size. Options are "viewport", "scissorbox" or disabled. Defaults to using glXQueryDrawable # gl_size_query=viewport ### (Re)bind given framebuffer before MangoHud gets drawn. Helps with Crusader Kings III # gl_bind_framebuffer=0 ### Don't swap origin if using GL_UPPER_LEFT. Helps with Ryujinx # gl_dont_flip=1 ################ INTERACTION ################# ### Change toggle keybinds for the hud & logging # toggle_hud=Shift_R+F12 # toggle_fps_limit=Shift_L+F1 # toggle_logging=Shift_L+F2 # reload_cfg=Shift_L+F4 # upload_log=Shift_L+F3
Das ist fast Standard, aktiviert aber die Optionen zur Erkennung von vkBasalt und der Auflösung. Noch die Startparameter anpassen:
mangohud ENABLE_VKBASALT=1 WINE_FULLSCREEN_FSR=1 WINE_FULLSCREEN_FSR_MODE=ultra %command%
Jetzt erscheint nach Druck auf rechtem Shift + F12 links oben eine Box, die neben den Frametimes und FPS auch die Auflösung anzeigt (was bei aktiviertem FSR also 1920x1080 bzw die Zielauflösung ist, selbst wenn das Spiel intern eine geringere gesetzt hat) und ob vkBasalt an ist. Shift_R + F12 versteckt die Box wieder.
Diskussion der Bildqualität
Wie gut ist jetzt noch das Bild? Ich habe hier mit Metro Exodus ein paar Vergleichsbilder gemacht. Zuerst einmal ist das Ziel die tolle 1080p-Qualität, wobei das nichtmal die hohen Einstellungen sind:

In meiner (recht einfachen) Testszene schwankte mein System hiermit zwischen 70 und 94 FPS.
Mit FSR im Ultra-Modus, also intern 1477x831, sieht das ganze leider viel weniger scharf aus:

Dafür sind die FPS besser, 80 bis 106 FPS sah mein Test. Und das ist die geringste FSR-Stufe, die anderen würden die interne Auflösung weiter verringern und die Performance verbessern.
Und schließlich das Bild mit Ultra-FSR samt vkBasalt:

Das erreicht nicht ganz die Qualität der nativen 1080p-Auflösung. Nicht, dass es nicht ähnlich scharf wäre. Aber FSR produziert eine Abrundung von Linien (gerade im hier nicht sichtbaren HUD) und einen grauen Körnereffekt über dem Bild. Das Schärfen mittels vkBasalt wirkt da leider nicht gegen. Trotzdem wertet vkBasalt das Bild wesentlich auf, die wahrnehmbare Unschärfe ist weg.
Die Performance mit vkBasalt war nur ein bisschen schlechter, die FPS lagen bei 80 bis 100.
Ich wollte hier zum einen FSR mit vkBasalt vorstellen. Gerade die Kombination von FSR mit vkBasalt als Schärfefilter sah ich noch nicht so oft diskutiert, dass Linux hier Spielern eine tolle Tuningoption gibt soll nicht untergehen. Der Umweg über Proton schafft unerwartete Möglichkeiten um Spielen einen gar nicht mal so kleinen Schubs zu geben. Immer noch auf Kosten der Grafikqualität, zugegeben, aber je nach Spielertyp ist es das wert.
Aber mich interessieren besonders auch Fehler in meiner Konfiguration. Gibt es zu vkBasalt sogar gute Alternativen? Wäre bei dessen Einsatz die Kombination der beiden Schärfefilter cas und dls sinnvoll? Sollte FXAA statt SMAA benutzt werden? Ich habe natürlich schon einiges auspobiert, aber bin keineswegs sicher, dass die Konfiguration oben die optimale ist. Nur dass sie ein guter Startpunkt ist, davon bin ich überzeugt.
Als Fazit reizt mich auch der Gedanke, dass dieses jetzt schon interessante Ergebnis die erste Version von FSR nutzt. DLSS 2.0, FSR 2.0 und XeSS sind nochmal deutlich besser. Wenn es irgendwie gelingen würde, sowas wie XeSS auch ohne Entwickleraufwand nutzbar zu machen und dann mit jedem Spiel kombinieren zu können...
DivestOS bei sustaphones
Wednesday, 14. September 2022
DivestOS ist ein Fork von LineageOS. Das Ziel: Gerade auch ältere Telefon mit einem möglichst sicherem Android ausstatten, sodass Nutzer die Kontrolle über ihr System bewahren. Dabei ist ein Fokus auf FOSS Teil der Projektphilosophie, sodass z.B. proprietäre Blobs an vielen Stellen entfernt werden.

Das passt natürlich perfekt zu sustaphones, meinem ROM-Finder für möglichst reparierbare Telefone. Nachdem ich über das ROM las kontaktierte ich daher das Projekt per Reddit. Ergebnis: DivestOS konnte gelistet werden. Der Parser ist zwar etwas komplexer als ideal (weil die Daten nicht in einem Rutsch heruntergeladen werden können), aber es waren doch alle notwendigen Informationen verfügbar – welches Gerät von welcher Version unterstützt wird, wobei bei diesem Projekt auch der Grad der Unterstützung (von "kaputt" bis "getestet, funktioniert") berücksichtigt werden musste.
Die Reihenfolge der Geräte auf der Webseite wird durch die neue Alternative durchaus etwas verändert, obwohl das als Lineage-Fork nicht unbedingt zu erwarten war. Doch werden teils neue Smartphones wie das FP4 offiziell unterstützt, wo bei LineageOS die Unterstützung noch fehlt, und werden einige alte Telefone wie das HTC One (M8) mit einer aktuellen Androidversion versorgt, die von anderen Projekten längst ignoriert werden.
Ich freue mich über das Projekt sowie über die erhaltene Möglichkeit, der Webseite eine weitere Alternative hinzuzufügen.

